某天在车友聚会上,朋友阿辉提起他的新车搭载了“高阶智驾”功能,大家纷纷围上去。
他滔滔不绝地讲着车子的“端到端”、D2D、“VLM”、“VLA”,惹得一堆朋友眼冒金星。
老李甚至打趣道:“阿辉,你是不是在跟我们炫耀你的新车自带天才司机功能?”阿辉笑了笑,苦口婆心地解释了一番,但多数人还是一脸迷茫。
于是,讨论变成了认真的“科普课程”,这才让大家对这些新名词有了些许概念。
自动驾驶的硬件卷还是软件卷?
几年前,车厂们在宣传自动驾驶时,主要强调硬件配置,比如高性能芯片和激光雷达。
那时候,阿辉还特别关注这些配置,认为硬件越强,车越高级。
但如今,他发现硬件并不代表一切,软件能力才是真正决定自动驾驶效果的关键。
几款硬件顶级的车型,搭载了多个激光雷达和顶配芯片,却在市场中反响平平,甚至有些车型未能上市。
消费者渐渐明白,硬件只是基石,强大的软件算法才能真正实现高阶智能驾驶。
于是,车厂们开始“卷”起了软件,纷纷推出各种高端智能驾驶系统。

有些专业术语虽然听起来很复杂,但如果你懂一点点,就不容易被割韭菜。
接下来,我们一起聊聊几个在高阶智驾系统中非常重要的名词。
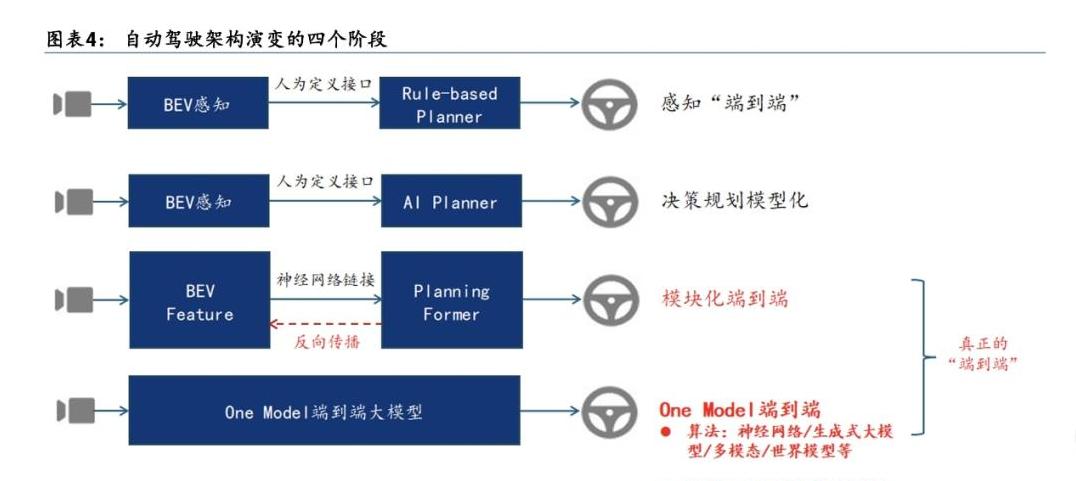
什么是端到端(E2E)?
简单来说,端到端是一种自动驾驶的算法范式,它模仿人脑的神经元连接,在模型的一端输入感知信息,另一端直接输出驾驶控制信号。
特斯拉最先跑通这个算法,随后很多车企也跟风采用。
阿辉打了个比方:“以前的自动驾驶就像流水线作业,每个步骤都分开处理,效率低,误差大。
而端到端就像高手练成的一套完整套路,能快速、无损地处理信息,让驾驶更流畅。”
虽然听起来很高大上,但实际上,端到端还有许多技术难点。
比如,它的自我解释能力较差,有时系统会出问题,却很难搞清楚在哪儿出错。
即便如此,很多车企开始用端到端来优化智能驾驶体验。
D2D(Door to Door)的实际意义D2D即从车位出发到另一个车位停下,中途完全不用接管。
阿辉边说边举例子:“就像上次我从地下车库出来后,车子一路导航,穿过种种复杂路况,直到另一个停车位停稳,完全没碰方向盘。”
这种全场景的智能驾驶让阿辉觉得有种“未来感”。
但各家车企对D2D的理解和实现方式不太相同。
比如,理想的系统会在公开道路上和停车场间切换模式,而特斯拉、小鹏的系统无论在哪里都是一套模式,保持体验的连贯性和完整性。
D2D体现了端到端性能的一部分,让车企向用户展示他们的智驾系统能否应对不同的场景。
2025年预计高阶智能驾驶将普及,大家都在比拼谁家的系统更强、更稳定、更好用。
VLM和VLA的区别与联系VLM,即视觉语言模型,将视觉信息和自然语言文本联系起来。
想想阿辉的车在识别路标、行人和车辆,再用这些信息帮他做驾驶决策,就是在用VLM。
在自动驾驶中,VLM能让系统更好理解复杂的交通环境,提高安全性和可靠性。
理想是国内第一个将VLM引入自动驾驶的车企,他们部署了双系统,一套用于视觉感知,另一套用于环境理解和决策。
阿辉说:“有了VLM,车子就像有了一位副驾教练,能在关键时刻帮忙判断。
不过,目前VLM还只是一个过渡阶段,不是最完美的解决方案。”一些业内人士认为,VLM的算力高投入和功能实现之间不够高效,将来单一模型可能会融合这些功能。
相比之下,VLA(视觉-语言-动作模型)则是VLM的升级版。
想象一下,它不仅能看懂图片和文字,还能像人一样推理和理解,从环境信息中生成具体的驾驶指令。
阿辉对此很期待,因为VLA能覆盖复杂的交通情况和长时序推理,做到更好的全局理解。
比如,在应对潮汐车道或者长时间推理时,VLA比传统基于规则的方案更具优势,有助于提升决策和适应性。
要实现VLA在车上的应用,还面临着车端算力不足的问题。
结尾:听完阿辉的讲解,大家对高阶智能驾驶的理解有了新的提升。
如今车市风起云涌,各家车企都在探索最优的路径。
未来几年,像端到端、D2D、VLM、VLA这样的名词,会随着技术普及逐渐深入人心。
智能驾驶的演进,就像一场汽车领域的“武林大会”,各大车厂争相推出自己的独门绝技。
面对层出不穷的智驾新概念,我们作为消费者,也需要不断更新自己的知识储备,不被市场上的噱头迷惑。
期待不久的将来,我们能亲身体验到这些看似复杂却真真切切改变驾驶体验的技术,享受更为安全、便捷的智慧出行生活。