当视频大模型在 MVBench、VideoMME 等离线基准上越跑越高分,真实交互场景却卡在两个硬问题:如何处理无界的视频流、如何让模型在动态的视频流中决定回答时机。
近期,香港浸会大学联合腾讯优图实验室提出 Streamo,其核心创新在于:将‘何时回答’变成模型要预测的 token,通过端到端训练框架把离线视频模型直接转化为实时流视频助手。Streamo 能够处理真实场景的视频流,支持实时的多指令交互,实现实时解说、动作理解、事件定位、实时问答等不同任务,让 streaming video assistant 真正走向可用。
 论文标题:Streaming Video Instruction Tuning
论文主页:https://jiaerxia.github.io/Streamo/
论文链接:https://github.com/maifoundations/Streamo
论文标题:Streaming Video Instruction Tuning
论文主页:https://jiaerxia.github.io/Streamo/
论文链接:https://github.com/maifoundations/Streamo 1. 问题分析
为什么视频大模型目前还无法成为一个实时的交互助手?虽然视频大语言模型近年来取得了令人瞩目的进展 ——Qwen2-VL、LLaVA-Video 等模型在视频理解、问答、描述等任务上屡创新高。然而,关键的卡点在于这些模型是基于完整视频片段的离线场景设计的,而真实世界的交互需求往往是 "边看边说" 的实时流式场景。
离线视频理解范式假设在推理前可以获取完整视频,模型由此能在全局审视后再输出答案,因此在视频描述、视频问答等任务中表现突出。然而,真实世界的流式场景并不满足这一前提。
视频流本质上是无界的,模型无法 “看到未来”,只能基于当前帧及时做出判断;又因实时性要求,不能等视频播放结束才给出结果,必须在关键事件发生的当下响应。同时,用户指令可能随时到来,模型需要持续监听并在合适的时机触发响应。更复杂的是,不同应用对响应粒度的要求并不一致:有的任务需要帧级的即时叙述,有的则更适合在完整事件结束后再做总结与描述。
