最近能够和人隔网对拉网球的机器人,据说也要出现了。隔着球网要通过传感器感知,并判断对面人类打过来的球,它的速度,位置,旋转,甚至增加温度和风速的信息,判断弹跳,进行回球的决策。
这很难,因为它非常考验机器人对于真实物理世界的理解。3 月 17 日 2026GTC 大会上,理想汽车基座模型负责人詹锟发布下一代自动驾驶基础模型 MindVLA-o1,这款模型的亮相直接打破了自动驾驶与物理世界 AI 的技术边界,也让理想对物理 AI 的布局清晰落地 —— 自动驾驶只是起点,同一套 VLA 模型未来将打通车辆与机器人的控制体系,真正实现物理世界 AI 的通用化。
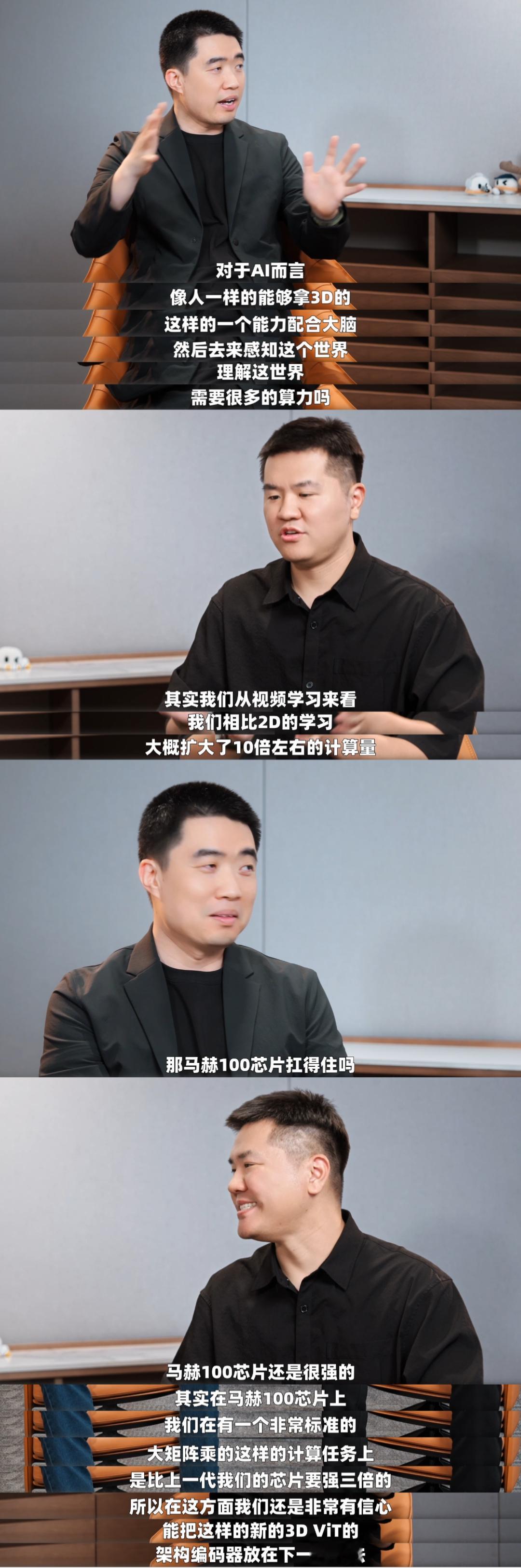
MindVLA-o1 的核心突破在于搭载 3D ViT + 多模态思考能力,尝试解决AI对3D空间理解的核心痛点。此前绝大多数视觉训练基于二维图像,AI 仅能识别语义却无法感知真实物理空间的结构,如同靠视频学开车。MindVLA-o1 让车具备理解三维空间的能力,通过激光雷达点云结合 3D ViT 编码,拆分静态背景与动态物体分别建模,还能通过预测式隐世界模型,在行动前推演未来几秒场景演化,像人类一样提前 “预判” 路况,有点类似于打网球的机器人。
这背后是理想对物理世界 AI 的深层思考:物理 AI 的终局是构建具备完整感知与行动能力的 “硅基人”,其融合视觉、语言、行动的 VLA 架构,不仅能精准控制车辆,还能直接跨界应用于机器人控制,比如机械臂操作等场景,毕竟理想马上也要进入具身智能领域了。李想称机器人也用VLA理想全能辅助驾驶来了理想发布下一代自动驾驶基础模型