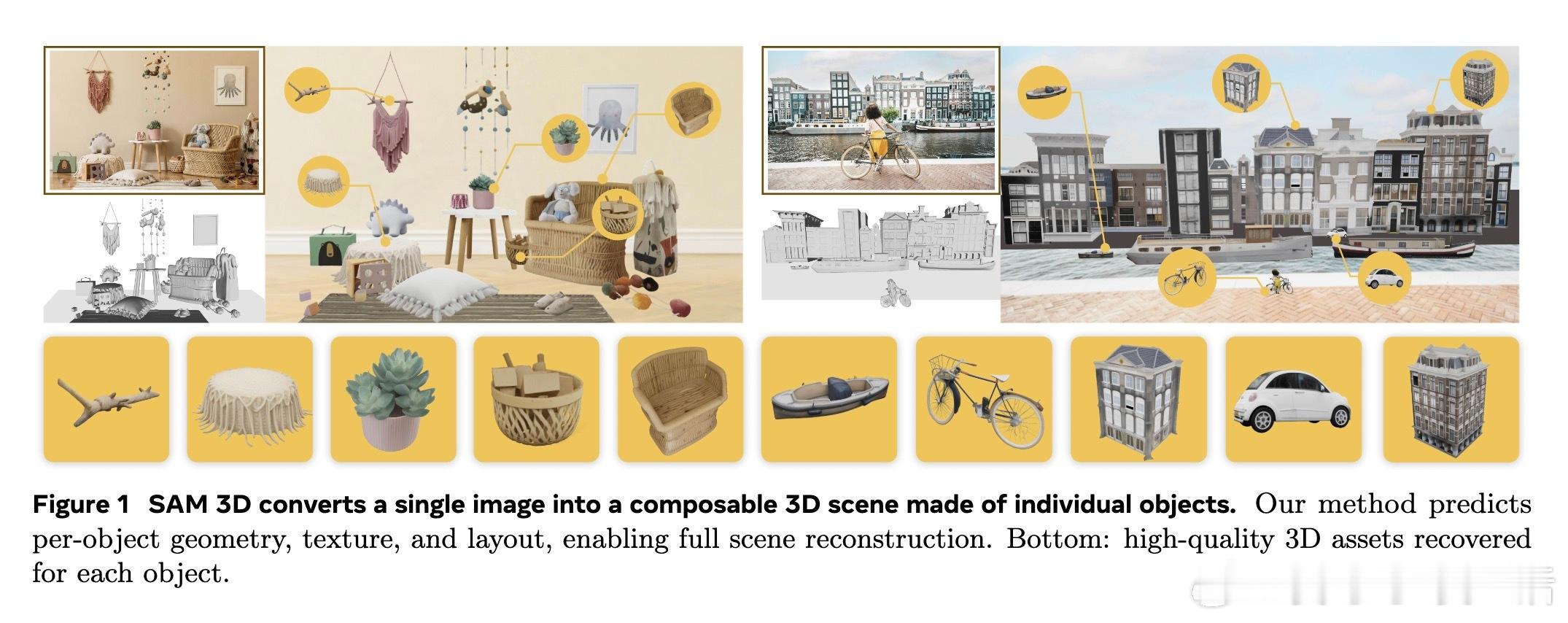
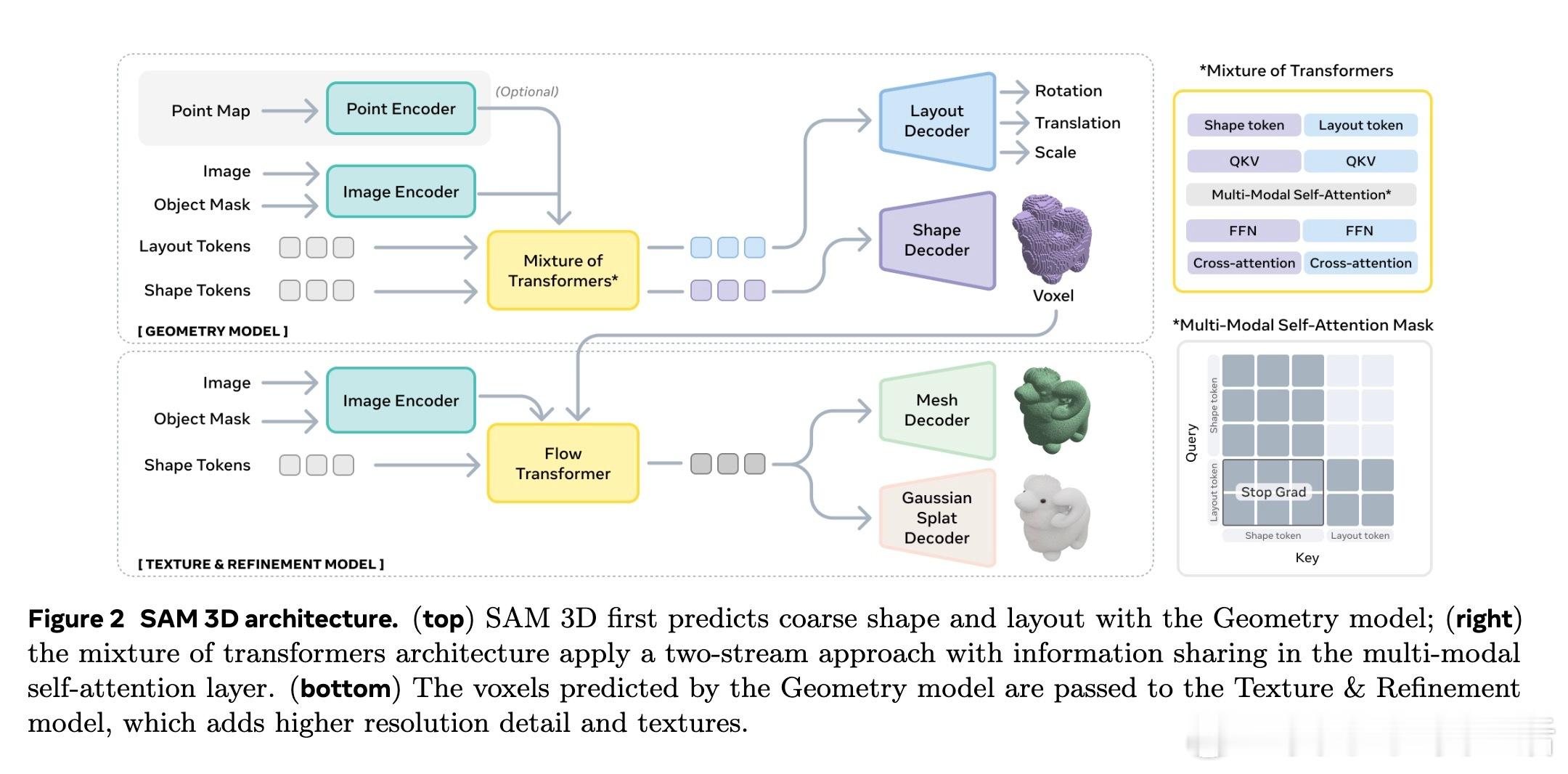
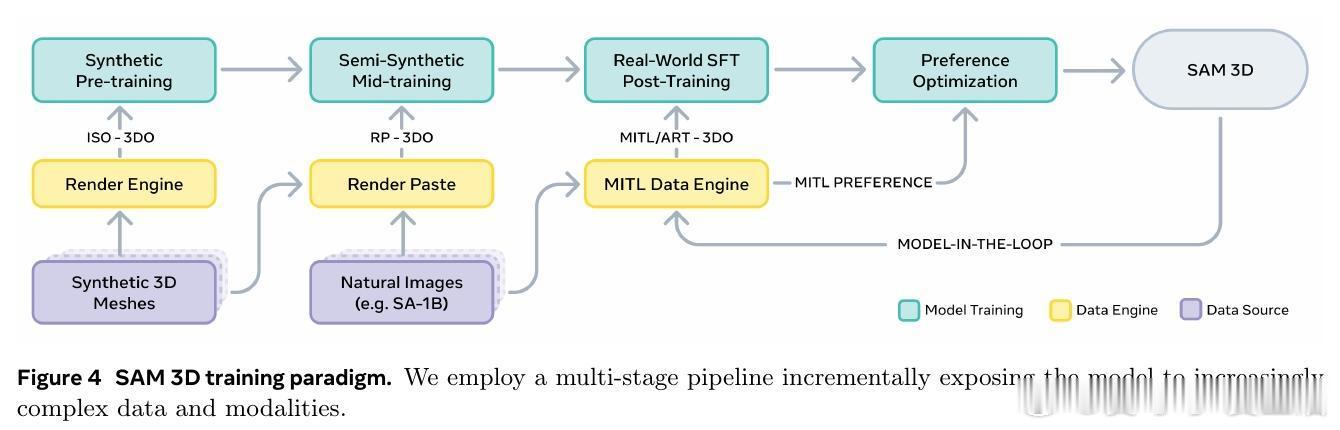
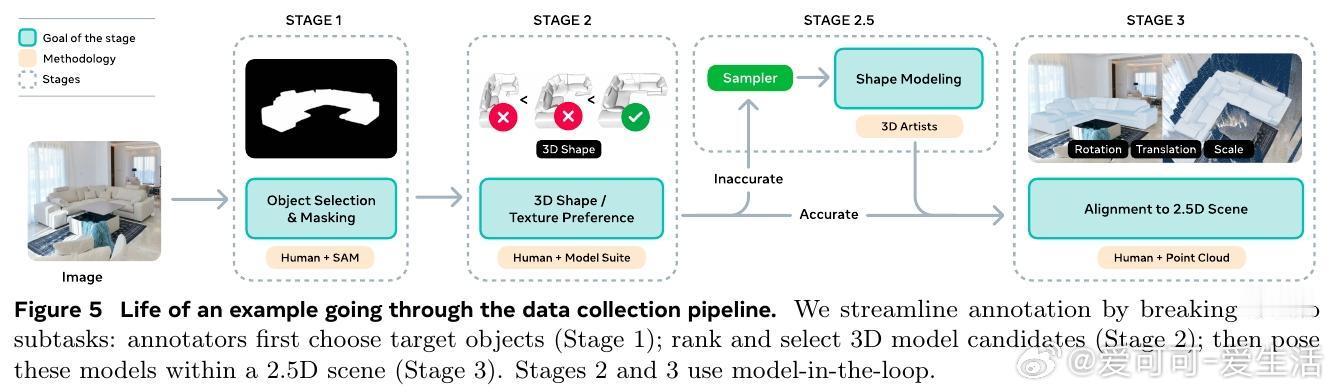
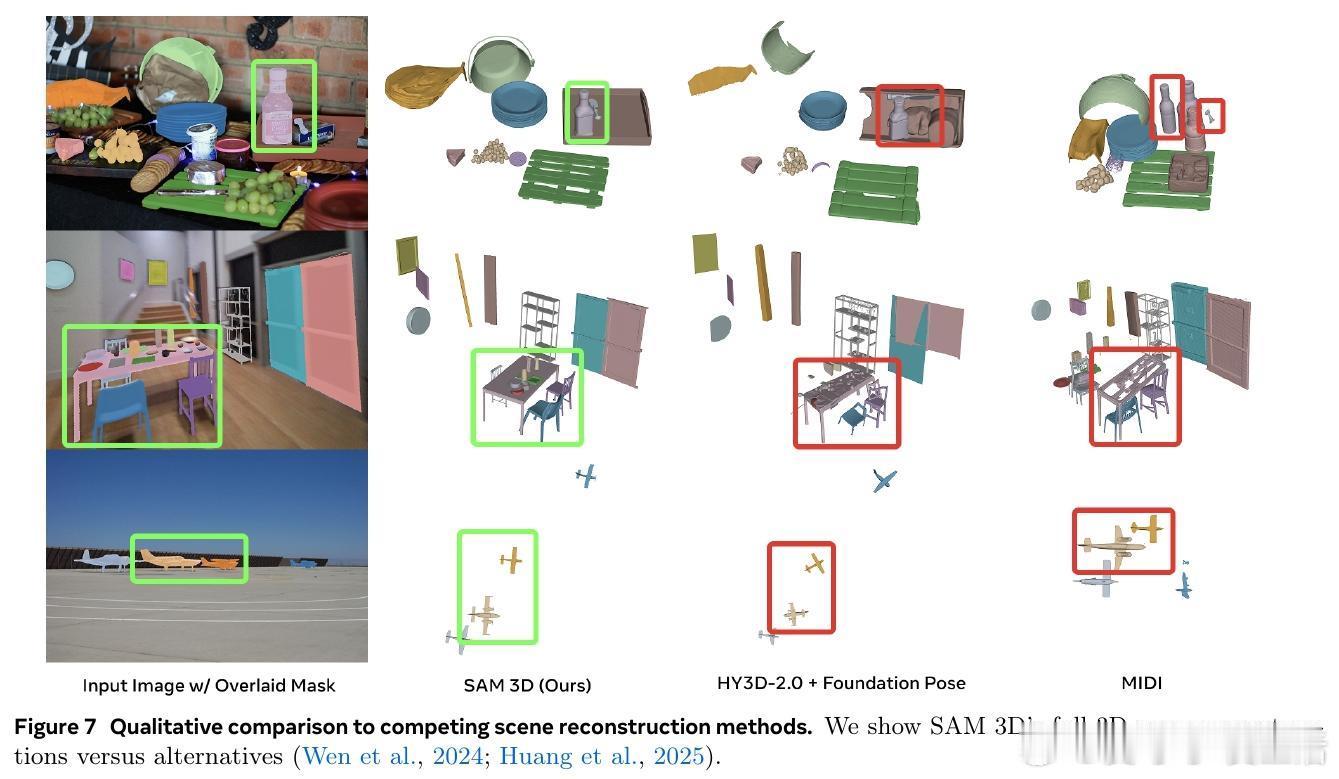
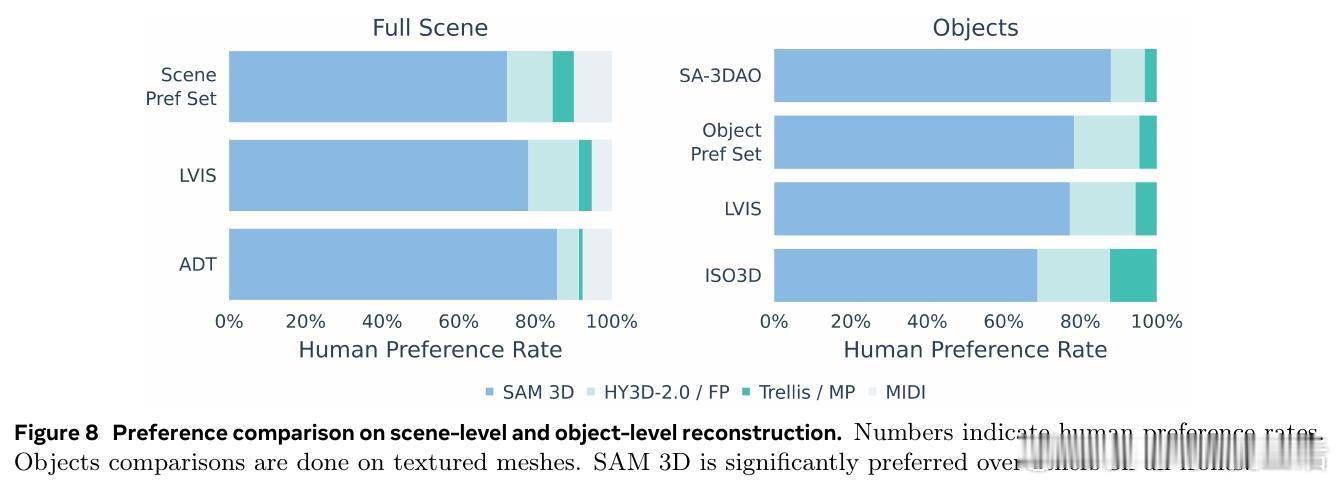
[CV]《SAM 3D: 3Dfy Anything in Images》S 3 Team, X Chen, F Chu, P