就在刚刚,清华大学的一项AI for Science研究不仅登上Nature,而且还被Science深度报道了。

这项来自清华大学李勇团队的研究通过分析全球2.5亿篇科学文献,揭示了AI for Science领域存在的一个典型矛盾——
AI在助力科学家“个体加速”的同时,却导致科学界的集体注意力窄化和趋同优化的“群体登山”现象。
就是说,虽然AI帮助科学家发表了更多论文、更早成为项目负责人,但却导致人们集体涌入少量适合AI研究的“热门山峰”,从而无形中削弱了科学探索的广度。
而且进一步分析表明,这一矛盾绝非偶然,而是由当前科学智能AI模型缺乏通用性导致的系统性影响。

下面详细来看这到底是一项怎样的研究。
第一步:寻觅AI for Science的演化踪迹回到起点,团队之所以进行这项研究,主要是发现AI for Science领域存在一个明显矛盾——
在AI持续赋能科研的背景下,为何各学科的整体科学进展未见明显加速?
一方面,AI for Science研究已经产生了AlphaFold这样的荣获诺贝尔奖的成果;但另一方面,统计表明各学科领域的颠覆性研究成果在逐年下降,似乎未能获得AI助力。
这背后的原因到底是什么?到目前为止,业界仍然没有明确答案。
