编辑|杨文
「你是否在雪山救过一只狐狸?」
「你是那只狐狸?」
「我是那只酱板鸭!」

最近网上冲浪,刷到了大量「雪山救狐」的 AI 二创视频。
这原本是个很老套的民间故事,樵夫大雪天救了一只快冻僵的狐狸,喂它吃的、帮它取暖,等着狐狸日后化成人形来报恩。
结果网友拿 AI 把剧情狠狠反转,樵夫等来的不是什么漂亮狐仙,而是当时随手留下的酱板鸭、核弹等离谱的东西,它们全都成了精找上门来复仇。

更有人将其与近来大火的 OpenClaw(江湖俗称「小龙虾」)联动,吐槽「小龙虾」听不懂人话。

视频来自视频号博主「随波逐流 3.0」
AI 视频生成的门槛,已低到人人皆可玩梗的程度。
就在大家忙着整活时,一家中国公司的 AI 视频模型却悄悄打到了全球第一。
今年 2 月,昆仑万维旗下 SkyReels-V4 Preview 版,在权威第三方评测平台 Artificial Analysis 的全球视频生成排行榜中登上全球第二,超越了 OpenAI 的 Sora 2 和 Google 的 Veo 3.1。
不到一个月,SkyReels-V4 在文生视频(带音频) 榜单中登顶全球第一,超越 Sora 2、Veo 3.1、Seedance 2.0 等一众国际顶尖模型,成为全球 AI 视频生成能力最强的大模型。
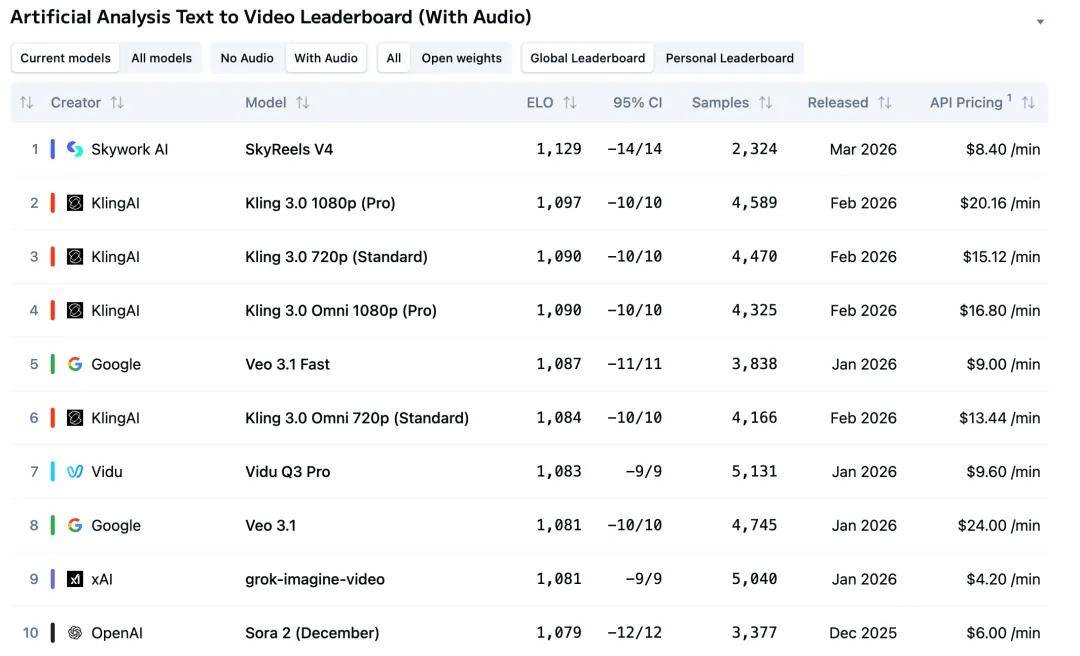
图片来源:Artificial Analysis 榜单
Artificial Analysis 是目前业内最具公信力的 AI 模型评测平台之一,其视频榜单采用公开竞技场机制,由全球真实用户进行盲测对比,通过大量 Elo 积分制两两比较计算排名,更能反映模型在真实场景中的综合表现。
据了解,SkyReels-V4 将于 3 月 27 日在中关村论坛正式亮相。
官网链接:https://www.skyreels.ai API 链接:https://www.skyreels.ai/api-platform出片实录:AI 短剧的门槛又低了一截
相比于上个版本,SkyReels V4 通过全模态强化学习大幅提升了模型的语义理解和整体逻辑能力,并新增多帧参考与网格参考两项高阶任务,重点补强了角色一致性和长叙事视频的生成稳定性。
先来看看它的基础生成能力。
这段多镜头战争戏的提示词比较复杂,从城市天际线的航拍俯冲,到街道上的士兵冲锋,再到不同角色的中近景和特写,涉及 6 个镜头切换。
SkyReels-V4 整体完成度蛮高,镜头切换很有节奏,角色能在不同景别间保持外形一致,配乐和音效也随画面情绪自动适配。

