 云霞育儿网
云霞育儿网MySQL双库架构实战:千万级用户行为与画像的高性能优化指南
MySQL双库求生指南:用户行为+画像的实战搭配
用这3招让你的用户分析系统不再宕机
MySQL用户行为库的骚操作:分表+去重实战
手把手教你用MySQL搞定千万级用户追踪
在数字化运营的今天,用户行为分析与画像构建是驱动业务增长的核心引擎。随着用户规模突破千万级,两大核心数据库常陷入冰火两重天的困境:
用户行为库(user_behavior):面临每秒万级写入压力,重复数据如潮水般涌来,查询时频繁出现UV 统计拖垮数据库的惨案
用户画像库(user_profile):标签更新滞后导致分析失真,多版本数据共存引发关联查询灾难,成为运营决策的定时炸弹。
本文将深入剖析两大库的底层架构,结合真实生产事故,演示如何通过分表设计、唯一约束、版本控制等核心技术,构建稳定高效的用户数据分析体系。
用户行为库:千万级数据的存储与去重革命
分表维度的战略选择

实战案例,某短视频 APP 的行为库分表
采用时间分片结合天级分区策略,每日生成新表user_action_YYYYMMDD,分区规则如下。

分表后的查询优化三板斧
强制分区剪裁:通过action_time精确指定分区,避免全表扫描

覆盖索引设计:针对高频查询字段建立联合索引,减少回表

冷热数据分离:超过 3 个月的数据迁移至归档库,保留最近 90 天热数据在主库
去重体系:从数据噪声到纯净分析
重复数据的三大来源与对策
 三级去重机制实战
三级去重机制实战客户端层,生成全局唯一请求 ID,UUID + 毫秒时间戳。

服务端层:Redis 缓存请求 ID,设置 30 秒有效期

服务端层:Redis 缓存请求 ID,设置 30 秒有效期

数据库层:唯一约束结合冲突处理

用户画像库:动态标签的精准控制
画像表结构设计的黄金法则

版本号驱动的更新机制
原子性更新操作,防止并发冲突。

历史版本追溯:建立独立的profile_version表存储所有变更记录
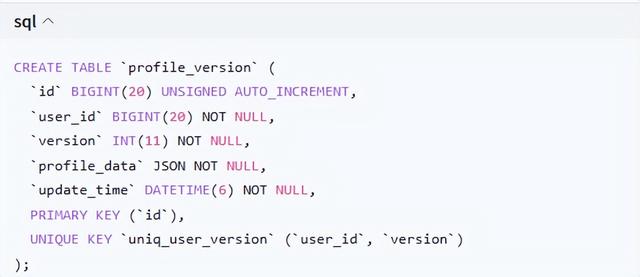
异步更新架构设计
写入流程:用户修改资料→发送 Kafka 消息→消费端异步更新画像库
一致性保障:通过分布式事务,如 Seata或最终一致性校验脚本
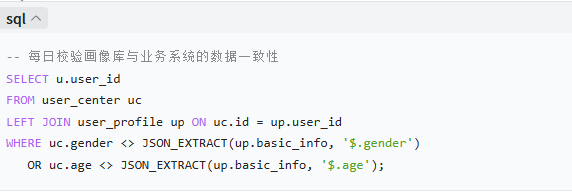
标签存储优化:从混乱到规范
JSON 字段的高效查询
MySQL 5.7+ JSON 原生支持

建立冗余字段:对高频查询的标签(如城市、性别)建立独立字段

标签规范化治理
统一字典表:建立tag_dictionary表管理标准标签

ETL 清洗流程:数据入库前通过 Apache Flink 清洗不规范标签

双库联合作战:从数据孤岛到分析闭环
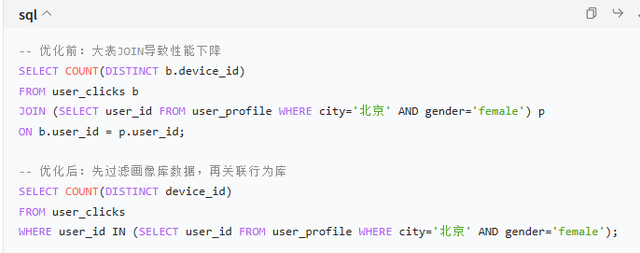
高效关联查询的三大法宝
覆盖索引优化 JOIN 性能