于是,团队向着这一问题出发了,并最终发表了《Artificial Intelligence Tools Expand Scientists’ Impact but Contract Science’s Focus》这篇论文。

在论文中,团队进行的首项工作是:从浩如烟海的文献中找出那些“AI赋能的研究”。
这一步对后续定量刻画AI对科学的影响至关重要。
为此,团队摒弃了停留在关键词层面的浅层检索方法,而提出了一条“高质量专家标注 + 大规模语言模型推理“相结合的技术路径——
通过领域专家标注少量论文样本,再让语言模型大规模推理的迭代优化,逐步让语言模型学会从标题和摘要中深层次的分析“那些是使用了AI工具的研究”。
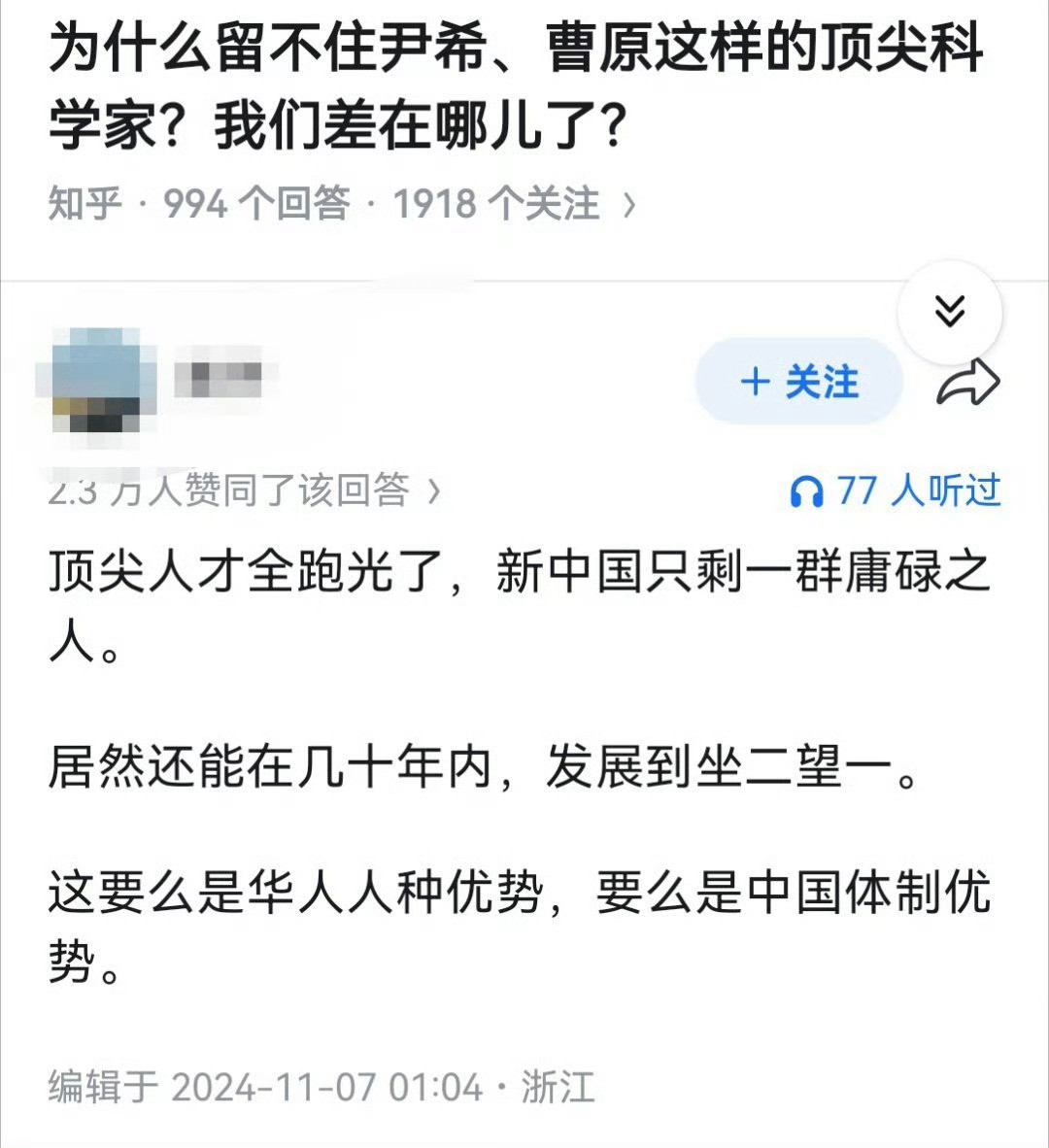
论文显示,BERT的识别准确率非常高,达到了0.875分(满分为1)。
靠着这套方法,他们扫描了近50年来的海量文献(涵盖1980-2025年),最终画出了一张“AI赋能科研全景地图”。
这张地图横跨“机器学习、深度学习、生成式AI”三个时代,涵盖4130万篇论文、覆盖2857万研究者,被团队视为研究“AI如何系统性影响科研”的首个基准数据集。
 然后…发现AI for Science领域的矛盾效应
然后…发现AI for Science领域的矛盾效应 基于该数据集,团队系统性分析了AI在自然科学六大领域(生物、医学、化学、物理、材料科学和地质学)的影响。
所采用的分析方法大致可分为以下三个阶段:
