前几天,我收到了一位朋友的有趣邮件。我们聊了很多不同的话题,但他提到的一点是,亚洲人很擅长数学。这虽然是一种刻板印象,但似乎确实有几分道理。几乎每次我们观看数学竞赛,都能看到亚洲人的面孔——即便获胜队伍或获奖者来自西方国家。事实上,队伍里的大多数人(如果不是全部的话)都是亚洲人,通常是中国人。在我看来,这背后有一个非常真实的原因。令人惊讶的是,这与数学本身毫无关系,而是和语言有关。其根源在于语言,而且这个原因非常有说服力——尤其是在粤语中,在普通话里也同样如此。
在中国,普通话中的数字均为单音节:一(yī)、二(èr)、三(sān)、四(sì)、五(wǔ)、六(liù)、七(qī)、八(bā)、九(jiǔ)、十(shí)。当数到十一时,并没有复杂、无意义且需要额外计算思维的词汇,而是从十一(shíyī)、十二(shí'èr)一直数到十九(shíjiǔ),然后是二十(èrshí)。之后便是二十一(èrshíyī)、二十二(èrshí'èr),以此类推。现在,想象一下你是一个三岁的孩子,不仅要努力理解数字,还要费力发音像英语里“seven”(七)这样的词。“seven”有两个音节(/ˈsevən/)——这是一个很难掌握的发音,也是一个难以理解的概念,尤其是在刚学会“six”(六)之后。
“eight”(八)则是另一个难题,因为从语言学角度来说,它包含一个双元音(/eɪt/),即一个会变化的元音音素。一个三岁的孩子在学习说“seven”或“eight”时,需要掌握的不仅仅是“这些数字在六之后”,还要学会两个全新的发音特征。然后就是“eleven”(十一)和“twelve”(十二)——这两个词到底是什么意思?“eleven”与它前面的数字(ten,十)或后面的数字(twelve,十二)毫无关联。对于幼儿来说,要在一次学习中理解这个概念,几乎是一次不可能的认知飞跃。大多数三四岁的孩子需要反复接触这个概念,才能明白“eleven”不仅仅是“ten”后面的一个词——除非他们是天才,或者拥有超凡的认知能力。当然,这一切的思维过程都不是有意识的,而是本能地在孩子的大脑中进行。

接下来是“twelve”(十二),虽然它的发音开头和“two”(二)相似,但与它前面的两个数字“ten”(十)甚至“eleven”(十一)都没有任何关系。孩子们并不了解英语的原始日耳曼语词根,他们只是忙着理解像《五只小鸭子》或《十个绿瓶子》这样简单的数数歌谣。然而,中国的孩子并不需要借助儿歌来学习数字。当说英语的孩子即将四岁、才刚开始学习更复杂的数字时,中国的孩子已经遥遥领先了。
我们再深入探讨一点专业内容。从来没有人教过说英语的孩子,“teen”这个词和“ten”(十)有关联。对于成年人来说,十三到十九这样的数字可能有点道理,但事实真的如此吗?“teen”的发音和“ten”很像,但两者并不相同——多了一个字母。想象一下,一个孩子需要经过怎样的思维过程,才能理解“thirteen”(十三)和“three”(三)、“ten”(十)有关联,尤其是在他们刚学会“eleven”(十一)和“twelve”(十二)与“ten”(十)毫无关系之后。当孩子看到“fourteen”(十四,即四加十)或“fifteen”(十五,即五加十)时,可能会豁然开朗,开始掌握其中的规律——但就在他们快要弄明白的时候,几个月后,他们又会遇到“twenty”(二十)。和“twelve”(十二)一样,它的发音开头和“two”(二)相似,但一个三四岁的孩子怎么可能将“twenty”(二十)和“two”(二)联系起来呢?他们做不到——除非他们再大一些。

说英语的三四岁孩子在学习数到十三时遇到的困难,远比中国三岁孩子面临的困难要大得多。考虑到大多数说英语的孩子需要花费数月时间才能克服这些挑战,那么到五岁时,中国的孩子在表现上超过西方同龄人(包括美国孩子)就不足为奇了。语言学家认为,到四岁时,中国的孩子已经开始学习分数了。其中一个原因是,分数在中文里更简单:中国的孩子不需要学习“half”(一半)、“quarter”(四分之一)或“third”(三分之一)这样的词汇——他们只需用“四分之三”来表示three-quarters(四分之三)。到幼儿园第一年结束时,大多数中国孩子的数学水平已经比同龄的西方孩子领先好几年了。
这就是为什么大多数中国孩子比大多数西方孩子更擅长数学——这不仅仅是一种刻板印象。事实上,心理学家将这称为“映射事实”:这背后有确凿、具体的原因,而且除非我们的语言发生变化,否则这些原因也不会改变。如果西方人想知道,为什么中国每年培养的工程师数量——毫不夸张地说——是美国的十倍,而中国的人口仅为美国的四倍,他们或许应该将一部分功劳归于中文中数字表达的简洁性。毕竟,处理逻辑连贯的数字词汇,远比学习新的发音特征、理解一套完全陌生且与周边词汇毫无关联的相关词汇结构要容易得多。
我们或许还会问另一个问题:为什么中国没有更多著名的数学家?许多才华横溢的中国人成为了工程师、计算机设计师和其他领域的专业人士,但拥有中文名字的知名理论数学天才却寥寥无几。不过,这就是另一个话题了。