下面这个赛博朋克飞船穿城的片段,需要摄像机始终锁定飞船,模拟跟拍视角,同时还原飞船穿行于楼宇时的剧烈滚转和蓝色尾焰光晕。
这类场景对速度感和光影氛围要求极高。生成结果中,飞船运动轨迹流畅,颇有科幻大片质感。

SkyReels-V4 同样支持首帧参考(图生视频)。
以 Hello Kitty 滑雪为例,模型既要保持角色的标志性外观,又要完成 360 度空中旋转、落地瞬间雪雾弥漫等复杂动作序列。
总体来看,模型对首帧的锚定能力相当稳定,角色在整段视频中保持连贯,未出现常见的「帧间漂移」,复杂动作切换也处理得干净。

Prompt:@图片 - 1 中的 @Hello-Kitty 猛然蹬离雪面,沿陡坡急速滑降,粉雪在身后飞溅。镜头动态跟拍,捕捉她冲上天然跳台腾空而起。此时,慢动作镜头中 @Hello-Kitty 在蓝天下完成完美的 360 度空中旋转,四肢舒展,滑雪板划出优美弧线。接着,镜头急切至低角度地面视角,@Hello-Kitty 急速下落,滑雪板深扎粉雪,激起大片雪雾几乎遮蔽画面。雪雾散去,@Hello-Kitty 稳稳站立,完美落地,身后是阳光下壮丽的连绵雪山。
AI 短剧近来炒得火热。DataEye 数据显示,2026 年短剧春节档 86.7 亿的总播放量中,AI 漫剧占比已接近三成,不少作品播放量突破亿次。
事实上,使用 SkyReels-V4 的多图片参考功能,上传男女主形象并写好提示词,便能制作一段多镜头对话短剧。

Prompt:这段具有冲突感的短剧画面展现了古色古香的室内博弈。视频建立在光影幽暗的室内空间,中景聚焦于 #演员_1,她神情局促地低头看着手中的白瓷茶盏。在她身侧,# 演员_2 侧头注视着她,背景是模糊的室内木质陈设,空间内萦绕着bgm深沉压抑且带有急促鼓点节奏的背景音乐,营造出剑拔弩张的紧张氛围/bgm。镜头随后切换至 #演员_2 的斜侧面特写,他神色冷峻,眉宇间带着审视,语速缓慢而有力地询问道,dialogue药方中的龙骨/dialogue,紧接着补充问,dialogue才几两/dialogue。此时响起sfx衣物摩挲的细微声响/sfx。随后视角转向 #演员_1 的面部特写,她不安地皱起眉头,眼神闪烁,用略带迟疑且颤抖的声音回答,dialogue好像... 好像是二两吧/dialogue。紧接着画面再次切回至 #演员_2,他保持静止,用深邃的目光锁定对方,等待其后续说明。最后镜头又一次转回 #演员_1 的近景,她避开了对方的视线,神情越发慌乱,小声辩解道,dialogue时间太久,有点记不清/dialogue,双手因紧张而微微收紧。
在这段古装戏中,男主的审问语气和女主慌乱神情通过面部微表情和手部动作得到细腻呈现,台词口型也完全对得上。

