标签: deepseek

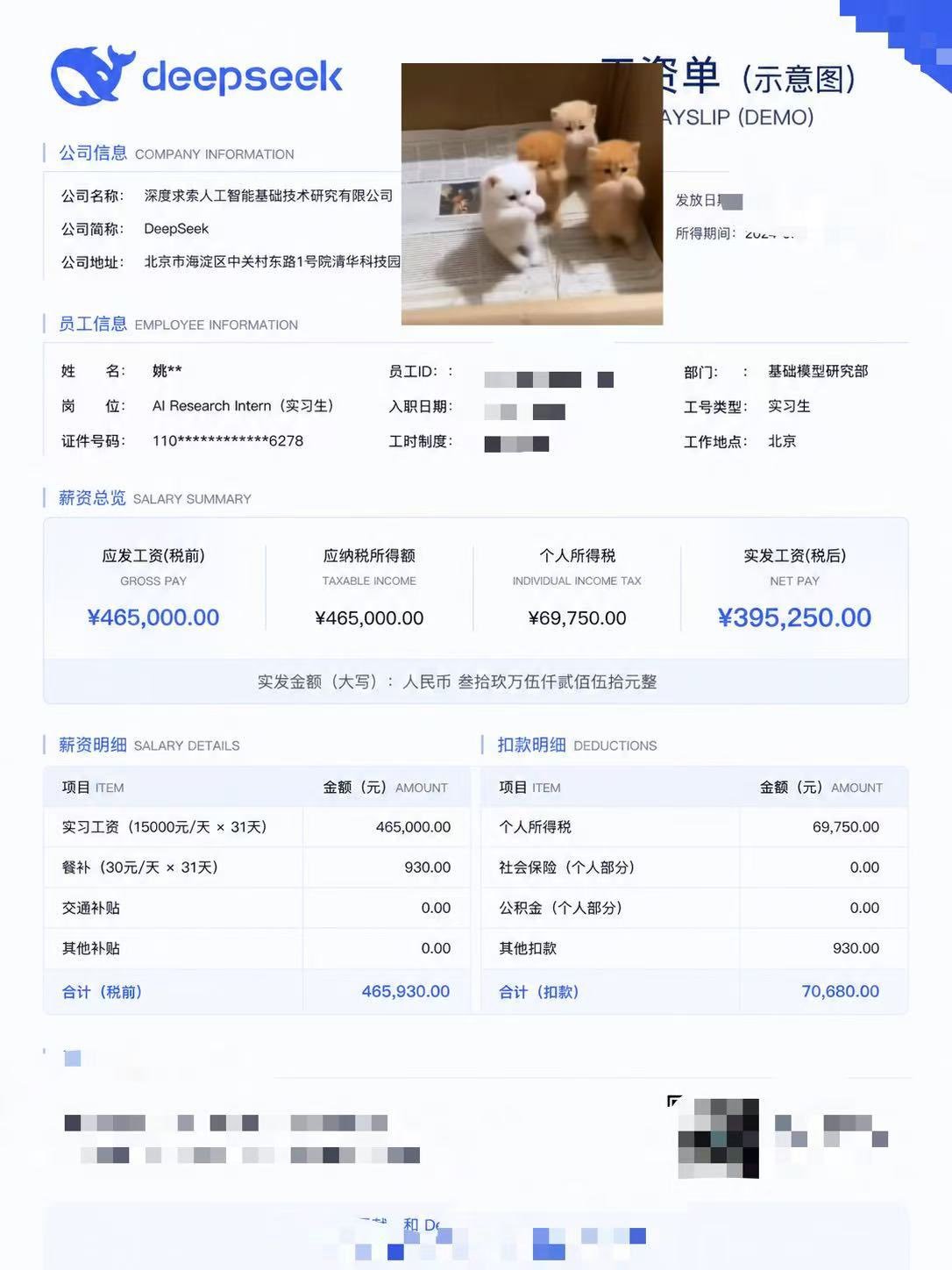



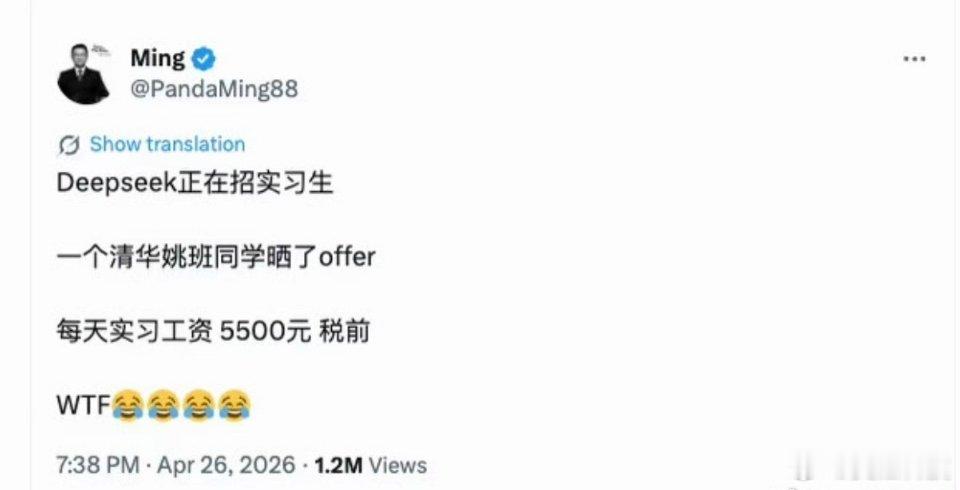


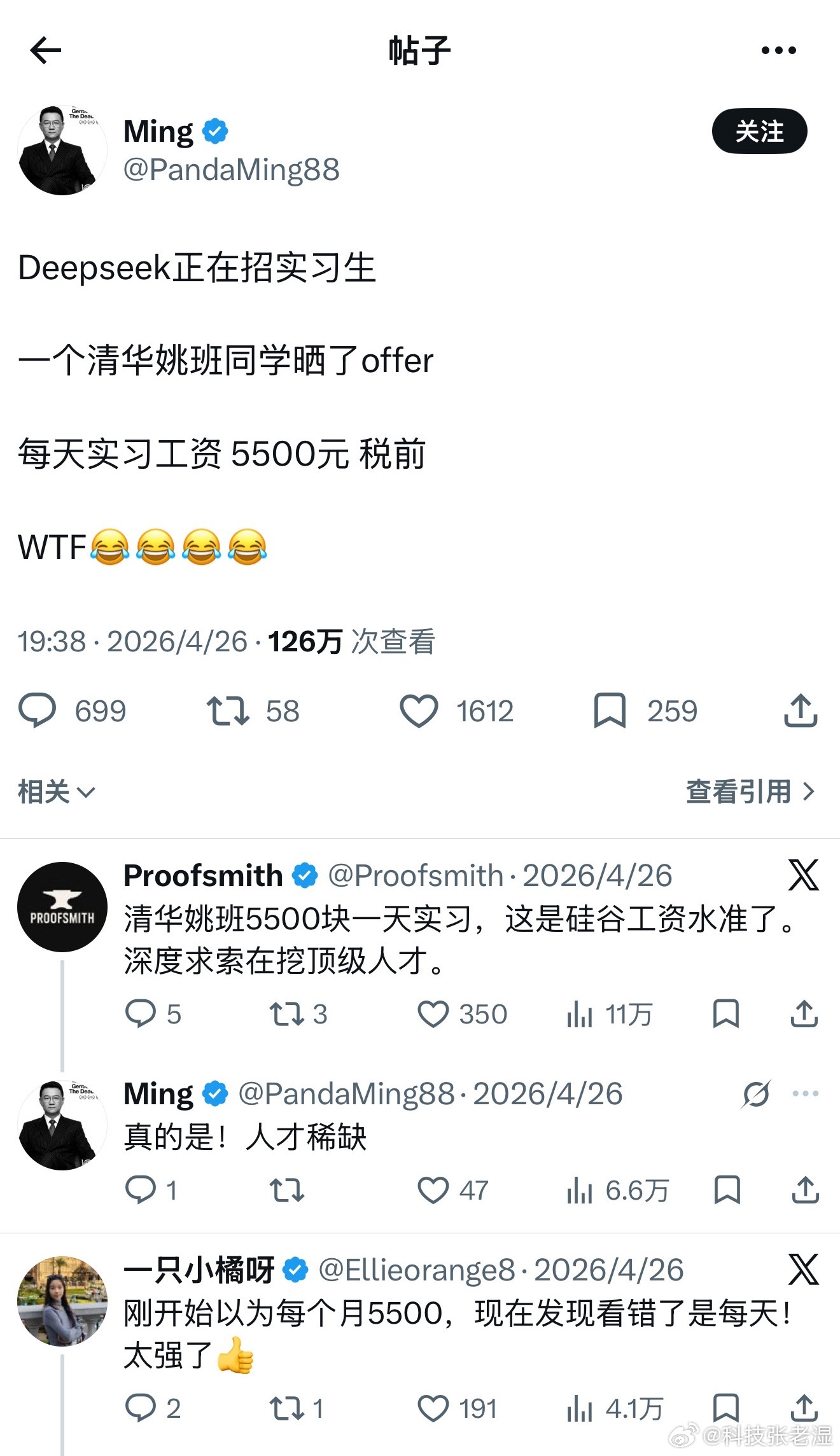
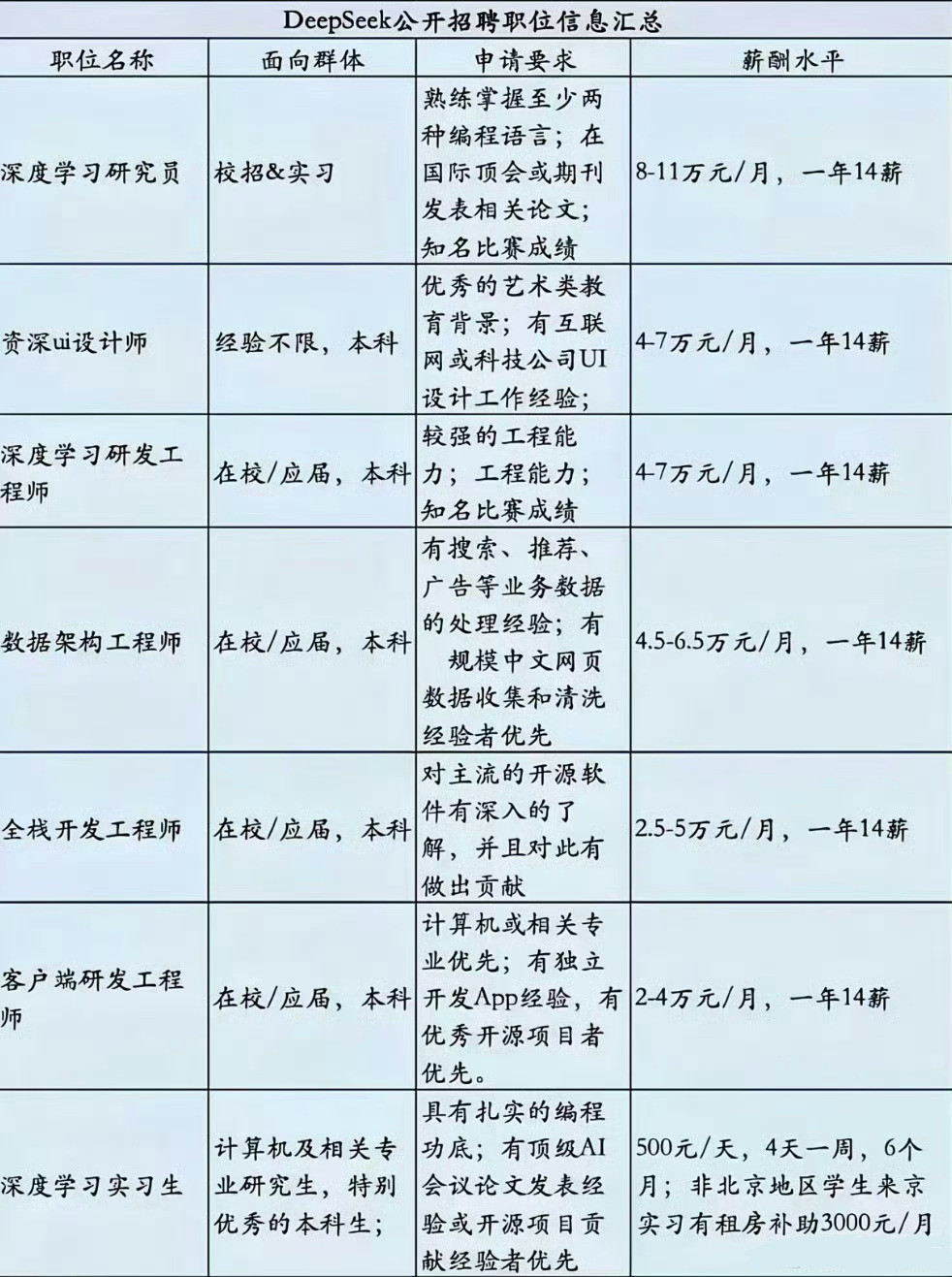
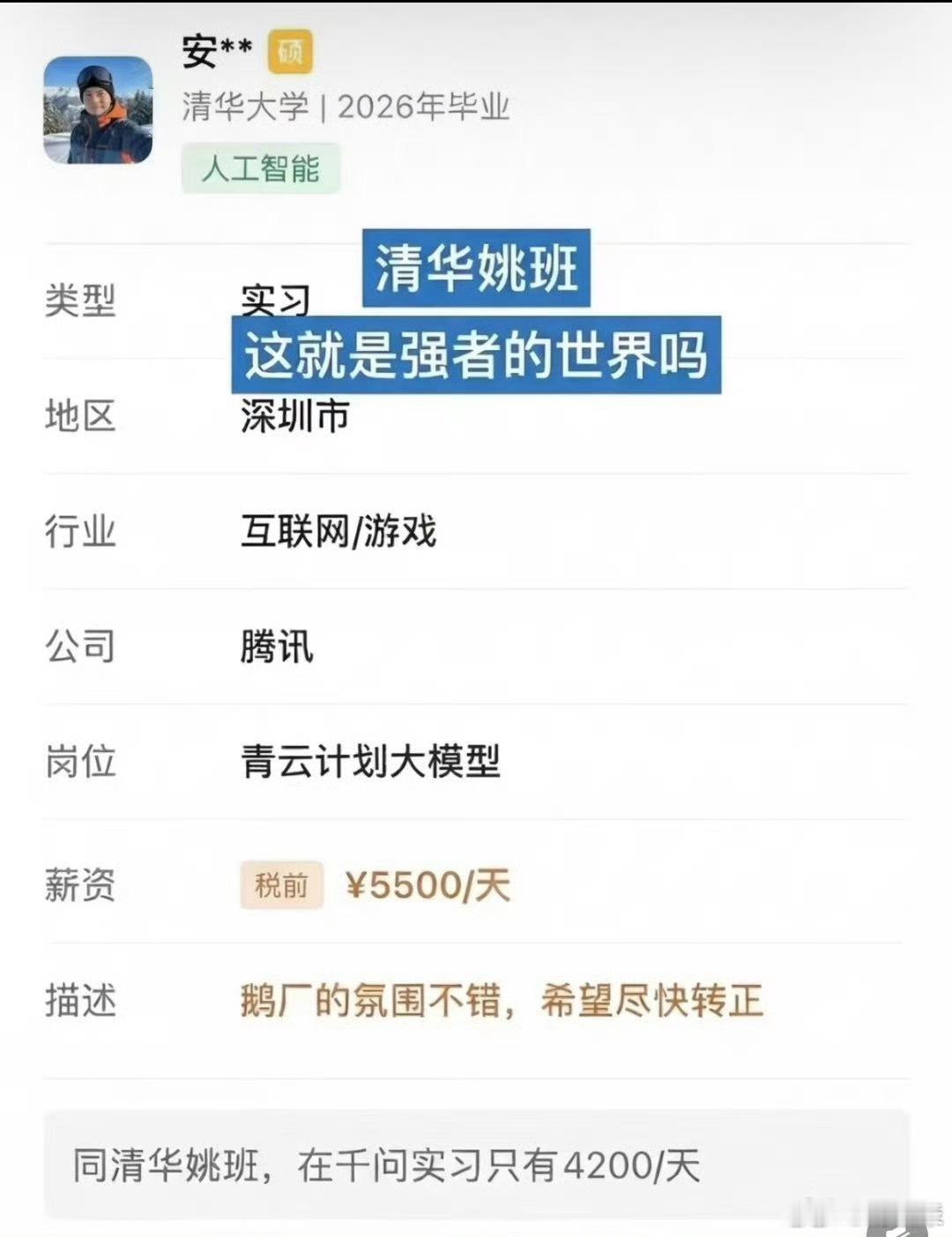

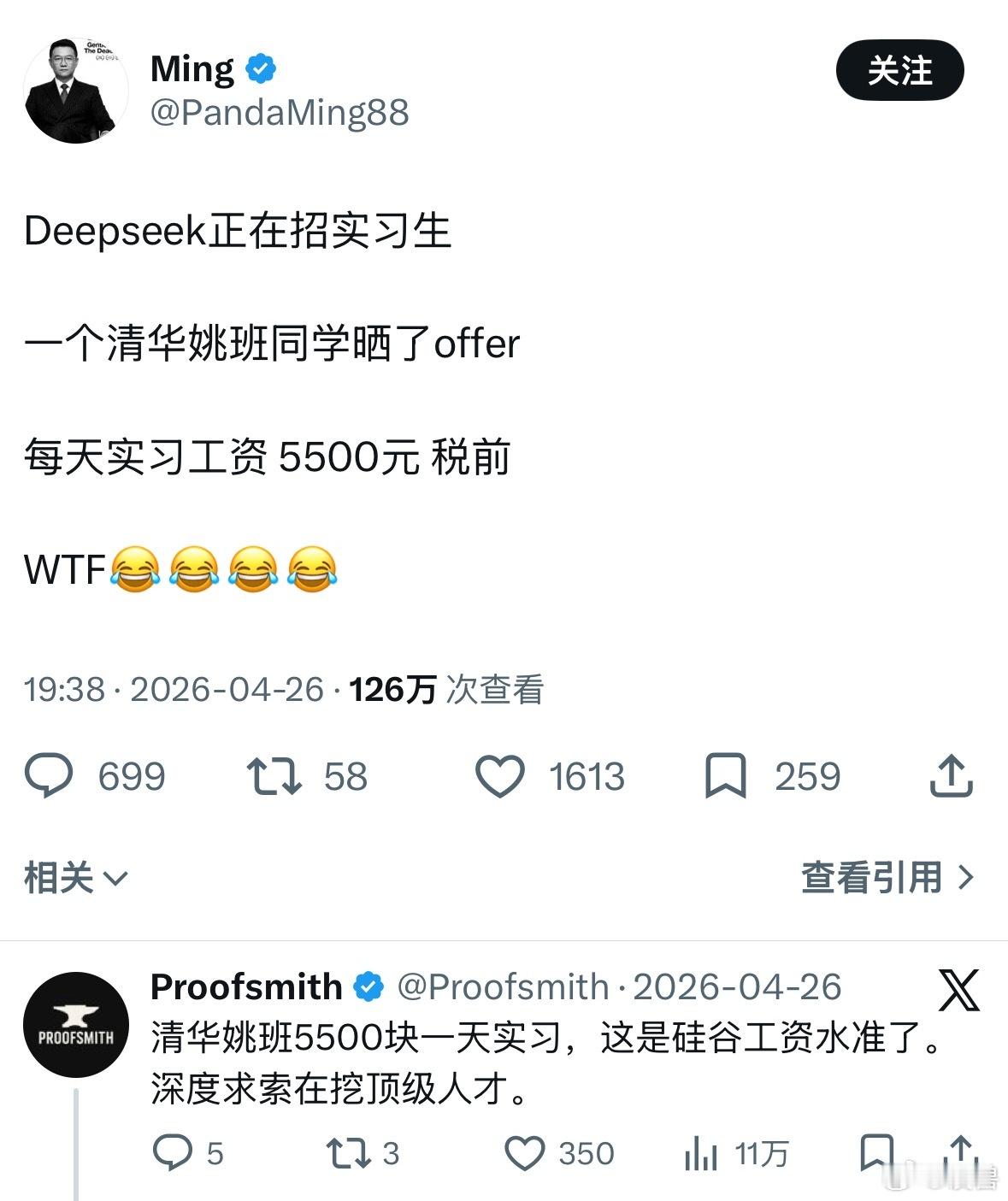
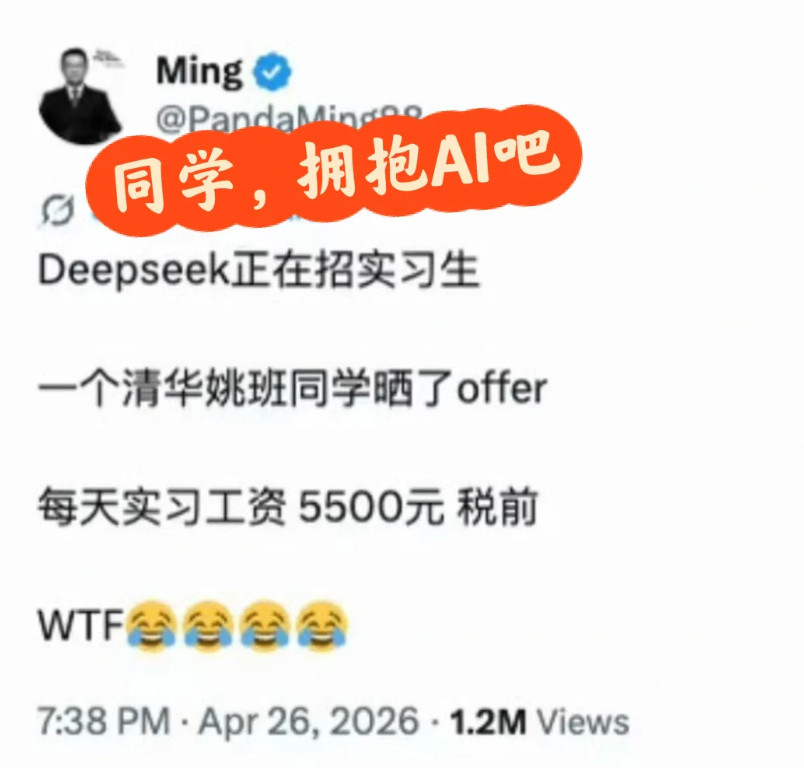
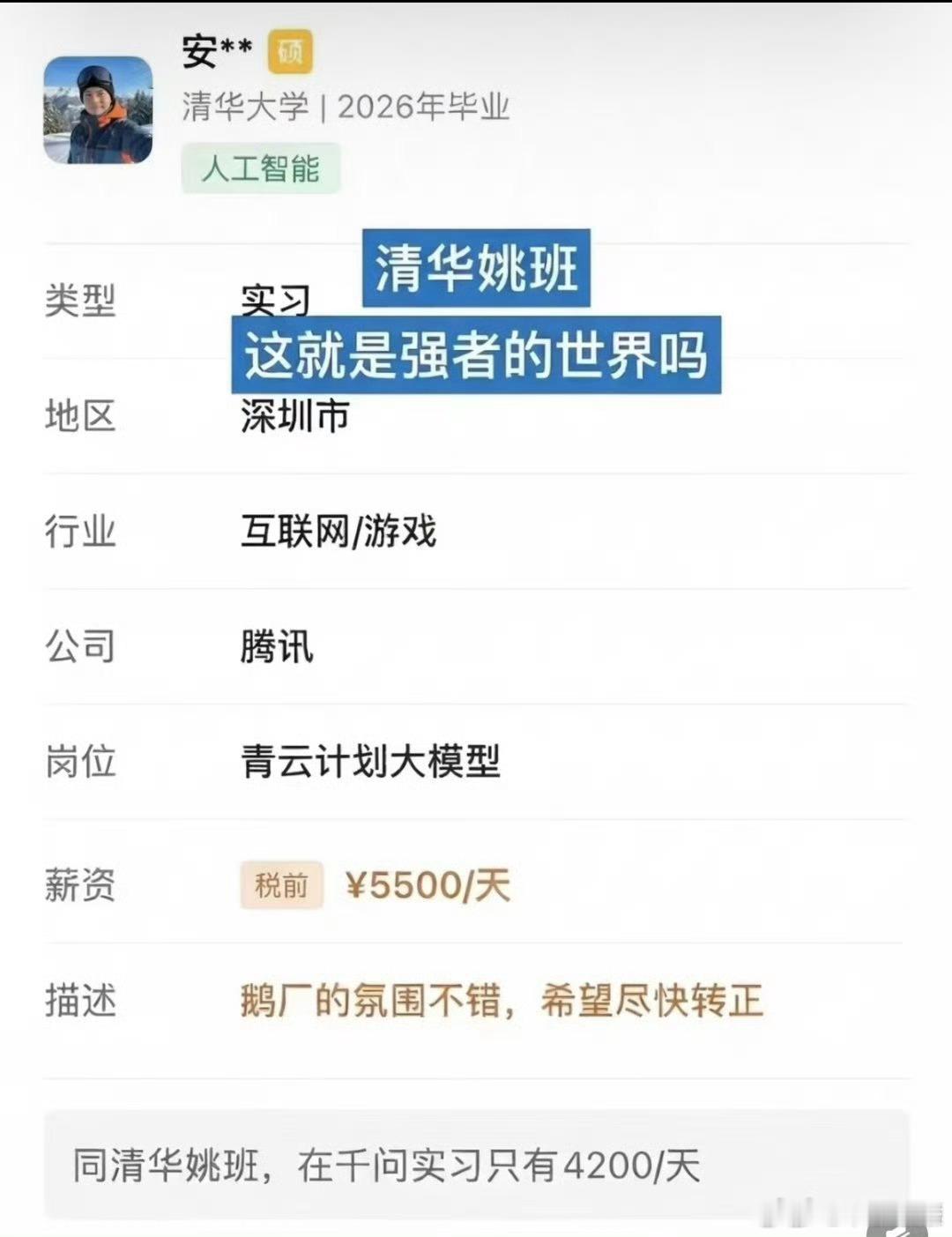