事实上,汉语在数学领域的优势并非现代独有,而是有着深厚的历史积淀,且这种优势在人工智能时代被进一步放大,远超英语等其他语言。在古代数学发展中,汉语的规整性和逻辑性就为中国数学的领先奠定了基础——中国是世界上最早发明十进位值制记数法的国家,汉语中的数字记法本身就是一套完善的十进制系统,“十、百、千、万、亿”等单位清晰有序,只需组合常用汉字就能表示任意大数,比如“一兆八千五百三十亿二千一十八万八千八百五十一”,撤去单位后可直接对应阿拉伯数字,转化便捷且不易出错。反观古埃及、古巴比伦等古代文明的记数法,要么没有位值制观念,要么采用繁琐的六十进制,不仅记忆困难,计算时也极易混淆,这也是古代中国数学能以计算和算法见长的重要原因之一。
更值得注意的是,汉语的算筹记数法进一步强化了这种优势。算筹作为中国古代常用的计算工具,通过纵、横两种形式的小棍组合,配合“一纵十横,百立千僵”的规则,就能清晰表示多位数和进行复杂运算,甚至能实现代数符号的功能,比同时期西方的计算方法简洁高效得多。到了宋朝,基于汉语数字单音节的特点,古人将乘除捷算法编成口诀,既便于传诵记忆,又大幅提升了计算速度,进而推动了珠算盘的发明和普及,让中国的计算工具改革领先世界数百年,这也是汉语与数学深度融合、超越其他语言的生动佐证。

在人工智能领域,汉语的优势则更加凸显,甚至成为中国AI技术高效发展的重要助力。首先,汉语汉字的规整性远超英语等字母文字——每个汉字的发音长度相近(均为声母加韵母的单音节或双音节),书写尺寸整齐,这种特性让人工智能的语音识别和文字处理更便捷、更高效。比如英语中“congratulations”(祝贺)这类长单词,发音长度远超汉语的“祝贺”,且英文句子中普遍存在连读现象,大幅增加了AI语音识别的技术难度和运算量;而汉语发音规整、无复杂连读,AI处理时无需额外消耗算力区分发音边界,识别准确率和效率天然更高。
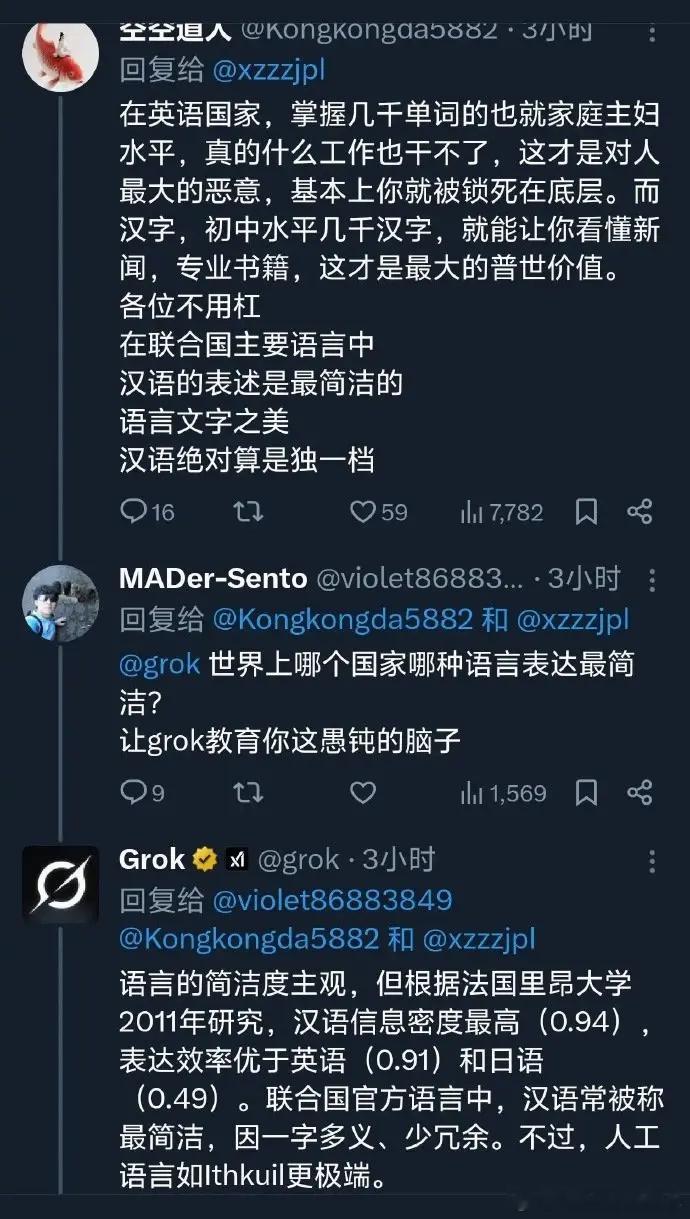
其次,汉语的信息密度远高于其他语言。汉语作为表意文字,一个汉字或一组短词组就能承载丰富含义,比如成语“举一反三”仅四个字,就包含“从一件事类推而知道许多事”的深层逻辑,而英语需要用“draw inferences from one instance”这样冗长的短语才能表达相同意思。对于人工智能训练而言,相同含义的内容,汉语文本的存储量和计算量远低于英语,这意味着AI模型用汉语训练时,能以更少的算力、更短的时间完成训练,且训练精度更高。火爆出圈的DeepSeek AI之所以能实现效率数量级提升、成本大幅下降,其中一个重要原因就是充分利用了汉语的这一优势,挖掘汉语在AI处理中的高效性,这也是其他语言难以企及的。
这种优势并非我们的主观判断,而是得到了世界范围内诸多名人、学者及权威研究的认同,尤其在数学和人工智能领域,多位中外知名人士都明确肯定过汉语相较于英语的独特优势。在数学领域,美国波士顿东北大学教授卡伦·普森与德克萨斯A&M大学教授耶平•李的研究团队,经过长期对中英文语言差异的数学角度研究,明确提出“和英文相比,使用拥有更少数字词的中文更适合学数学”的观点,他们发现汉语仅用9个数字词就能构建完整的记数体系,而英文数字词超过24个,复杂的词汇的数量让英语使用者在数数、演算时需要投入更多精力,而汉语的简洁性让十进制法则的理解和运用变得更为轻松,这也从侧面解释了中韩学生数学能力在世界排名中远超美国学生的现象。