Gleize... [Meta Superintelligence Labs] (2025) 我们隆重推出SAM 3D——一款革命性的单张图片3D重建基础模型,能够精准预测物体的三维形状、纹理与空间布局,实现在复杂自然场景中的全方位3D视觉感知。 传统三维重建多依赖多视角几何信息,而SAM 3D从心理学“单张图片立体线索”出发,结合语义识别与上下文推理,突破单视角3D重建瓶颈。核心在于:识别即重建,即使面对未曾见过的新物体,也能基于部件复用完成3D恢复。 为了突破“3D数据鸿沟”,团队设计了人机协同的数据采集引擎:利用合成场景预训练,半合成场景中训练模型识别遮挡与布局,再通过人类与模型循环迭代,筛选出最优3D模型与姿态,结合专业3D艺术家打造高质量真实世界数据。迭代的数据引擎极大提升了模型在自然图像中的表现和泛化能力。 SAM 3D架构采用两阶段生成: 1. 几何模型联合预测粗糙形状与姿态(旋转、平移、尺度); 2. 纹理与细节精炼模型基于激活体素,细化几何细节并恢复纹理。 输入编码融合局部裁剪视图和全景图像,支持可选点云信息,实现对复杂场景的多目标3D构建。 训练采用多阶段策略: - 预训练:海量合成孤立3D物体(270万模型,24视角渲染,2.5万亿训练token),建立基础形状语义库; - 中期训练:引入半合成遮挡合成数据(RP-3DO,6100万样本),注重遮挡鲁棒与遮罩跟随; - 后期训练:在真实图像上进行监督微调与偏好优化(DPO),通过人机循环采集千万级真实3D标注,持续优化模型输出质量与人类审美一致性。 