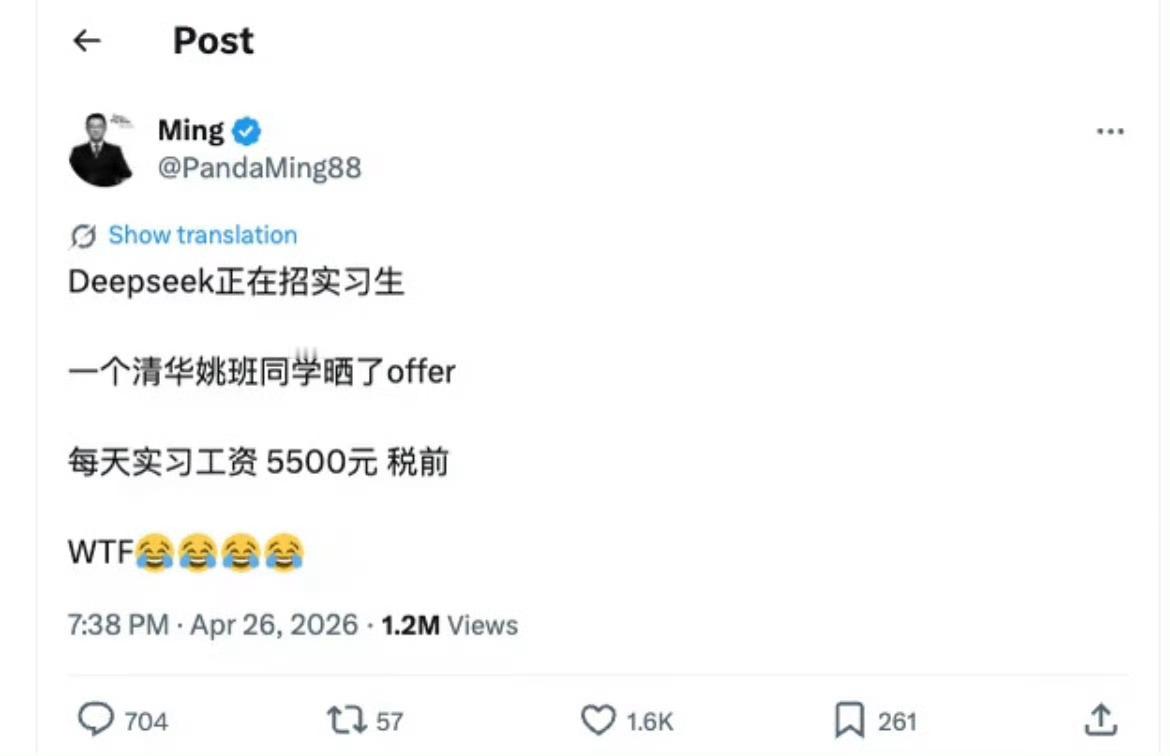
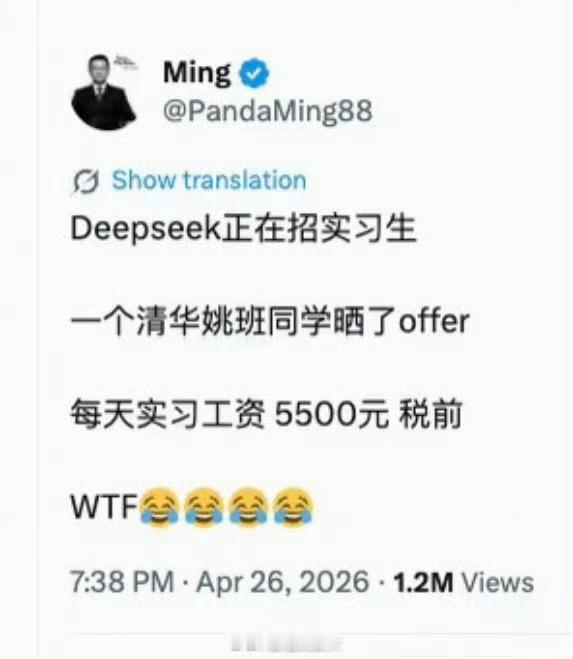


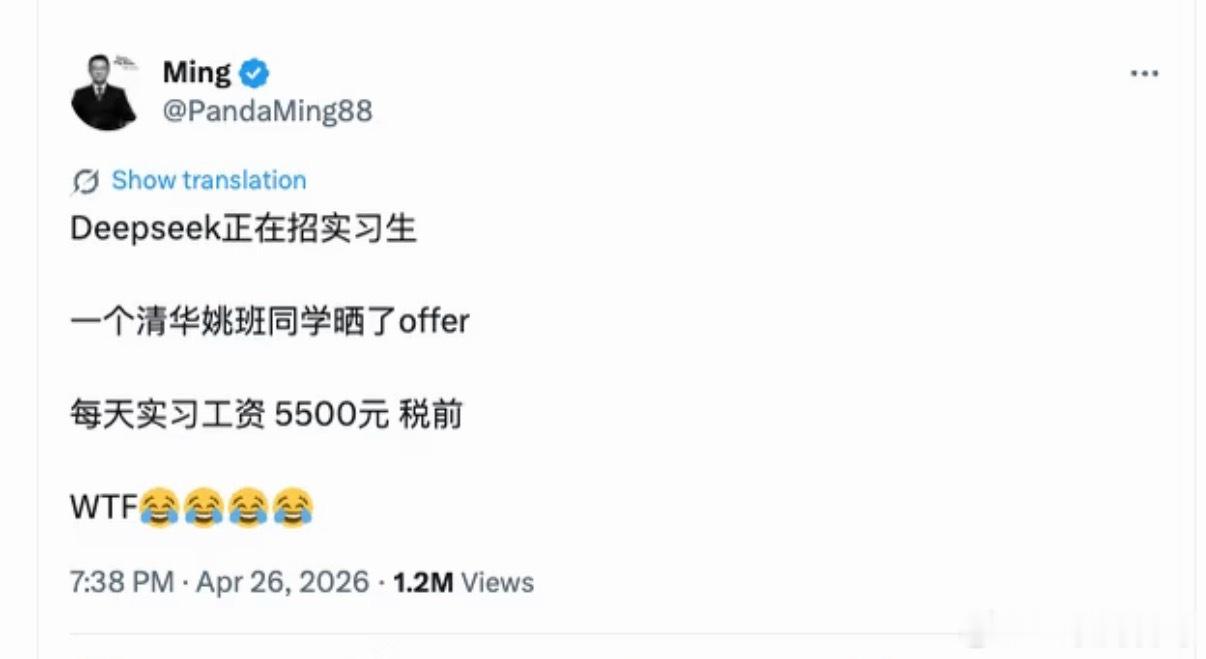
DeepSeek工资待遇太恐怖了低配双子星凯尔特人用首轮第27顺位选中了瑟纳克(
DeepSeek工资待遇太恐怖了低配双子星凯尔特人用首轮第27顺位选中了瑟纳克(12号),次轮第10顺位选中狄龙-米切尔(20号)。


DeepSeek最早或2027年完成上市DeepSeek目标投前估值约为4800
DeepSeek最早或2027年完成上市DeepSeek目标投前估值约为4800亿据彭博社等外媒报道,中国人工智能公司DeepSeek正规划在中国内地上市,目标最快于2026年底或2027年初正式递交IPO申请,力争在2027年完成挂牌上市。公司目前已开始与会计师事务所及投行顾问展开合作,力争在今年12月底前完成财务报告,这是提交IPO申请的必要前置条件。在IPO前,DeepSeek计划通过私募市场至少再募集100亿元人民币,本轮融资的投前估值目标至少为4800亿元人民币(约710亿美元)。相关IPO时间表、融资计划及估值等事宜目前仍在讨论与推进中,最终执行情况将取决于市场环境、财务报告进度及公司业绩表现,存在调整的可能。曝DeepSeek筹备IPO(IT之家)




















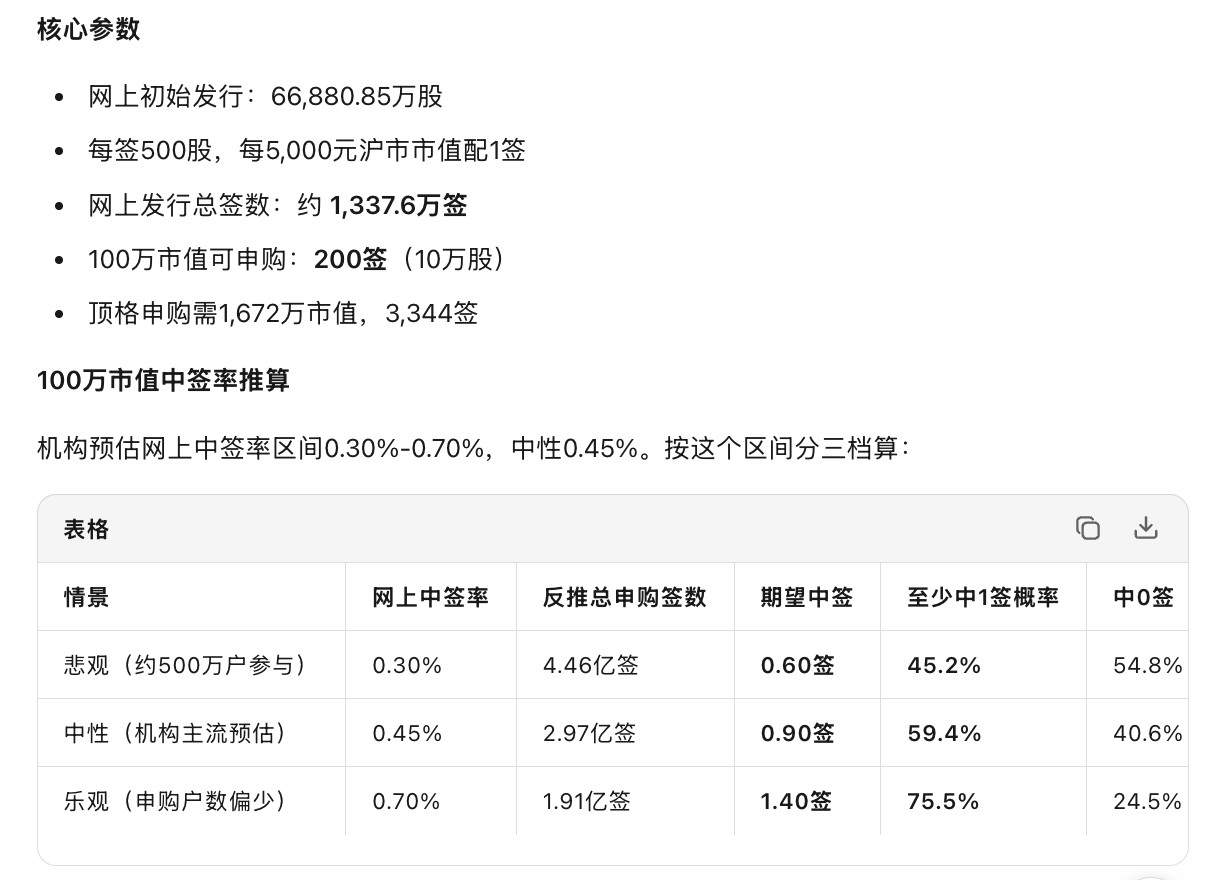






