ETL 工具是企业数据集成和治理落地的核心支撑,负责数据的抽取、转换、加载,直接决定数据链路的稳定性、效率与复用性。
市面上 ETL 工具那么多,功能侧重、技术架构、适用场景之间差异很大,到底应该怎么选?
用过来人的经验告诉你,ETL 工具没有绝对的优劣,就看是不是适配你的业务需求。今天带大家盘点一下市面上10 款主流的ETL工具,从功能到优缺点都给你讲清楚。

一、选型核心考量维度
我一直强调,选型前的需求梳理比工具测评更重要,把这5个核心问题想清楚,怎么选就清楚明白了。
业务适配:明确你的数据类型、处理时效要求、处理数据的量级
技术能力:重点看数据源兼容性、转换灵活性、调度稳定性、扩展性
易用性:可视化程度、低代码支持、学习曲线,这关系到团队上手速度和日常数据处理的效率。
成本:除了授权费,还包括实施、运维、培训的隐形成本都要考虑。
安全合规:数据加密、权限管理、国产化适配(信创要求),尤其金融、政务行业不能忽视。
生态与支持:社区活跃度、厂商技术支持,遇到问题要能快速解决。
二、10款主流ETL工具深度测评
1. FineDataLink
定位:国产数据集成与治理一体化平台,主打低代码和易用性。
核心功能:
实时与离线双引擎,支持高并发实时数据同步和批量ETL/ELT定时计算,毫秒级数据同步能力在大数据场景下表现稳定,还支持表结构变更同步、断点续传等,不用担心数据处理过程中出现网络中断、数据源故障等情况。

低代码可视化开发,通过简单拖拽就能处理好数据,简单易懂,直接上手可用,极大地降低了技术和工具的学习成本;

多源数据采集,支持关系型、非关系型、接口、文件等多种数据源,能满足不同业务场景下的数据处理需求;

全流程数据治理,包含元数据自动采集、端到端数据血缘追踪、多维度数据质量监控、细粒度权限控制与操作审计,满足等保合规要求;
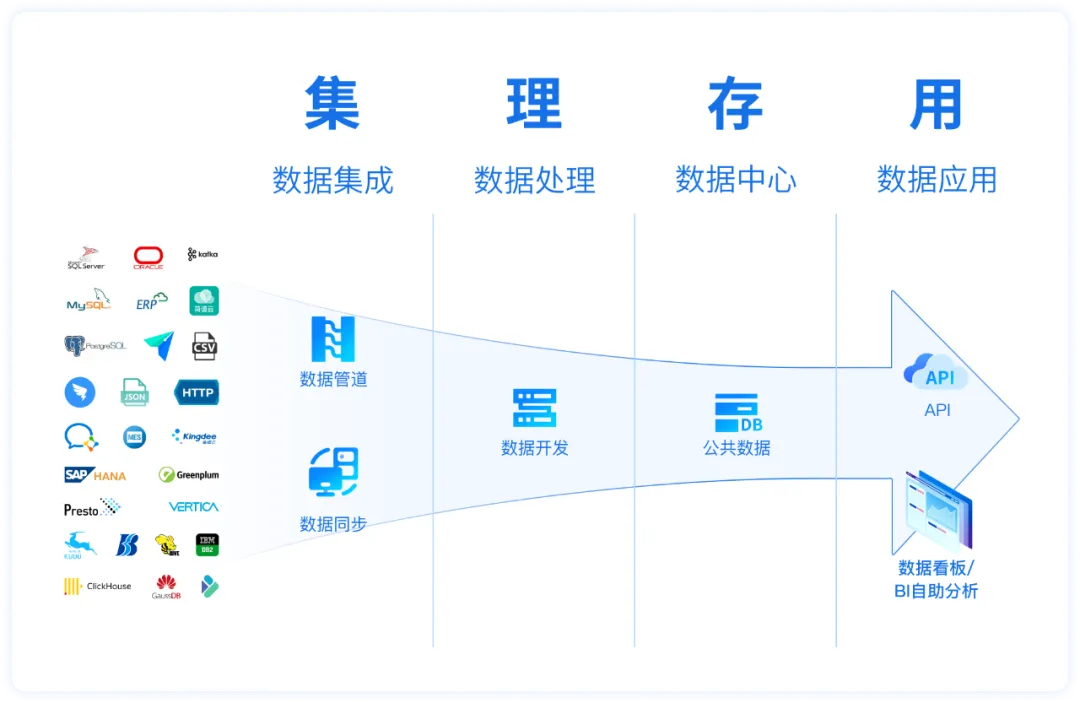
完善的任务调度和监控,管理和监控ETL任务的执行,包括调度任务的执行时间、任务失败时的错误处理以及实时监控任务执行状态等功能,及时发现和解决潜在问题。