为推动社区研究,发布了涵盖1000幅真实场景图像与专业艺术家标注3D模型的SA-3DAO基准,涵盖建筑、动物、日用物品等多样对象,真实反映自然环境复杂性。 评测中,SAM 3D在真实图像单物体3D重建上,超过现有最优方法,F1.01、Chamfer距离等指标显著领先,且在大规模人类偏好测试中以至少5:1胜率碾压竞品。多目标场景重建中,用户偏好高达6:1,显示其强大场景理解与布局预测能力。 此外,SAM 3D支持快速推理:采用流匹配蒸馏技术将推理速度提升10~38倍,兼顾效率与精度。 这项工作不仅展示了深度融合图像语义与三维空间理解的潜力,也为机器人感知、AR/VR、游戏制作、影视特效乃至交互媒体开启了新篇章。未来可望通过提升分辨率、联合多物体建模及纹理与姿态联合优化,进一步提高细节还原与物理合理性。 详细体验与开源资源请访问: 在线演示:www.aidemos.meta.com/segment-anything/editor/convert-image-to-3d 代码库:github.com/facebookresearch/sam-3d-objects 官网:ai.meta.com/sam3d 不再只是2D图像,从此任何照片都能“3D化”,让视觉世界立体鲜活,SAM 3D为真实世界的三维理解树立了新标杆。 论文地址:arxiv.org/abs/2511.16624