SkyReels-V4 还能生成多语言台词,英语、法语、日语乃至台湾腔,均能驾驭。

Prompt:电影级的镜头语言下,场景展开于一间光影迷离、氛围感十足的咖啡厅内。前景中是 @演员_2 的模糊背影,中景焦点对准了正在倾谈的 @演员_1。@演员_1 眼神中流露出真诚,神情略带疲惫地说道dialogueJ'ai besoin d'argent et puis de toute façon j'adore partir sur la route alors./dialogue。镜头切换至 180 度的反向角度,视角越过 @演员_1 的肩膀,清晰展现出 @演员_2 的面部特写。她双手捧着一个装有黄色柠檬片和白吸管的透明玻璃杯,目光审视而温柔,轻声询问dialogueVous jouez quoi ?/dialogue。紧接着,视角再次转换切回 @演员_1 的近景,背景中虚化的咖啡厅灯光如光斑般点缀。他神色自若地继续解释,眉宇间透着一丝艺术家的矜持,dialogueDe la guitare, du synthé. J'ai fait le conservatoire. Piano./dialogue。随后,画面再次切回反向角度的 @演员_2,她微微挑起眉毛,露出一丝意外且感兴趣的神情回应道dialogueAh bon ?/dialogue。整个序列通过精准的正反打剪辑,捕捉了两人细腻的情绪流。
它生成的法语版短剧片段,不仅正确执行了正反打的镜头逻辑,法语台词的口型同步精度也超出预期。

运动参考测试则直接上传一段舞蹈视频,外加一张小男孩和白狐的图片,让模型把舞步迁移到两个新角色身上。
结果显示,动作迁移后的视频在关键动作节点上与原视频保持了同步,角色风格迁移自然,整体运动节奏也没断裂。

此外,SkyReels-V4 还支持视频编辑,涵盖局部添加、区域删除、去台词、去水印等常见场景。
比如从一段电影片段中移除前景人物,同时完成背景修复。在 SkyReels-V4 的处理下,被移除区域的工作台得到了合理补全,没有出现明显的残影或拼接痕迹。

Prompt:Remove the person in a brown long-sleeve shirt seated at the workbench and the person in a black t-shirt walking toward the workbench from @video_1.
多帧或网格图参考是此次 SkyReels-V4 新增的能力,也是最贴近短剧工业化生产场景的功能。
在多帧图参考中,上传三张绿色幼龙与红色火龙的剧情关键帧,要求模型按照图片顺序生成。SkyReels-V4 在三个关键节点上忠实还原了图片内容,并自然「脑补」出中间的过渡画面。

多帧图参考。Prompt:视频开始于一只绿色幼龙和红色火龙在篝火旁对话。随后镜头切换至 @图片 - 1,绿色幼龙从红色火龙手中递过一份证书;随后镜头切换至 @图片 - 2,绿色幼龙喷出火焰烧毁了证书;最后镜头切换至 @图片 - 33,绿色幼龙和红色火龙露出沮丧的表情。

或者直接上传一张动漫四格图,让 SkyReels-V4 按从上到下、从左到右的顺序展开成动画短片。
模型对四格叙事节奏的理解准确,生成的短片叙事连贯,没有把四格简单理解成四个孤立镜头的拼接。

Prompt:根据 @图片 - 1 中的动漫情节,按从上到下、从左到右的顺序自然过渡展开,生成一个动画短片。

技术解读:两大核心突破,撑起登顶底气
SkyReels-V4 在 Preview 版基础上进行了全面升级,沿用双流架构解决音画同步核心问题的同时,也带来了两大并行核心变革。
其一,全模态强化学习体系全面升级。 传统扩散模型长期存在一个行业痛点,重局部像素生成,轻整体语义逻辑、物理常识与叙事连贯性。针对这一问题,SkyReels-V4 搭建了一套完整的强化学习体系。
一方面构建全模态语义 Reward 模型,覆盖文生视频、图生视频、视频编辑、音视频对齐全场景,为生成提供全局精准的实时反馈;另一方面采用阶梯式课程强化学习路径,从分辨率与时长、任务复杂度、数据难度三个维度循序渐进,让模型由简入繁掌握复杂能力,最终实现 1080p、15 秒商用长序列生成,以及多任务大一统的能力框架。
该体系还带来了极强的跨任务泛化性,模型习得的视频生成底层通用规律,可在不同任务间自由迁移。
其二,新增两大高阶参考任务。 本次升级新增关键帧参考与九宫格参考能力,全面提升视频生成的稳定性与灵活性。关键帧参考能力可基于用户给定的多节点关键帧,精准推演逻辑严密、动作连贯的中间画面,实现极强的时空补完能力;专为短剧生成打造的九宫格参考能力,支持用户上传至多 9 张剧情关键帧,模型可稳定提取并保留角色特征与场景风格,生成逻辑完整、角色与场景全程连贯的叙事视频,直接解决了短剧生成中角色走形、场景跳跃的行业痛点。