现有方法通常通过拆分决策模块来适配流式场景:先由一个模块判断 “是否应该响应”,再调用离线模型生成内容。但这种方案存在明显缺陷:决策模块如果过于轻量,就难以理解复杂指令和跨时间的上下文依赖;如果设计得过于庞大,又会拉高推理延迟,削弱流式交互所需的实时性。更关键的是,决策与生成彼此分离,使模型很难在持续变化的输入中形成连贯、及时的响应。
Streamo 的核心洞察在于:决策与生成不应被拆开,而应统一到同一个端到端框架中,让模型直接学会 “什么时候该说话,以及该说什么”。
2. Streamo:
端到端的决策响应统一架构
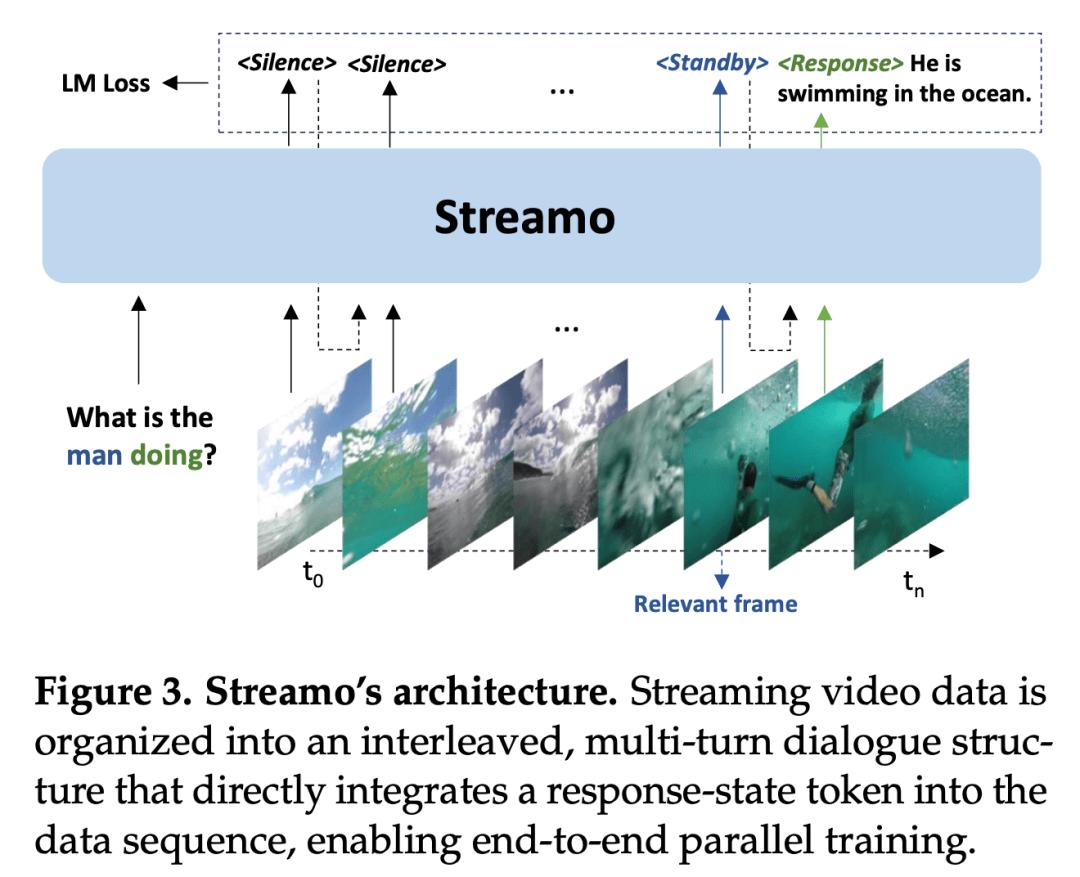
Streamo 的关键设计,是将 “何时回答” 也转化为模型需要预测的 token。具体来说,它将流式视频组织为多轮对话形式:每 1 秒对应一个 turn,视频片段按时间顺序串联,模型在每一轮都要预测一个响应状态,包括Silence、Standby和Response。其中,Silence表示当前画面与任务无关或信息尚不重要,模型继续处理后续输入;Standby表示模型已经捕捉到相关线索,但仍需等待更多上下文以形成完整判断;Response则表示信息已经充分,模型应立即生成输出。
通过这种方式,Streamo 将 “是否响应” 与 “生成什么内容” 统一到同一个 next-token prediction 过程中。也就是说,模型在预测下一个 token 时,不再只是生成文本内容,同时也在完成响应时机的判断。这样一来,决策和生成共享同一语义空间,模型能够在连续变化的视频内容中联合建模时序线索、任务目标与语言输出,从而更自然地学习 “何时该立即回应、何时应继续等待”。
同时,这一设计并不需要额外引入独立的决策头或外部控制器,而是直接将三种状态 token 融入标准的自回归训练框架中。这样既保留了与现有监督微调范式的兼容性,也使训练和推理流程更加简洁高效,便于直接复用现有基础设施进行并行训练和部署。
3. Streamo-Instruct-465K
训练流式助手的核心挑战在于:不同任务对应不同的响应节奏 —— 有的需要秒级实时输出,有的则应等待事件结束后再总结。这意味着训练数据不仅要提供内容监督,还要给出清晰、一致的时间边界,告诉模型什么时候该沉默、什么时候该等待、什么时候该回答。
