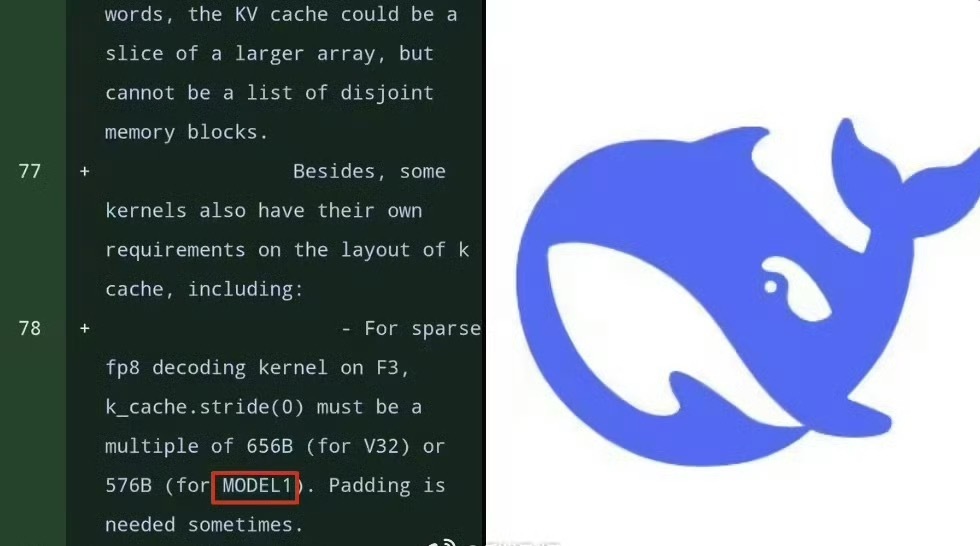
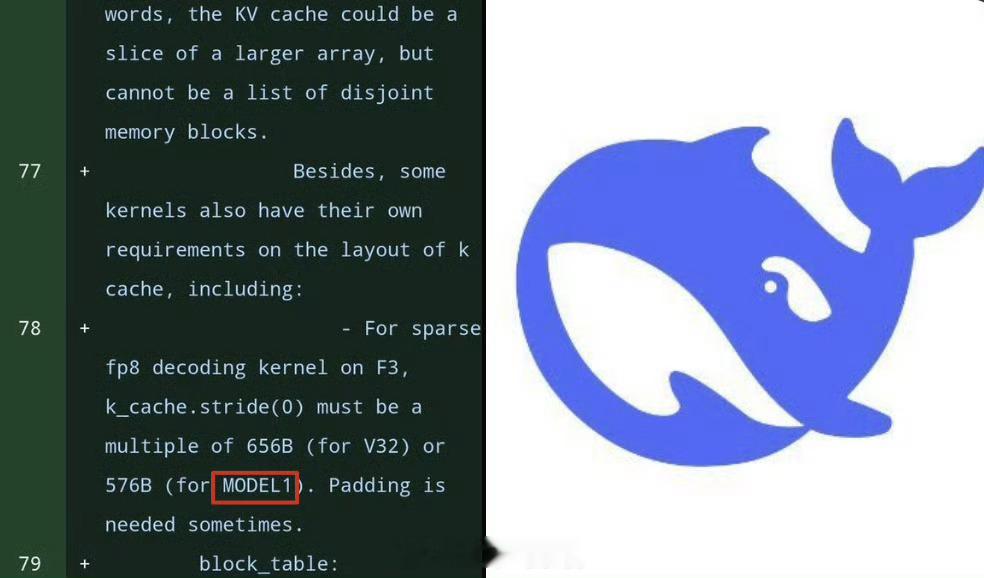
想了解DeepSeek下一代AI模型的真实实力?GitHub代码库的意外更新泄露了关键线索。在FlashMLA优化库的114个文件中,28处代码明确标注着与现有V3.2架构完全平行的"MODEL1"标识,这个神秘代号背后藏着三项颠覆性技术革新。

KV缓存重构:长文本处理的秘密武器代码对比显示,MODEL1彻底重构了键值(KV)缓存布局。不同于V3.2采用的576维设计,新架构将head_dim参数锁定为512维,这种标准化处理能完美匹配英伟达GPU的TensorCore计算特性。更值得注意的是,测试脚本中出现的test_flash_mla_sparse_decoding表明,MODEL1实现了Token级稀疏计算能力,这意味着处理超长文档时,系统能自动忽略次要信息,显存占用有望降低50%以上。
FP8解码:内存优化的化学式反应在精度支持方面,MODEL1新增了对FP8数据格式的完整解码链。这种仅有8位浮点精度的创新方案,相比传统FP16格式可减少40%的内存占用。代码中特别标注的SM100架构(英伟达Blackwell B200)专用接口显示,当运行在下一代GPU上时,MODEL1的稀疏算子算力利用率可达350TFlops,这相当于在相同硬件条件下,推理速度比V3.2提升1.8倍。
生物启发的记忆模块:Engram技术落地DeepSeek此前论文披露的"AI记忆模块(Engram)"在MODEL1代码中首次现出真身。该技术模仿人类大脑记忆机制,通过优化残差连接(mHC)实现知识的高效存储与检索。具体表现为:当模型处理16K以上长序列时,关键信息留存率提升37%,这在代码分析、学术文献处理等场景中将带来质的飞跃。

技术社区普遍认为,这些改进直指当前大模型的两大痛点:内存墙问题和长上下文理解瓶颈。从代码提交时间节点看,DeepSeek极可能在2026年春节前后发布搭载MODEL1架构的V4版本。届时,开发者将能验证这些纸上谈兵的技术指标,是否真能改写AI推理的效率规则。