美国完全慌了?!比尔·盖茨曾抛出惊人言论,振聋发聩!他说:“任何说美国持续领先中
美国完全慌了?!比尔·盖茨曾抛出惊人言论,振聋发聩!他说:“任何说美国持续领先中国的说法,都是无稽之谈!”马斯克也立马跟风,称:“中国一直很强大,DeepSeek就是其中之一!”2025年1月,DeepSeek引发美国科技股剧烈震荡,央视新闻报道,美国芯片巨头英伟达当日股价大跌约17%,博通、AMD、微软等也被拖下水。同一天,特朗普也承认DeepSeek给美国相关产业敲响了“警钟”,还说美国企业需要集中精力赢得竞争。这才是最真实的美国反应。嘴上说不怕,资本市场先抖;政客说要赢,说明心里知道已经遇到硬茬。我认为,美国真正害怕的不是某一个中国模型,而是中国背后的系统能力。AI不是光靠几张显卡就能打天下,它要电力、通信、制造、工程师、应用场景和产业链配合。国家能源局数据显示,截至2025年底,中国可再生能源装机总量达到23.4亿千瓦,约占全国电力总装机60%。2026年5月,国家发展改革委、国家能源局、工业和信息化部、国家数据局又印发方案,专门推动人工智能与能源双向赋能,重点就是保障算力设施安全可靠供能、推动算力和电力协同。这一步很重要。以后AI竞争拼到深处,拼的就是谁能用更便宜、更稳定、更绿色的电,把模型持续跑起来。美国有英伟达,有OpenAI,有微软、谷歌,这些优势不能否认。但美国的短板也很明显:一边想维持全球化市场,一边又搞技术围堵;一边希望中国继续买美国芯片,一边又怕中国学会自己造。英伟达黄仁勋2025年在北京就说,中国市场规模庞大且充满活力,中国人工智能发展很快,美国企业扎根中国市场很重要。