step 1:构建“科学语义地图” step 2:定义衡量“广度”的指标 step 3:进行比较分析简单来说,团队想要回答一个关键问题——
有了AI的帮助后,科学家探索的领域到底是变宽了,还是变窄了?
为了客观衡量这种看不见、摸不着的“认知版图”,他们提出了基于隐藏变量的科学学分析方法。
该方法和传统科学学的区别在于,它不再仅仅依赖论文的标题、关键词、作者、引用关系等“表面”数据,而是深入到论文的“思想”和“内容”本身,从而能更精细地度量像“知识广度”这样抽象的概念。
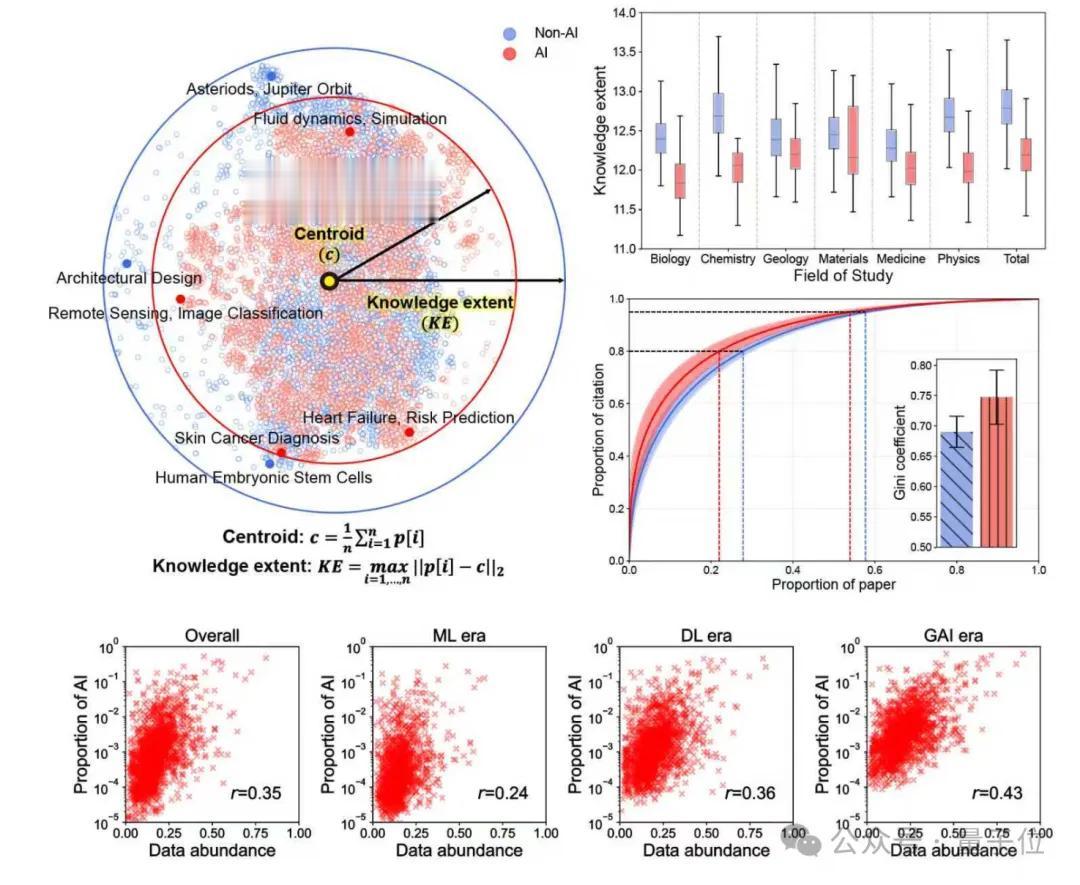
具体到第一步,他们把每篇论文中最能代表其内容的标题和摘要作为核心文本,通过一个深度嵌入表征模型转换成一个由768个数字组成的、固定长度的数学向量。
这个向量就是每篇论文在高维数字空间中的“坐标”——理论上,语义相似的论文,其向量距离也会更接近。

而当所有论文都找到自己的“坐标”后,团队主要通过“直径”和熵值这两个指标来测量知识广度。
前者用来衡量探索的“最远边界”。
比如对于某个领域一年的AI论文,先计算它们所有坐标点的几何中心,然后找出离中心点最远的那篇论文,测量它们之间的欧氏距离。
这个距离就是研究中定义的“直径”,用于衡量这批论文的主题覆盖广度。直径越大,说明探索的范围越广。
