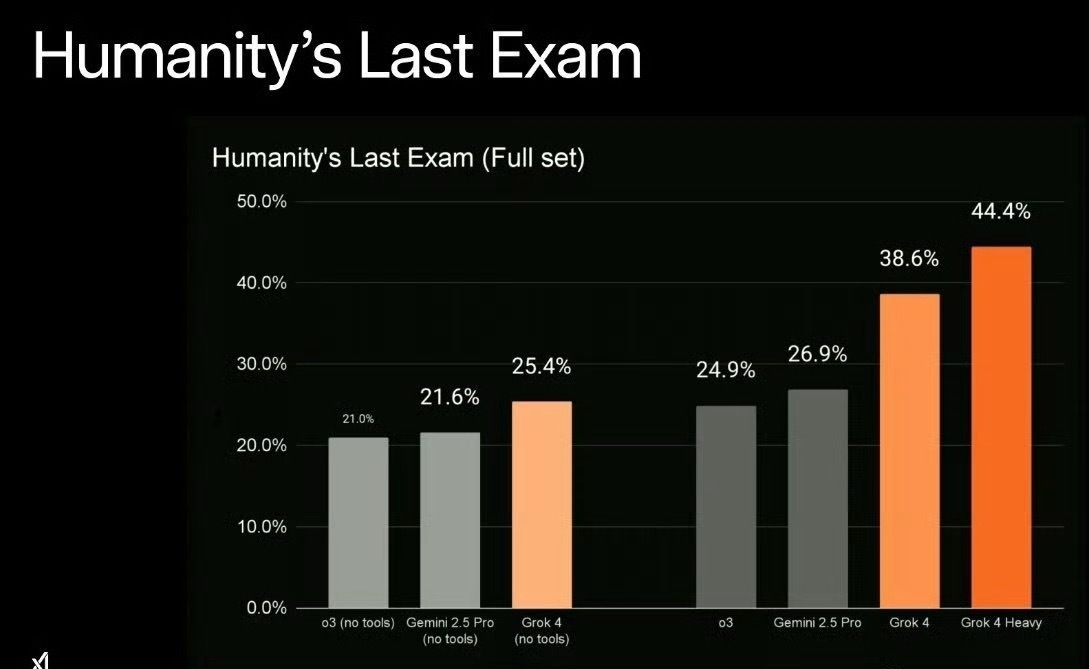
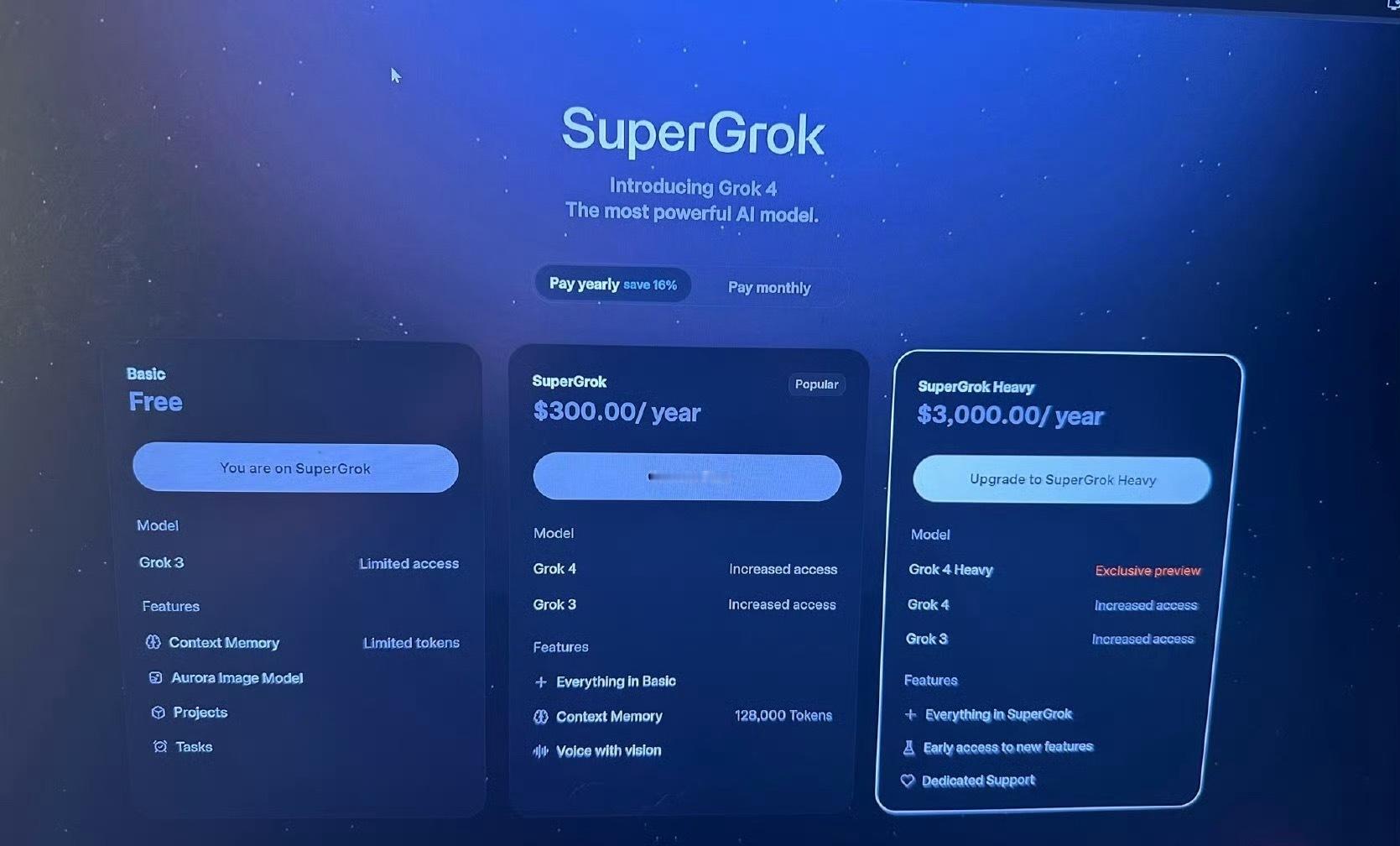
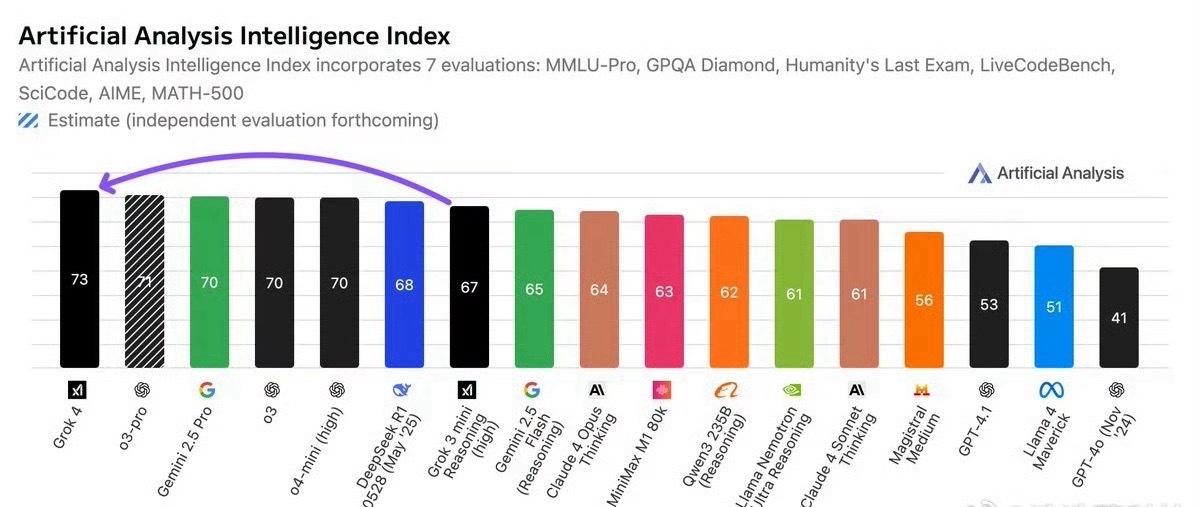
Grok4比DeepSeek强吗
Grok4 和 DeepSeek 均基于 Transformer 架构,但在具体技术原理上存在诸多不同,Grok4 侧重于通过动态架构和强化学习提升个性化交互,DeepSeek 则借助混合专家模型和分层注意力机制优化推理效率。
架构设计:
Grok4:采用自适应 Transformer 架构,运用层级可变深度技术,允许模型根据输入复杂度动态调整计算路径,以提高计算效率。
DeepSeek:基于 Transformer 架构,采用分层注意力机制,通过多层自注意力引入分层结构,更好地捕捉不同层级语义信息,在长文本理解上更具优势。同时,其 Sparse MoE 结构利用稀疏专家路由机制,仅激活部分专家网络,减少计算资源消耗。
训练策略:
Grok4:利用 PPO 强化学习算法,基于用户反馈进行强化训练,以提高对话质量。还通过上下文感知和强化学习驱动的用户画像建模,结合 X 平台数据,生成个性化回复。此外,采用 LoRA 技术,通过低秩矩阵分解,减少微调时的参数调整数量,使模型能快速适应特定领域任务。