为此,研究者构建了 Streamo-Instruct-465K。该数据集包含约 46.5 万条指令样本,来源于 135,875 段视频,整合了 ActivityNet、YouCook2、QVHighlight 等多个公开数据源,并在统一协议下重新标注。标注过程采用多阶段自动化流程,结合 Qwen2.5-VL-72B、GLM-4.5 等大模型生成候选描述,再通过一致性过滤与后处理,尽可能保证时间边界准确、文本表达连贯。
在任务设置上,Streamo-Instruct-465K 具有多任务、多粒度的特点。同一段视频可以被标注为不同形式的流式任务,包括实时旁白(Real-time Narration)、事件字幕(Event Caption)、动作字幕(Action Caption)、事件时序定位(Event Grounding)以及时变问答(Time-sensitive QA)。这些任务覆盖了从连续解说到事件总结、从动作级描述到在线定位和动态问答等不同场景。
更重要的是,所有任务都被统一到同一种时间监督框架中:每一轮标注不仅包含文本输出,还明确对应模型当下应处于沉默、等待还是回答状态。这样一来,模型学习的就不只是 “说什么”,还包括 “何时说”,从而具备适应不同流式任务的响应能力。
多任务数据标注演示:
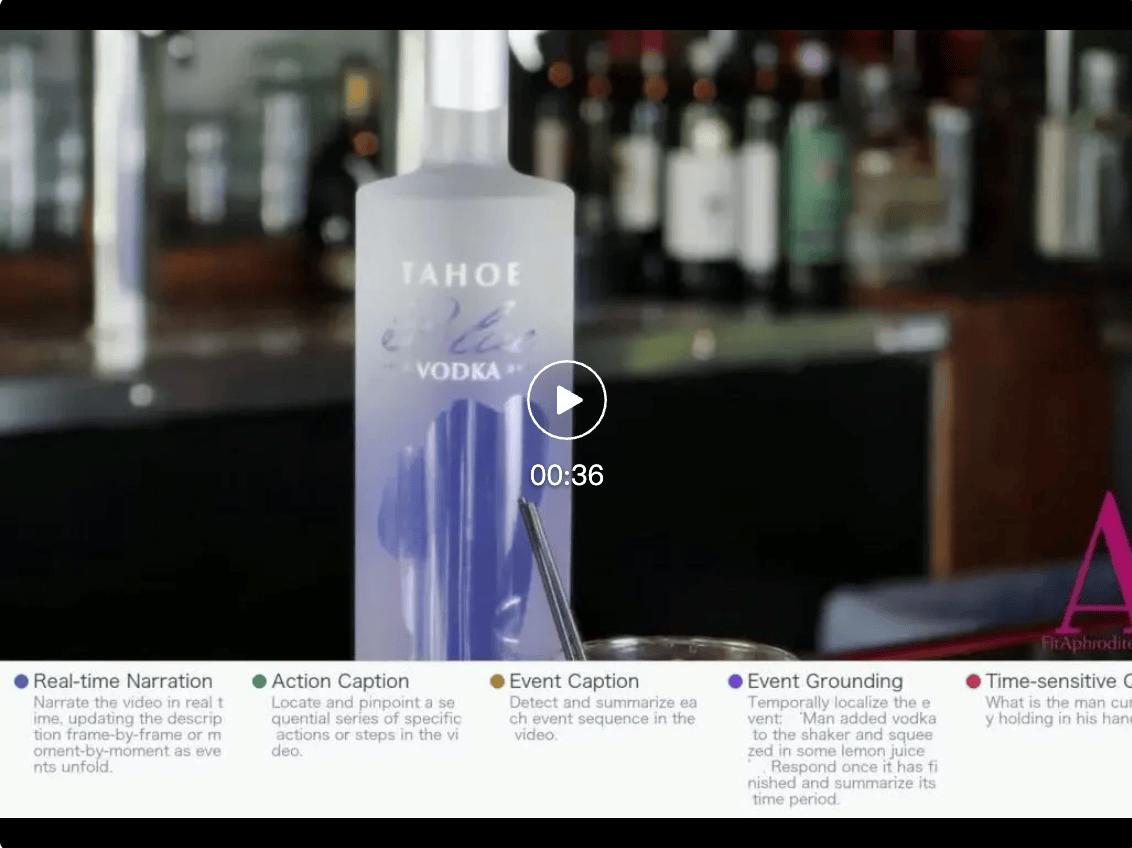
https://mp.weixin.qq.com/s/Q28azqwk-PtsXoep2i0_0Q
对于同一段视频,标注可以随任务目标呈现不同形式:在实时旁白中,模型需要跟随画面持续输出;在事件字幕中,则只在关键事件结束后给出总结;在时变问答中,答案会随着视频进展不断更新。对应地,每个时间点都会标注模型应保持沉默、继续等待,还是立即响应。
4. 实验结果
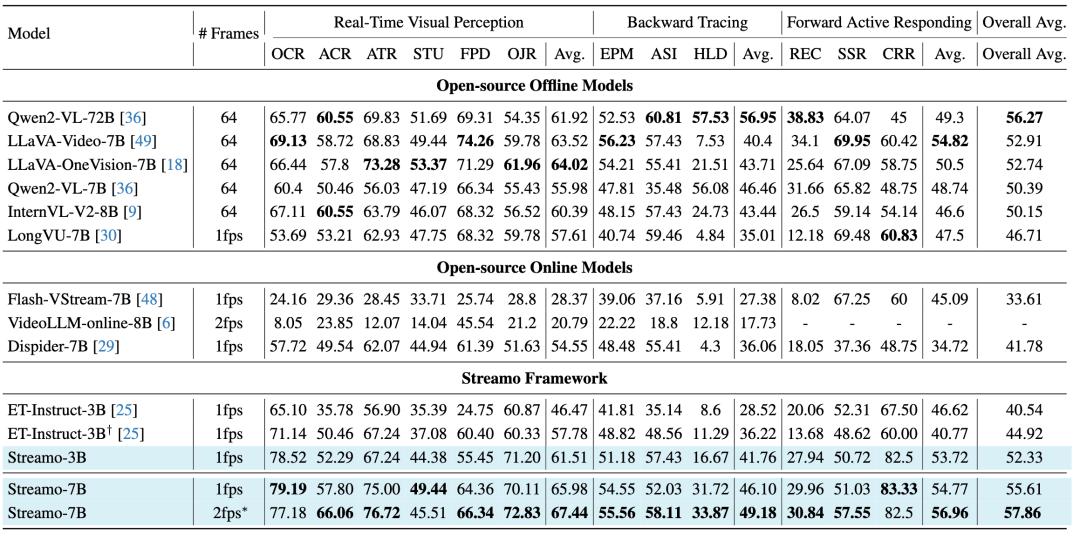
在 OVO-Bench 上,Streamo-7B (2fps) 以 57.86% 的平均性能超越 Dispider 13.83 个百分点。在三大能力维度上全面领先:实时感知能力达到 67.44%(相对 Dispider 的 54.55% 提升 +12.89%);回溯追踪能力达到 49.18%(相对 Dispider 的 36.06% 提升 +13.12%);前向响应能力达到 56.96%(相对 Dispider 的 34.72% 提升 +22.24%)。同时,Streamo 在 1fps 训练的模型可直接在 2fps 下评估,性能提升 4.66%, 展现出强大的泛化能力。