论文地址:https://arxiv.org/pdf/2602.21818
在架构设计上,SkyReels-V4 采用了创新的 MMDiT 结构。该结构包含两个并行的分支,分别负责视频合成与音频生成。
为了实现音画同步,模型在每个 Transformer 块中都嵌入了双向跨注意力(Cross-Attention)机制,确保音频特征能够感知视觉动态,反之亦然 。
此外,模型共享了一个基于多模态大语言模型(MLLM)的强力文本编码器,使其能够理解包括文本、参考图、参考视频片段在内的极其复杂的组合指令。

技术上的另一大亮点,是其统一的通道连接(Channel Concatenation)公式。研发团队巧妙地将图像转视频、视频扩展及编辑任务建模为不同配置下的「视频补全」问题。通过将噪声视频潜向量、条件帧和二进制掩码在通道维度进行拼接,模型可以在同一个界面下灵活处理多种生成工作流。
同时,模型引入了带偏移的 3D RoPE ,不仅解决了不同时域分辨率的音视频对齐问题,还使得模型能够从参考视觉中进行「上下文学习」,精准捕捉人物身份特征或复杂的运动轨迹。
针对高分辨率长视频生成带来的计算挑战,论文提出了一种极具工程参考价值的高效方案:基础模型首先生成低分辨率的完整序列和高分辨率的关键帧,随后由专门的超分辨率与帧插值模块进行细节重塑。该帧插值模块引入了视频稀疏注意力(VSA)机制,通过分级聚合时空特征,在维持硬件运行效率的同时,将注意力计算成本降低了约 3 倍。
实验结果显示,SkyReels-V4 在 Artificial Analysis Arena 等公开榜单中取得了当前 SOTA 成绩。在面向音视频综合素质的 SkyReels-VABench 人类评估中,其在指令遵循能力、运动质量以及多镜头叙事连贯性方面,甚至超越了部分知名闭源商业系统 。
SkyReels-V4 的成功,不仅在于电影感的画质呈现,更在于它通过统一的底层框架,为多模态内容创作提供了一套功能全面、高度可控的生产工具。
结语
一个模型能打赢榜单,证明它在评测维度上足够强,但能不能真正产业落地,取决于它是否解决了真实生产流程里的问题。
昆仑万维将 SkyReels-V4 直接嵌入自己的内容生产中。自 2024 年 12 月宣布 5 亿美金入局海外短剧以来,仅用一年便实现跨越式突破。旗下付费平台 DramaWave 与免费平台 FreeReels 携手站稳海外短剧第一梯队,MAU 突破 8000 万,月流水超 4000 万美金。DramaWave 平台漫剧模块上线数月,累计上架近千部 AI 剧,凭借千万级月活与数百万美金的月收入,强势占据海外 AI 剧市场龙头地位。
SkyReels-V4 的能力已覆盖短剧、影视、广告、数字人等主流内容形态,统一的生成接口意味着同一套基础设施可以服务不同的生产场景,无需再为每种需求单独搭建技术栈。
从更大的视角来看,这次登顶发生的时间节点颇具意味。2 月 Preview 版全球第二、3 月升级版全球第一,前后不到一个月。背后的压力不难想象,全球头部 AI 实验室都在这条赛道上高强度投入,几乎每隔几周就有新模型上线刷新排行。
在这样的节奏里,中国团队能以如此步频持续推进,本身就是一种能力的证明。
文中视频链接:https://mp.weixin.qq.com/s/FxXd3Ay8NknHuDk-QbX7GA