商人比政客诚实,因为订单不会陪他们演戏。中国市场一旦被美国企业错过,就不是少卖几块芯片那么简单,而是整个生态被国产方案慢慢替代。更深一层看,AI正在改变国际权力的分配方式。过去美国靠美元、航母、芯片、互联网平台一起压阵,很多国家只能接受美国规则。现在中国AI走出一条低成本、开源化、重应用的路,亚非拉国家、中东国家、东盟国家都会多一个选择。新华社今年1月报道,2025年中国AI企业数量超过6000家,核心产业规模预计突破1.2万亿元,国产开源大模型全球累计下载量突破100亿次。这意味着中国不是在做一个“样板工程”,而是在铺一张能被全球使用的技术网络。我一直认为,技术竞争到最后不是比谁会喊口号,而是比谁能让普通工厂、普通企业、普通人用得起、用得顺。美国AI很强,但它的成本太高,商业模式太重,政治包袱也越来越大。中国AI的长处,是能快速落地到制造、物流、教育、医疗、能源、汽车这些真实场景里。人民日报今年4月谈中国AI创新时也提到,中国AI的关键词是性价比和开放度,全球人工智能专利中我国占比已超六成。这不是一天两天撞大运,而是长期积累到某个节点后的集中爆发。所以,“美国彻底慌了”这句话可以当标题,但不能只当热闹看。美国不是怕中国会写几个代码,而是怕中国把AI变成新的工业发动机;不是怕DeepSeek一个产品,而是怕中国形成“模型便宜、算力国产、能源充足、场景丰富、人才够用”的组合拳。美国最擅长在高处筑墙,中国最擅长在地上修路。墙修得再高,也挡不住路越修越宽。中国接下来也不能飘。高端芯片、基础软件、先进传感器、原创算法,短板还在,硬仗还多。