不足:免费版仅支持基础数据源与同步功能,生产级场景需升级企业版;特殊需求和复杂逻辑需要二次开发,但大部分数据场景基本都能覆盖
适用场景:国产化替代项目、中大型企业数仓建设、政务及金融机构、追求快速落地的数据治理需求。
2. Microsoft SQL Server Integration Services(SSIS)
定位:微软生态专属ETL工具,与SQL Server数据库深度绑定。
核心功能:
内置丰富的数据转换组件和任务模板;
与Visual Studio开发环境无缝集成;
通过SQL Server Agent实现成熟的调度和依赖管理;
支持增量同步和数据清洗规则配置。

不足:跨平台支持差,非Windows环境部署困难;处理PB级大数据时性能受限;对非微软数据源兼容性一般。
适用场景:以SQL Server为核心数据库的企业、微软技术栈团队、中小企业离线数据集成。
3. Informatica PowerCenter
定位:国际老牌企业级ETL工具,金融、电信行业首选的合规型平台。
核心功能:
支持复杂数据转换逻辑,处理结构化和半结构化数据能力强;
元数据管理完善,数据全生命周期可追溯;
安全合规功能全面,满足金融级数据加密和审计要求;
支持分布式部署和大规模并行处理。

不足:价格昂贵,中小企业难以承受;实施复杂,部署周期长;技术架构相对封闭,与新兴技术集成难度大。
适用场景:大型金融/电信企业、复杂业务逻辑场景、对合规性要求极高的项目。
4. IBM DataStage
定位:大型企业级ETL工具,并行处理能力突出的传统数据仓库解决方案。
核心功能:
支持大规模并行处理架构,处理TB级数据效率高;
与IBM生态系统(DB2、WebSphere)集成紧密;
企业级调度和监控功能完善;
支持复杂业务规则的可视化编排。

不足:学习成本高,配置复杂;灵活性不足,自定义需求实现难度大;对云原生环境适配较慢。
适用场景:采用IBM技术栈的大型企业、大型数据仓库建设、复杂业务逻辑处理场景。
5. Kettle(PDI)
定位:开源ETL工具中的经典,拥有庞大的用户群体。
核心功能:
完全免费开源,可视化拖拽流程设计;
插件生态丰富,支持多种数据源连接;
支持数据清洗、转换、加载全流程;
社区资源丰富,有大量现成模板。

不足:处理TB级以上数据时性能瓶颈明显;实时处理能力弱;集群部署复杂,运维成本高。
适用场景:中小企业、预算有限的团队、简单ETL任务、数据迁移项目。
6. Talend
定位:Qlik旗下开源转商业的云原生数据集成工具,连接器生态丰富。
核心功能:
提供超多预构建组件和连接器,支持本地、云端及混合云部署;
强化数据质量与治理能力,适配Snowflake等云数仓;
支持实时和批量数据处理,支持JSON、XML等半结构化数据传输。

