
Meta周末抛出重磅炸弹——Llama 4系列模型,宣告原生多模态AI新时代的到来。
谷歌CEO劈柴哥第一时间发来贺电,AI领域的竞争愈发激烈。
Llama 4的发布,究竟会带来怎样的变革?
Llama 4家族目前包含Scout、Maverick和Behemoth三个模型。
前两者已正式发布,而Behemoth作为2万亿参数的超大模型,还在训练中,吊足了人们的胃口。
Meta官方毫不掩饰地将Scout和Maverick称为目前最好的多模态模型,并表示Llama 4的到来标志着Llama生态系统的新纪元。

Llama 4最引人注目的特性之一是其原生多模态能力。
用户可以直接上传图片并在对话框中提问,Llama 4能够理解图像内容并进行交互,其多模态性能远超同类产品。
这意味着AI模型的理解能力迈上了一个新的台阶。

除了多模态,Llama 4的长文本处理能力也得到显著提升。
Llama 4 Scout的上下文窗口高达100万,远超Llama系列前作以及其他竞争对手,为多文档摘要、代码库推理等任务提供了更多可能性。
Meta官方博客指出,Llama 4的长上下文能力将开启充满可能性的世界。
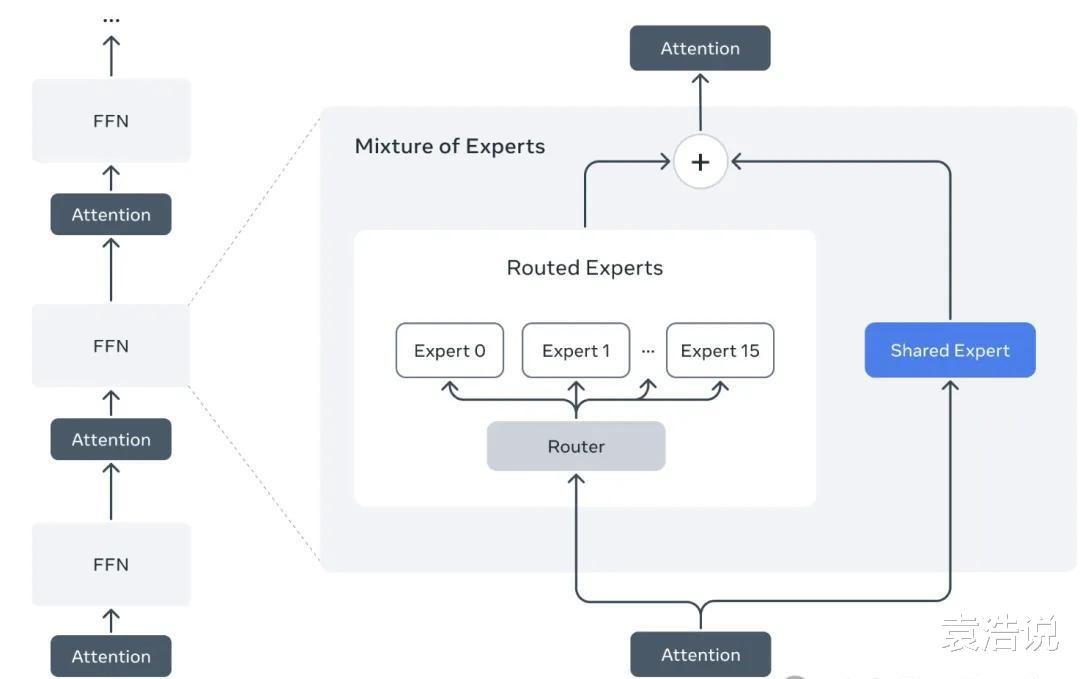
Llama 4系列首次采用MoE(混合专家模型)架构。
这种架构在训练和推理方面效率更高,降低了成本,使得在单个GPU上运行170亿参数的模型成为可能。
Llama 4 Maverick便是在单个H100 DGX主机上运行,方便部署。

为了方便全球开发者,Llama 4预训练支持超过200种语言,其中100多种语言拥有超过10亿词库。
Llama 4的训练数据总量是Llama 3的两倍多,包含文本、图像和视频等多种数据集。
Llama 4 Maverick的性能测试结果令人振奋。

它不仅在多项测试中超越了DeepSeek-V3,而且参数规模仅为后者的一半,成本更是大幅降低。
在开源模型排名中,Llama 4 Maverick直接登顶,成为新的王者。
Llama 4 Behemoth作为Llama 4家族的超大模型,拥有2万亿参数,被寄予厚望。

Meta透露,Behemoth在数学、多语言和图像基准测试中表现出色,预计性能将超越GPT-4.5等顶级模型。
Meta详细公布了Llama 4的训练细节。
在预训练阶段,他们使用了MoE架构、FP8精度训练以及30万亿token的混合数据。

后训练阶段则采用了课程学习策略、轻量级监督微调、在线强化学习和直接偏好优化等技术。
Llama 4还采用了一种名为iRoPE的架构,包含交错注意力层和旋转位置嵌入,旨在支持无限上下文长度。
Behemoth的训练则使用了动态加权软硬目标蒸馏、大规模强化学习以及异步在线RL训练框架等技术。
Llama 4的发布对AI竞争格局产生了巨大影响。
OpenAI CEO奥特曼感受到了压力,暗示GPT-5即将发布。
DeepSeek、通义千问等竞争对手也在积极研发,AI模型的竞争进入白热化阶段。
Llama 4的成本优势尤为突出。
相比GPT-4.5,Llama 4的成本降低了三个数量级,这对于开发者和企业来说极具吸引力。
“最牛”和“最便宜”的结合,让Llama 4成为AI模型领域的焦点。

目前,AI领域的竞争已经从模型本身扩展到落地应用和智能体。
Llama 4的发布无疑将加速这一进程。
未来,AI技术将如何改变我们的生活?

Llama 4又将在其中扮演怎样的角色?
这些问题值得我们深入思考和探讨。