但方向已经变了:过去是别人定规则,中国追规则;现在是中国用自己的产业厚度,把新规则一点点做出来。美国越焦虑,越说明这条路走对了。AI时代不是谁先吹哨谁赢,而是谁能坚持把技术变成生产力、把生产力变成国家实力,谁才能笑到最后。


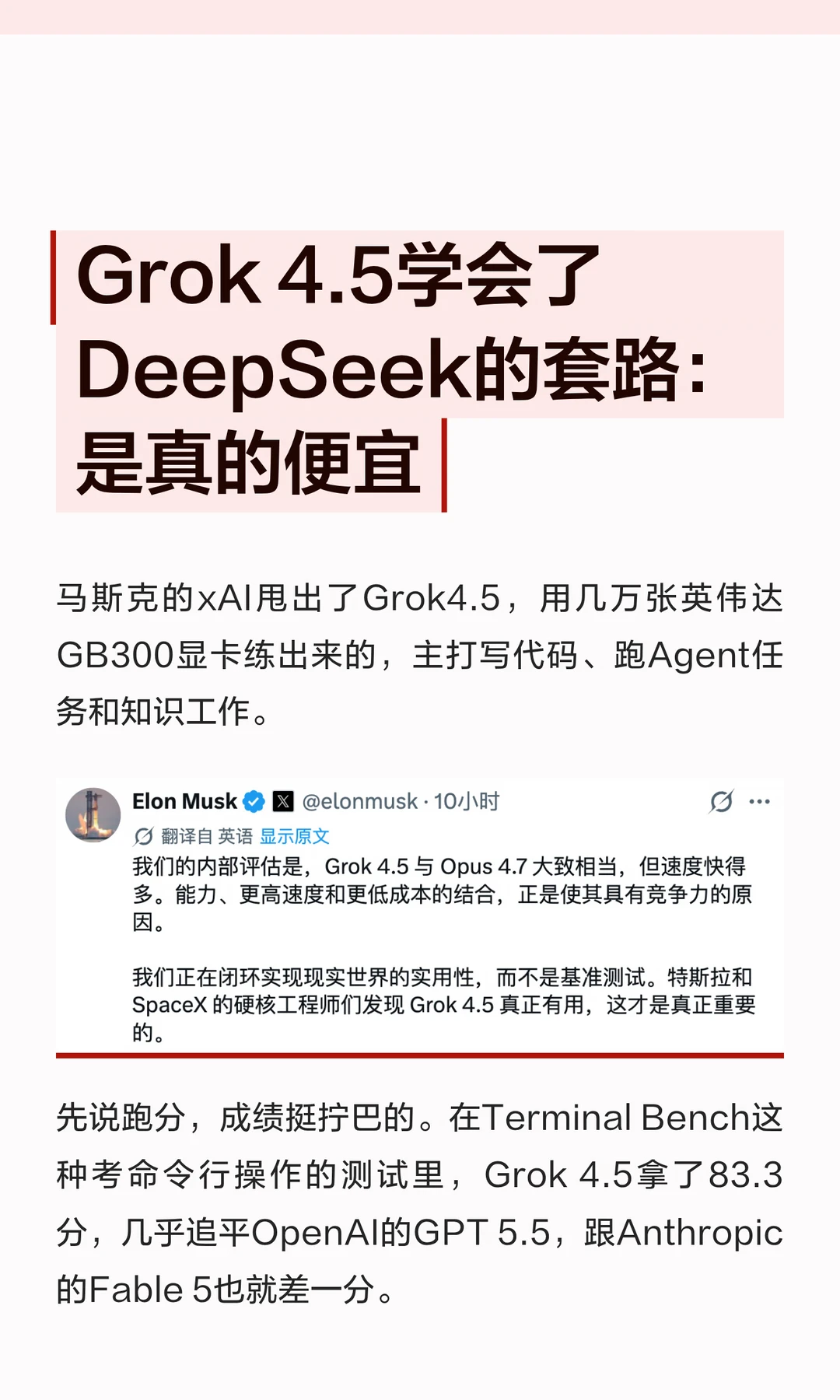

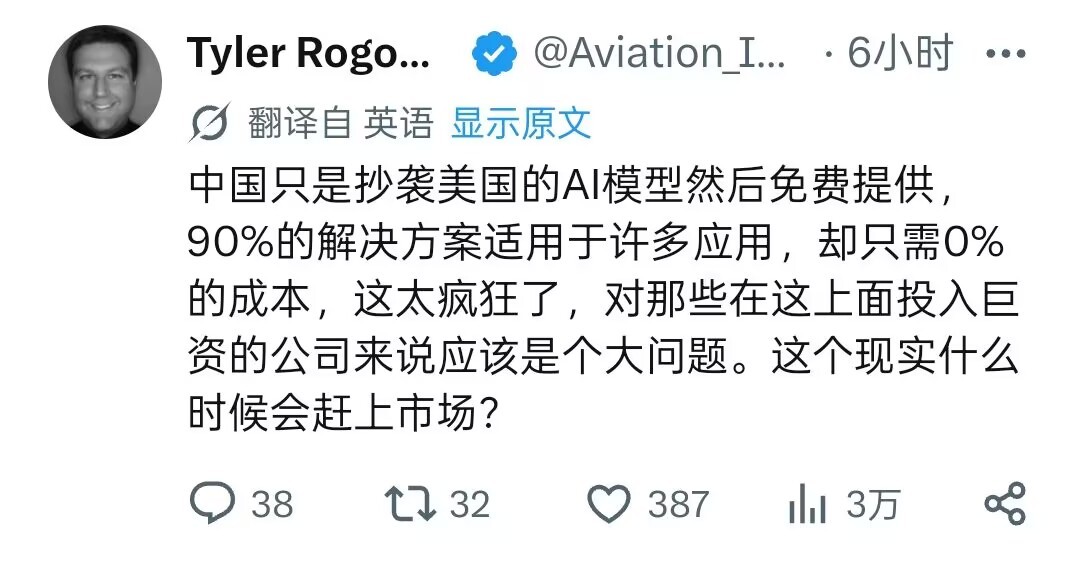










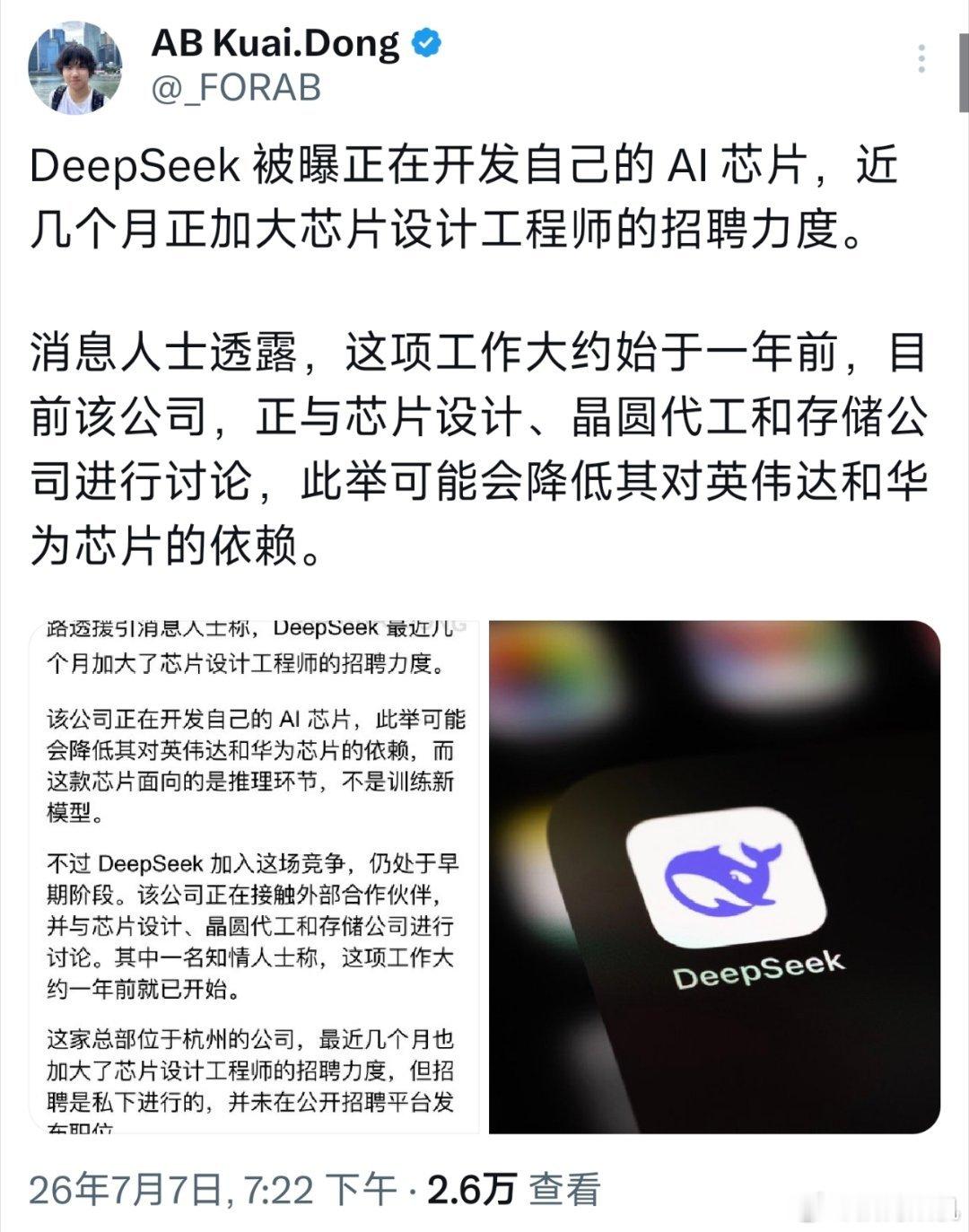


















把DeepSeek+同花顺打通后,炒股盯盘时间减半,收益却翻倍了,建议点赞收藏!
把DeepSeek+同花顺打通后,炒股盯盘时间减半,收益却翻倍了,建议点赞收藏!(