Streamo-Instruct vs 现有数据
Streamo 的性能提升不仅来自训练框架,也高度依赖于高质量的训练数据。与广泛使用的 ET-Instruct-164K 相比,Streamo-Instruct 在 OVO-Bench 上的整体性能提升了 11.79%,在关键的前向主动响应任务上提升了 7.1%,并且避免了混合离线数据(如 LLaVA-Video)所带来的 “在线能力退化” 问题。
实验进一步揭示了一个重要现象:直接混合离线数据可能会削弱模型的在线能力。例如,ET-Instruct 与 LLaVA-Video 结合后,虽然实时感知能力有所提升,但前向响应表现反而下降。这表明,离线监督范式与流式学习目标之间存在一定冲突。相比之下,Streamo-Instruct 通过专门设计的流式标注与统一的时间监督,有效避免了这一问题。
5. 结论
实现真正的实时多模态助手(直播理解、智能驾驶提醒、安防巡检、运动教学等),最难的往往不是 "答对",而是在合适的时间点做合适的输出。Streamo 不仅解决了当前视频大模型的关键瓶颈,提供了一个可复用的技术路线来将静态感知模型转换为动态交互智能体,同时提供了一个统一时间标注的大规模流视频指令数据,推动流视频理解的发展。
6. Demo

https://mp.weixin.qq.com/s/Q28azqwk-PtsXoep2i0_0Q
该 demo 展示了流视频模型在连续视频输入下的实时理解与响应能力。模型能够随画面进展动态决定何时沉默、何时等待、何时回答,在保证时效性的同时提升响应的准确性与连贯性。对于尚无明确答案的问题,模型会等待更多信息后再作答;对于答案随时间变化的问题,模型能够持续更新输出;同时,它还支持基于历史视频内容的回溯式问答。
作者介绍:
本文第一作者为香港浸会大学计算机系博士生夏佳尔,主要研究方向为多模态大模型,包括多模态思考,流视频理解与交互,以第一作者在CVPR,ICCV,AAAI等顶级会议发表多篇文章。导师为香港浸会大学计算机系周锴阳助理教授。