不足:学习曲线较陡,新手掌握复杂配置需要时间;开源版功能受限,复杂场景需升级企业版;超大规模数据处理性能有待提升。
适用场景:中大型企业云架构数据集成、多源异构数据整合、重视数据治理的跨国企业。
7. Airbyte
定位:轻量级开源ETL工具,以模块化和丰富连接器快速崛起。
核心功能:
支持海量数据源连接器,可通过Docker快速部署;
低代码配置界面,上手门槛低;
支持增量同步和数据同步状态监控;
可与Airflow等调度工具集成。

不足:连接器深度不足,老旧系统和小众数据库支持差;复杂场景需编写自定义脚本;数据追溯和权限管理功能薄弱;监控报警体系简单。
适用场景:初创公司、小团队、轻量级数据同步、SaaS数据集成、快速原型开发。
8. Apache NiFi
定位:分布式数据流处理工具,擅长复杂数据管道编排。
核心功能:
可视化流程编排能力强,支持动态流程调整;
数据流监控完善,支持数据路由、过滤、转换全流程;
具备高扩展性和容错性,支持分布式部署;
元数据与内容分离设计,优化内存占用。

不足:资源消耗大,对服务器配置要求高;学习曲线陡,文档不够完善;复杂计算能力薄弱。
适用场景:IoT数据采集、复杂数据治理场景、大规模数据流调度、跨系统数据协同。
9. AWS Glue
定位:AWS云原生无服务器ETL工具,专为云上数据生态设计。
核心功能:
无服务器架构,自动弹性扩展,无需关注底层运维;
与S3、Redshift等AWS服务深度集成;支持基于ML的数据质量提升功能;
按使用量付费,成本可控;
支持批处理和流式数据处理。

不足:国内网络体验差,访问延迟高;对非AWS生态数据源兼容性一般;跨云部署能力弱。
适用场景:AWS云原生架构企业、海外业务、云上数据湖建设、弹性扩展需求的ETL任务。
10. Azure Data Factory
定位:微软Azure生态专属云原生ETL工具,跨区域部署能力突出。
核心功能:
深度适配Azure生态服务,与Power BI联动性强;
支持实时和离线数据集成,断连模式下可正常工作;
低代码可视化设计,支持复杂数据流程编排;
支持跨区域部署和数据同步。
不足:跨云集成能力弱,非Azure用户适配成本高;部分高级功能需额外付费;对国产数据库支持有限。
适用场景:Azure云生态企业、微软技术栈团队、跨区域数据集成、需与Power BI联动的分析场景。
三、工具总结对比表格

四、常见问题解答
Q1;开源工具和商业工具怎么选?
A:用过来人的经验告诉你,预算有限、技术团队强、任务简单,选开源工具Kettle、Airbyte等;
企业级需求、重视稳定性和支持、有合规要求,还是选FineDataLink、Informatica这些商业工具稳妥,千万别为了省钱选开源工具做核心业务,后期运维成本可能更高。
Q2:国产化项目只能选国产工具吗?
A:不是,但国产工具适配更顺畅。如果信创要求严格,优先选FineDataLink这类完全适配国产软硬件的工具;如果只是部分国产化,Talend等海外工具也能满足基础需求,但要提前做兼容性测试,避免后期返工。
Q3:云原生工具和本地部署工具怎么选?
A:主要看你的IT 架构,如果已经上云且主要用单一云厂商生态,可以选对应云原生工具AWS Glue、Azure Data Factory,这些工具集成成本低、运维省心;但如果是混合云或本地架构,更推荐多部署模式的工具像FineDataLink、Talend等,避免后期迁云或扩本地时二次替换。用过来人的经验告诉你,不要盲目追云原生的热潮,如果你所在地区网络不稳定,本地部署的工具稳定性反而更有保障。
工具选型的核心是适配,匹配业务需求、技术栈和预算。如果你的企业有具体场景或疑问,欢迎随时交流,帮你精准推荐。

![这是哪个程序员兄弟转行了[捂脸哭]AI编程末日,只有我会古法编程古法C](http://image.uczzd.cn/18014632997101618166.jpg?id=0)


