当 LLM 作为“交互式代理”与用户多轮互动时,是否能像贝叶斯推断那样,随着新证据不断更新对“世界状态/用户偏好”的概率性信念?Google做了这个研究,以及如何通过训练让模型更接近这种最优更新方式。有兴趣可以搜“Teaching LLMs to reason like Bayesians”来看看。
在个性化推荐等场景里,理想做法是用贝叶斯规则把“先验”在每轮交互后更新为“后验”,再作为下一轮的新先验;但未经专门训练的 LLM 往往会依赖简单启发式(例如默认用户只想要最便宜的选项),而不是从具体用户的选择中推断其独特偏好。
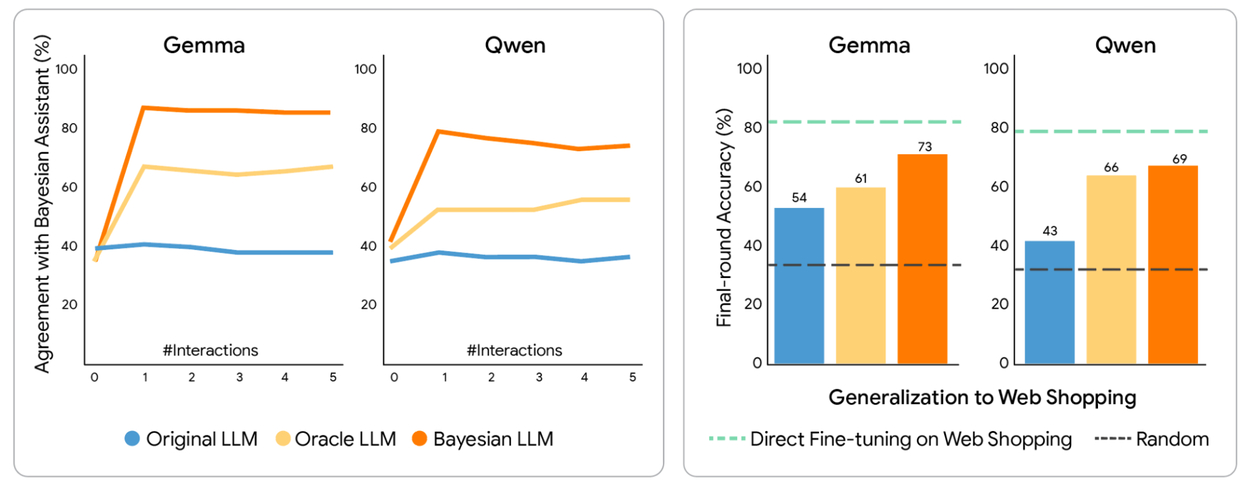
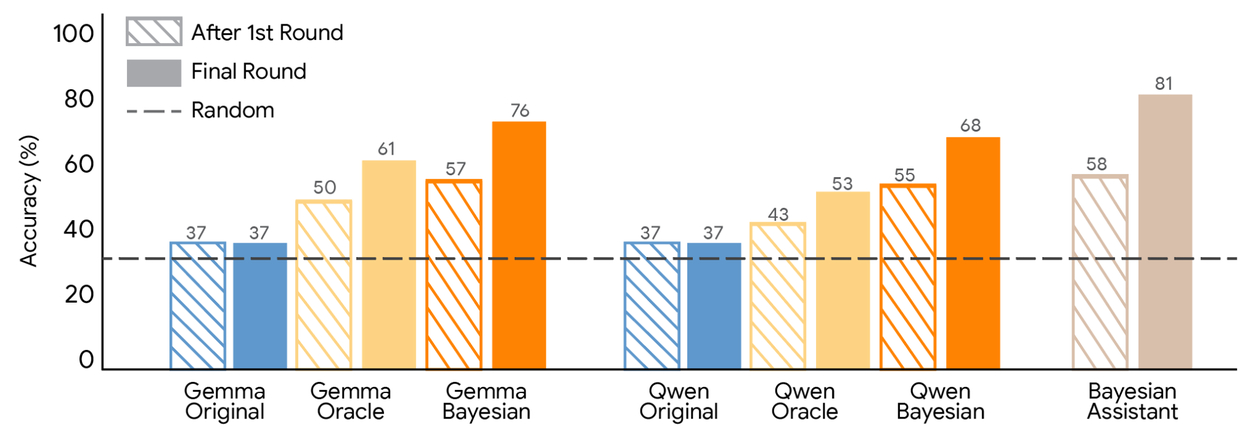
为评估 LLM 的“贝叶斯能力”,Google构造了一个可控的简化任务:五轮“航班推荐”对话。每轮同时展示 3 个航班选项(起飞时间、时长、中转次数、价格等特征),模拟用户具有对各特征“强/弱偏好高/低值或无偏好”的组合。对比对象包括:1)实现了最优贝叶斯策略的“Bayesian Assistant”(维护偏好分布并用贝叶斯规则更新),2)多种开箱即用 LLM,3)人类参与者。结果显示:各类 LLM 明显落后于最优贝叶斯助手;更关键的是,贝叶斯助手会随轮次逐步变准,而许多 LLM 往往在第一轮后就“准确率平台化”,体现出对新增信息的适应不足;人类比大多数 LLM 更能随信息累积而提升,但仍达不到最优贝叶斯策略的水平。
文章提出“Bayesian teaching”的后训练框架:用监督微调让 LLM 学习如何做概率更新。作者比较了两种生成微调数据的方式:一是“Oracle teaching”,给 LLM 看“全知全能的 oracle 助手”与用户的交互(oracle 知道真实偏好,因此总能给出与用户选择一致的正确推荐);二是“Bayesian teaching”,给 LLM 看“Bayesian Assistant”与用户的交互(因为早期不确定性大,助手会出现合理的“猜错”,并在多轮中逐步收敛)。作者假设,模仿贝叶斯助手的“最佳猜测”会比只模仿永远正确的 oracle 更能教会模型保留不确定性、并据证据更新。
实验结果是:两种微调都能显著提升模型表现,但贝叶斯教学在各模型上都更有效;经贝叶斯教学后的模型与贝叶斯助手的决策一致性更高,并且能从合成的航班任务迁移到未见过的推荐域(文中提到如酒店推荐、真实网页购物等),说明学到的不是特定任务套路,而更像可跨域复用的“概率逻辑/信念更新”能力。文章还强调,这种方法等价于把经典的符号化最优策略“蒸馏”进神经网络,从而在难以显式编码贝叶斯策略的真实域里也能受益。HOW I AI