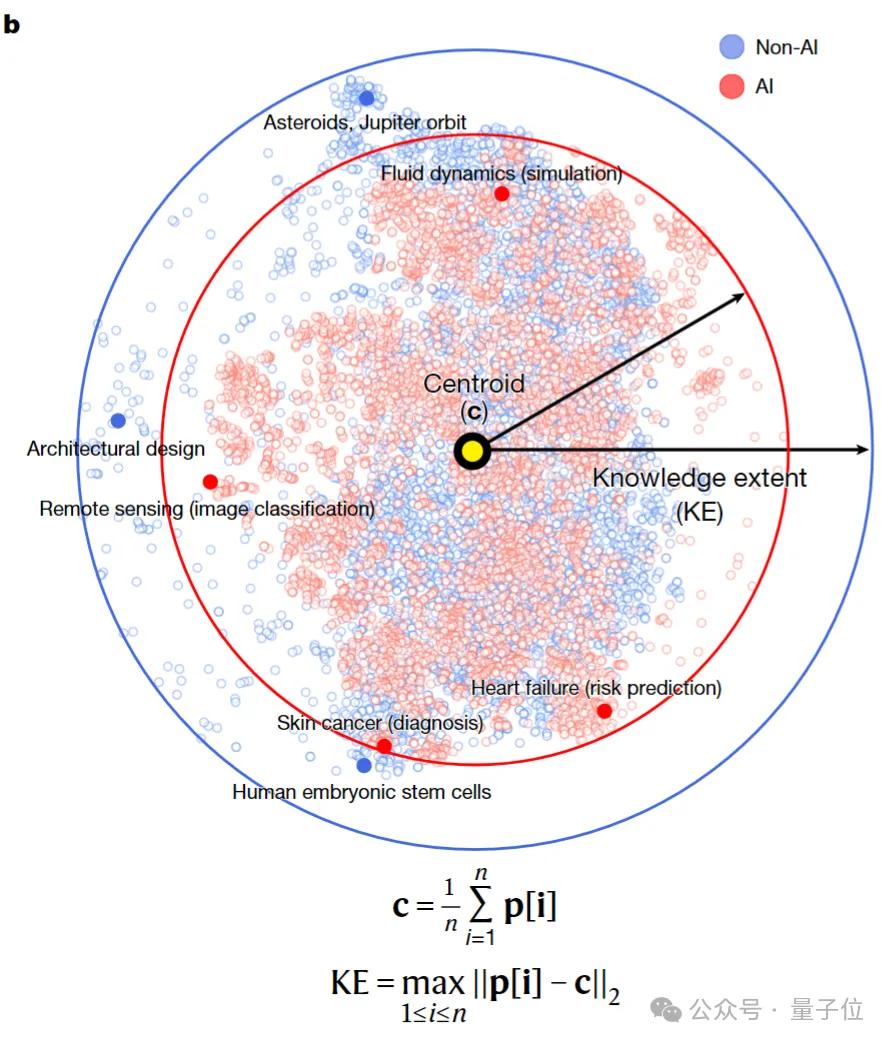
后者用来衡量分布的“均匀度”。
这是指分析同一批论文坐标点在空间中的分布状态——如果均匀分散在空间各处则熵值高,反之,如果它们紧密地聚集在少数几个热点周围,则熵值低。
然后就用这些指标去分别测量两类科学家群体的论文:一类是使用AI进行研究的,另一类是不使用AI的。
以此判断AI究竟是在扩张还是收缩科学的认知边界。
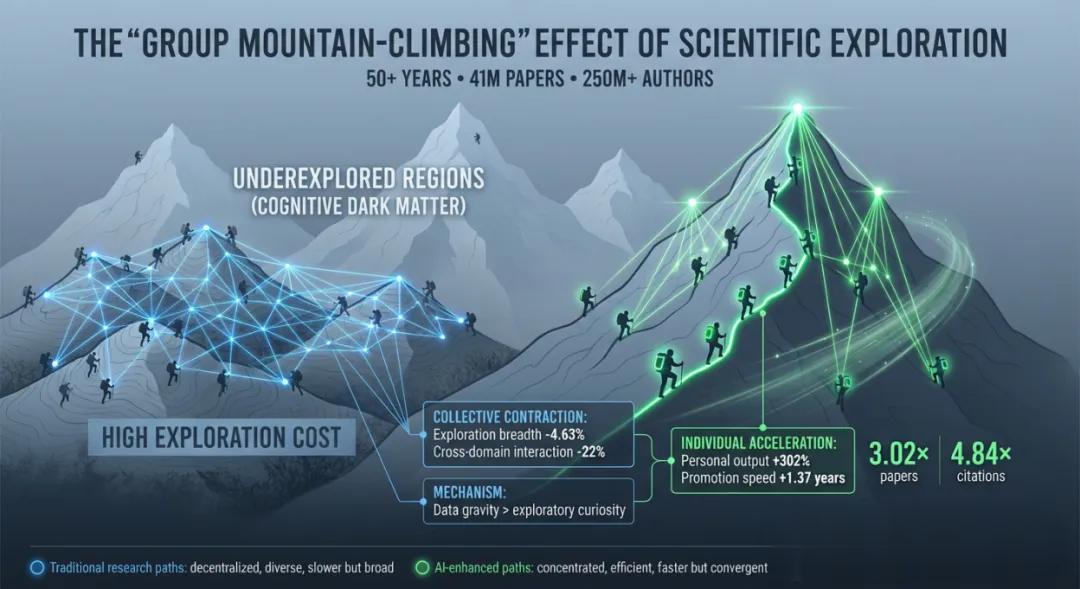
结果发现,在微观个体层面,使用AI的科学家比不使用的多发表3.02倍论文,获得4.84倍引用量。
而且前者更是提早1.37年成为研究项目负责人(以末位作者为标志)。
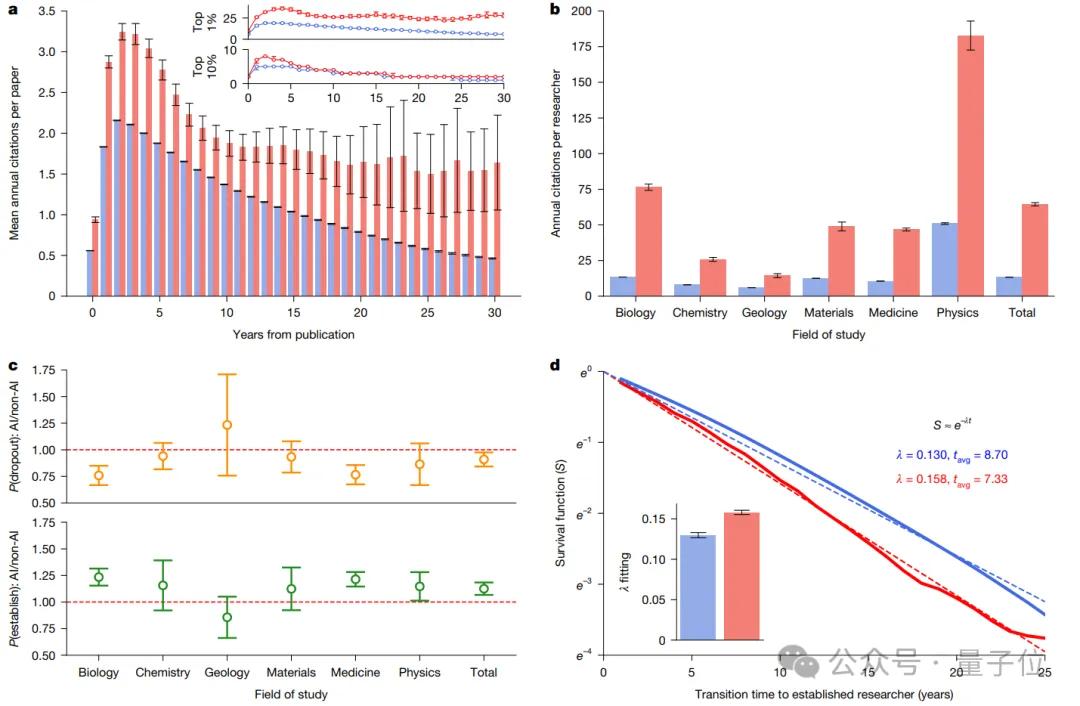
然而,个体科研加速的背后,却是人类整体科学版图的异常收缩。
在集体层面上,与AI结合的科研项目的知识广度下降了4.63%、不同领域科学家间的跨界互动减少了22%,而且AI论文引用呈现“星型结构”——
几乎都在引用同一篇或少数几篇经典的、开创性的AI工作,这表明研究趋向集中和单一化,缺少创新活力。
那么问题来了,这一矛盾现象究竟是什么导致的呢?
背后原因揭秘:当前模型缺乏通用性论文给出了一个明确结论——
这是由当前AI for Science模型缺乏通用性导致的系统性影响。
