北大、清华和DeepSeek联合发的新论文《DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference》arxiv.org/abs/2602.21548以下为AI解读:DualPath 是一个面向多轮代理 LLM 推理的系统,核心改动在于把命中 KV-Cache 的加载从“单一路径”扩展为“双路径”:除了传统的“存储→Prefill 引擎(PE)”,还允许“存储→Decode 引擎(DE)→经由计算网络 RDMA 转发给 PE”,并配合全局调度在两条路径间动态分流;系统还包含以 CNIC 为中心的流量管理以隔离 KV-Cache 传输与模型执行通信,从而在生产代理式负载上把离线吞吐提升最高到 1.87×、在线吞吐平均提升到 1.96×。
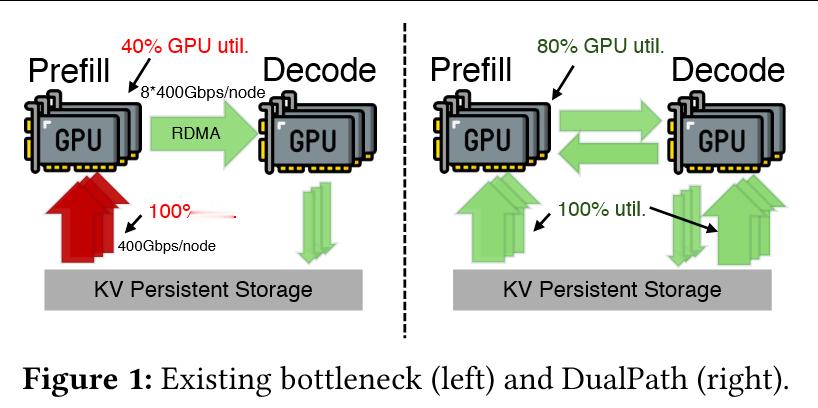
它存在的意义在于解决代理式推理从“算力瓶颈”转向“KV-Cache 存储 I/O 瓶颈”后的结构性失衡:在常见 Prefill/Decode 解耦架构里,KV-Cache 往往只由 PE 侧从外部存储读取,导致 PE 的存储网卡(SNIC)长期打满,而 DE 侧 SNIC 闲置,整体吞吐被 PE 侧存储带宽卡死;DualPath 通过利用 DE 侧闲置的存储带宽并借助更高速的计算网络回传,把原本集中在 PE 的 I/O 压力“摊开”,从根上缓解存储带宽瓶颈并提升端到端性能。
同类工作中,Mooncake/TokenLake 走的是“把 KV-Cache 缓存在分布式 DRAM 前缀池/内存池”路线,目标是提高命中与减少外部存储访问;但论文指出 Mooncake 在内存受限(如 RL rollout 时 DRAM 被训练状态占用)或工作集极大(在线服务)时会受成本/容量约束,而 DualPath 直接面向存储后端,通过在所有引擎间均衡 SNIC 读流量来提升有效存储带宽,并显著降低对 DRAM 的依赖;此外,DualPath 也可以叠加中间层 DRAM cache,但论文认为增益有限,强调其主要价值在“跨引擎汇聚与调度存储带宽”而非“加大缓存层”。
HOW I AI