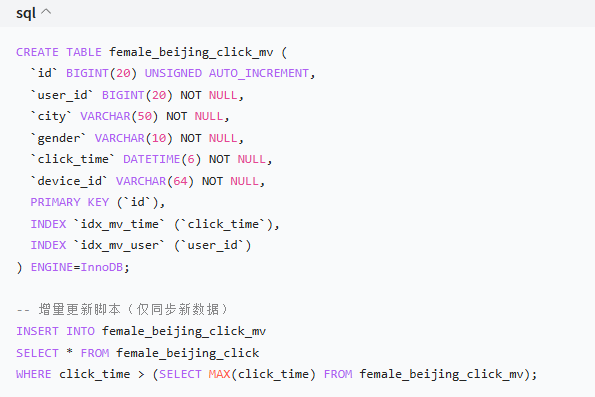
物化视图预聚合高频数据
创建实时分析视图
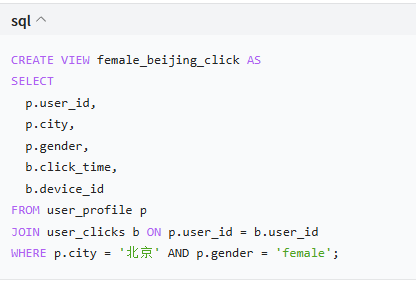
定时刷新物化表(每 10 分钟更新一次):
子查询优化策略
将复杂 JOIN 转为 IN 子查询,适用于画像库小表场景。
 数据一致性保障体系
数据一致性保障体系三大一致性校验场景

分布式事务方案对比

最佳实践:采用本地事务结合异步对账模式,核心字段如 user_id、device_id通过唯一约束保证强一致,非核心字段通过每日对账脚本修复。
生产事故复盘与避坑指南案例一:设备 ID 重复导致 UV 虚增 500%
事故现场:运营统计某活动 UV 时发现数值异常,实际设备数远低于统计值
根本原因:行为库未建立device_id, action_time联合唯一约束,刷子通过批量脚本发送重复设备的点击请求
解决方案:
紧急添加唯一约束,清理重复数据
引入设备指纹校验结合 IP、设备型号、MAC 地址生成唯一标识。

案例二:画像更新延迟导致运营误判
事故现场:用户修改性别后,行为分析报表仍显示旧标签,导致性别转化率分析错误
根本原因:画像库采用同步更新模式,高并发下更新阻塞,版本号未正确递增
解决方案:
改造为异步更新架构,通过消息队列削峰填谷。
在关联查询时强制使用最新版本号。

案例三:关联查询导致数据库 CPU 飙升至 100%
事故现场:运营执行北京用户近 30 天点击分析时,数据库 CPU 瞬间打满,触发熔断机制
根本原因:未对关联字段建立索引,两千万级数据 JOIN 时全表扫描
优化步骤:
分析执行计划,发现user_profile.city未使用索引
建立复合索引INDEX idx_profile_city_gender
对行为库按user_id, click_time建立覆盖索引
优化后:查询时间从 18 秒降至 400ms,CPU 利用率回落至 20%
性能监控与持续优化
核心监控指标体系
 周期性优化任务
周期性优化任务碎片整理:每月对行为库历史表执行OPTIMIZE TABLE(InnoDB 行碎片率 > 30% 时触发)
索引重构:通过pt-query-digest分析慢查询日志,删除冗余索引(如使用率 < 5% 的索引)
数据归档:将超过 6 个月的行为数据迁移至 HDFS,保留最近 180 天数据在 MySQL

架构升级:从单机到分布式的跨越
当数据量突破亿级,需引入分布式数据库架构。
用户行为库分布式方案
分片策略:采用user_id % 1024哈希分片,每个分片存储约 100GB 数据
中间件选择:MyCat/ShardingSphere,实现读写分离与分片路由
高可用:每个分片部署一主两从,通过 ZooKeeper 实现故障自动切换
用户画像库优化方案
缓存层:Redis 存储高频访问的用户标签(QPS 降低 60%)
列式存储:对标签统计类需求(如各城市用户分布),使用 ClickHouse 加速聚合查询
实时更新:通过 Canal 监听 MySQL binlog,实时同步画像变更至 Elasticsearch
总结:构建数据驱动的核心竞争力用户行为库与画像库的优化,本质是在数据完整性与查询效率之间构建动态平衡。
通过分表分库解决数据规模问题,通过唯一约束与版本控制保障数据质量,通过索引优化与物化视图提升分析效率,最终形成从数据采集、存储到分析的全链路解决方案。
记住三个核心原则:
防患于未然:在表结构设计阶段预埋唯一约束、版本号、分区键等防坑点
数据即资产:建立完善的数据治理体系标签规范、去重规则、一致性校验。
工具驱动优化:善用执行计划分析、慢查询日志、监控平台等工具定位问题。

当这两大数据库被驯服,企业将获得精准触达用户的数据罗盘,无论是精细化运营、个性化推荐还是业务趋势预测,都能从高质量的数据中获得可靠支撑。
下一次面对千万级用户分析需求时,你的系统将成为业务增长最坚实的底座。

发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。