团队发现,AI的高效率产生了一种强大的“科学智能引力”效应。它引导研究者集体涌向少量适合AI研究的“热门山峰”,即那些已有大量数据、适合用现有AI方法快速出成果的研究方向。
这种“群体登山”模式,虽能加速对已知问题的解决,却也在无形中固化了科学探索的路径,系统性地削弱了科学家向“未知山峰”探索的广度。
最终就形成了“广度让位于速度”的现象。
团队表示,这一矛盾机制的发现是对AI赋能科研模式的深度反思:
现有的AI for Science虽然极大地促进了局部的效率提升,却难以驱动全链条、多领域的科研创新。
而为了突破这一局限,徐丰力、李勇教授团队最终推出了全流程、跨学科的科研智能体系统—OmniScientist。(访问网址:OmniScientist.ai)
该系统通过深入挖掘大模型智能体的通用推理能力,实现跨学科、全流程、多模态的系统性科研支持,从而让AI从“辅助工具”进化为具备“主动提出假说、自主设计实验、分析结果并形成理论”的“AI科学家”。

最后,这项研究完成单位为清华大学电子工程系、芝加哥大学社会学系,通讯作者为徐丰力助理教授、李勇教授、James Evans教授,第一作者为清华大学电子工程系博士生郝千越。
论文:
https://arxiv.org/abs/2412.07727
— 完 —
量子位 QbitAI
关注我们,第一时间获知前沿科技动态