在莱布尼茨超级计算中心部署首款光子处理器一年后,Q.ANT公司再度发力,推出了一款更具野心的产品,第二代NPU。这款设备的定位并非简单加速AI负载,而是从底层重构支撑AI运行的数学模型与能耗模式。如果说第一代NPU验证了 “以光作为实用计算介质” 的可行性,那么第二代NPU则直观展现出,一旦摆脱晶体管尺寸微缩的限制,光子计算架构的演进速度将何其迅猛。

Q.ANT发布NPU 2,这一代产品的核心突破聚焦于光的原生非线性计算。第一代光子芯片仅支持线性光子运算,而第二代NPU突破这一局限,可直接执行通常需要多层数字计算才能完成的神经网络功能。
这一技术变革显著提升了计算精度、减少了模型参数数量,并缩短了训练深度,这些均是衡量当下人工智能加速能力的关键指标。该处理器被整合进一套全功能19英寸服务器中,内置多颗NPU芯片、x86 主机处理器,以及标准 PCIe 接口。整套系统可直接嵌入HPC集群与数据中心机柜,无需对现有工作流进行大规模改造。
NPU 2的核心创新Q.ANT首款光子处理器可利用光子实现高精度线性代数运算,为推理负载带来可观的能效提升。而第二代NPU新增了重构的非线性计算核心,内置一枚模拟光学单元,能够通过单步光学操作完成类激活函数运算。
这一能力是绝大多数现代AI模型的核心需求。在光子域直接支持非线性运算,大幅拓展了可被光子技术加速的算法范畴。Q.ANT表示,经过增强的非线性计算模块,可让神经网络以更少的参数、更低的计算深度实现更高精度,这在图像学习与物理仿真类任务中优势尤为突出。
Q.ANT技术平台依旧基于铌酸锂薄膜光子芯片,这种芯片以低光学损耗和高速光开关特性著称。第二代产品在这一基础上进一步优化了模拟光学性能。通过在光子电路内部完成非线性运算,NPU 2避免了运算任务在光子与电子单元之间的频繁交互,从而突破数据传输瓶颈、提升运算速度,尤其适用于严重依赖非线性行为的AI模型,例如图像识别、运动规划,以及基于物理定律的仿真计算。
核心规格与系统特性与第一代产品不同,NPU 2并非以独立PCIe加速卡的形态推出,而是被封装为一套完整的19英寸机架式服务器。每套设备的机箱内均集成多颗第二代NPU芯片、一枚x86主机处理器,并预装Linux操作系统。

系统提供 C、C++ 与 Python 编程语言接口,可与现有高性能计算及人工智能框架无缝兼容。同时,Q.ANT自研的光子算法库(Q.PAL) 提供了针对光子硬件深度优化的非线性函数。对于开发者而言,核心变化不在于编程接口,而在于底层计算模型,以往需要依靠庞大、深层网络架构实现的算法,如今可在光子计算架构上以更高效的方式重构。
能耗降低30倍、性能提升50倍当前,AI模型的发展已逼近GPU的功耗极限、散热能力上限与内存带宽瓶颈。NPU 2以截然不同的思路应对这些挑战:所有运算通过光子完成,过程中几乎不产生热量,同时大幅降低了数据传输环节的能耗。
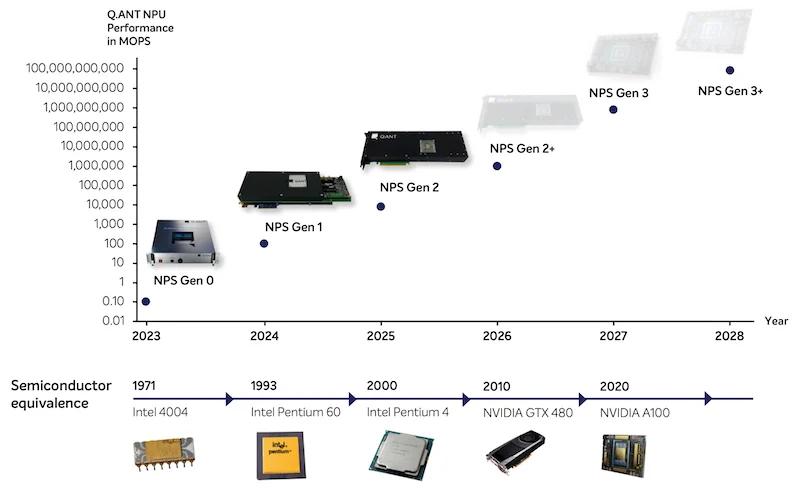
Q.ANT表示,针对特定人工智能与高性能计算负载,该系统可实现能耗降低 30 倍、性能提升 50 倍的效果。由于光子运算具备超高带宽,且可同时处理多波长光信号,NPU 2 能够轻松应对那些足以压垮传统数字计算架构的高速数据流。
落地应用场景NPU 2到底适用于哪些落地场景呢?首先是视觉系统,在工业质检、机器人技术与物流分拣等场景中,现有的非线性模型往往需要动用整排的 GPU 服务器才能实现实时性能。基于光子处理器运行这类模型,不仅性能达标,还能大幅降低功耗,为智能视觉系统在边缘端的部署铺平了道路。
其次是科学计算负载。在材料科学研究、气候模拟、核聚变研究与药物研发等领域,基于物理规律构建的模型均可借助NPU2 的光学非线性运算能力,替代传统的数字计算方案。此前Q.ANT做过一次演示,通过一个小型非线性光子网络,在数秒内完成图像学习任务。这充分印证了,该技术平台正快速从早期原型向实用化阶段迈进。
凭借第二代NPU产品,Q.ANT将推动光子计算从概念走向实用化平台。若早期测试数据能够得到验证,那么NPU2 将实现一项明确的技术突破,即光子计算架构的规模化演进速度,有望超越传统的CMOS架构,为人工智能与高性能计算系统的发展开辟全新路径。
想要获取半导体产业的前沿洞见、技术速递、趋势解析,关注我们!