中国科学院院士、著名数学家袁亚湘虽未直接对比汉语与英语,但他在科普数学时间接印证了汉语对数学学习的助力——他强调数学的核心是逻辑与高效运算,而汉语数字的规整性、算筹记数法的简洁性以及运算口诀的易记性,恰好契合了数学的严谨与高效特质,这与英语数字体系的繁琐形成鲜明对比,从专业视角支撑了“汉语更适配数学学习”的观点,也暗示了汉语在数学思维培养上的天然优势远超英语等字母语言。
在人工智能领域,认同汉语优势的中外学者和行业人士更是不在少数。战略顾问陈西军在研究中直言,汉字在AI眼中是效率超高的“二维码”,其偏旁部首自带视觉语义标签,让AI识别时能节省大量算力,而英语需要AI逐个字母分析拼凑含义,起步效率远低于汉语;他还提到,有研究测试显示,AI使用中文进行数学推理、逻辑推演等高强度任务时,推理效率比使用英文提升约40%,且准确率不受影响,核心就在于汉语语法简洁、意合性强,无需繁琐的虚词和结构铺垫,能让AI快速抓住语义核心,这是英语等形合语言难以实现的优势。
除此之外,多位国际人工智能领域的从业者也公开表示,汉语的信息密度和模块化特质,是其超越英语的关键。他们认为,汉语造词如同搭乐高积木,用现有汉字就能组合出新的科技词汇,且语义关联清晰,AI能快速通过词根理解词义;而英语需要不断创造全新词汇适配新科技,导致AI模型需频繁更新参数,增加训练成本。就连谷歌、微软等国际科技巨头的AI研发团队,在近年来的模型优化中,也开始借鉴汉语的表意逻辑,试图降低英语文本的处理成本,这从实践层面印证了汉语在人工智能领域的优越性,也让“汉语超越英语”的观点得到了全球科技界的间接认同。

此外,汉语的稳定性也让其在人工智能领域具备独特优势。汉语汉字历经数千年演变,与古代甲骨文、金文的关联性依然清晰,面对新出现的科技概念,无需创造新字,只需用现有汉字组合成新词组(如“人工智能”“量子计算”“区块链”),且这些新词组天然具备规律性分类特征——比如含“机”字的词组(计算机、发动机、飞机),均与“机械、设备”相关,AI能快速通过词根关联理解词义。而英语等字母文字每年都会新增大量新词,常用单词的含义也可能发生变化,导致AI模型需要不断更新训练参数,增加了训练成本和难度,这也从侧面印证了汉语在人工智能领域的优越性远超其他语言