DeepSeek:结合代码、技术文档、百科知识等多种数据源,使用基于损失权重调整的多任务学习,增强模型在多种任务上的通用性。同时,通过基于注意力的知识检索以及基于 Transformer 的文档级检索,广泛覆盖领域知识
推理方式:
Grok4:依赖 X 平台的实时数据流,采用基于 LLM 的信息过滤和基于自监督学习的语义匹配,实现个性化、动态化的信息推荐和实时交互。Grok4 还强调基于第一性原理进行推理,让 AI 从根本原理出发解决问题,而非仅依赖模式匹配。
DeepSeek:以混合专家模型为核心,结合动态路由机制,根据输入数据特征分配计算资源,提升推理效率。
多模态处理:
Grok4:是 xAI 首个在统一 API 下集成语言、视觉和编码功能的模型,实现了深度融合,能同时处理和理解多种类型的信息,如整合 SpaceX 星链数据的地图生成速度较快。
DeepSeek:主要聚焦于语言模型领域,虽可支持多源数据,但多模态相关公开信息较少,暂未提及有类似 Grok4 的深度多模态集成能力及相关应用。








用户13xxx08
此言差矣,模型的'壁界'已经被打破,只是目前只有少数人知道这个方法,随着时间的推移爆发只是随着秘密被公开而已