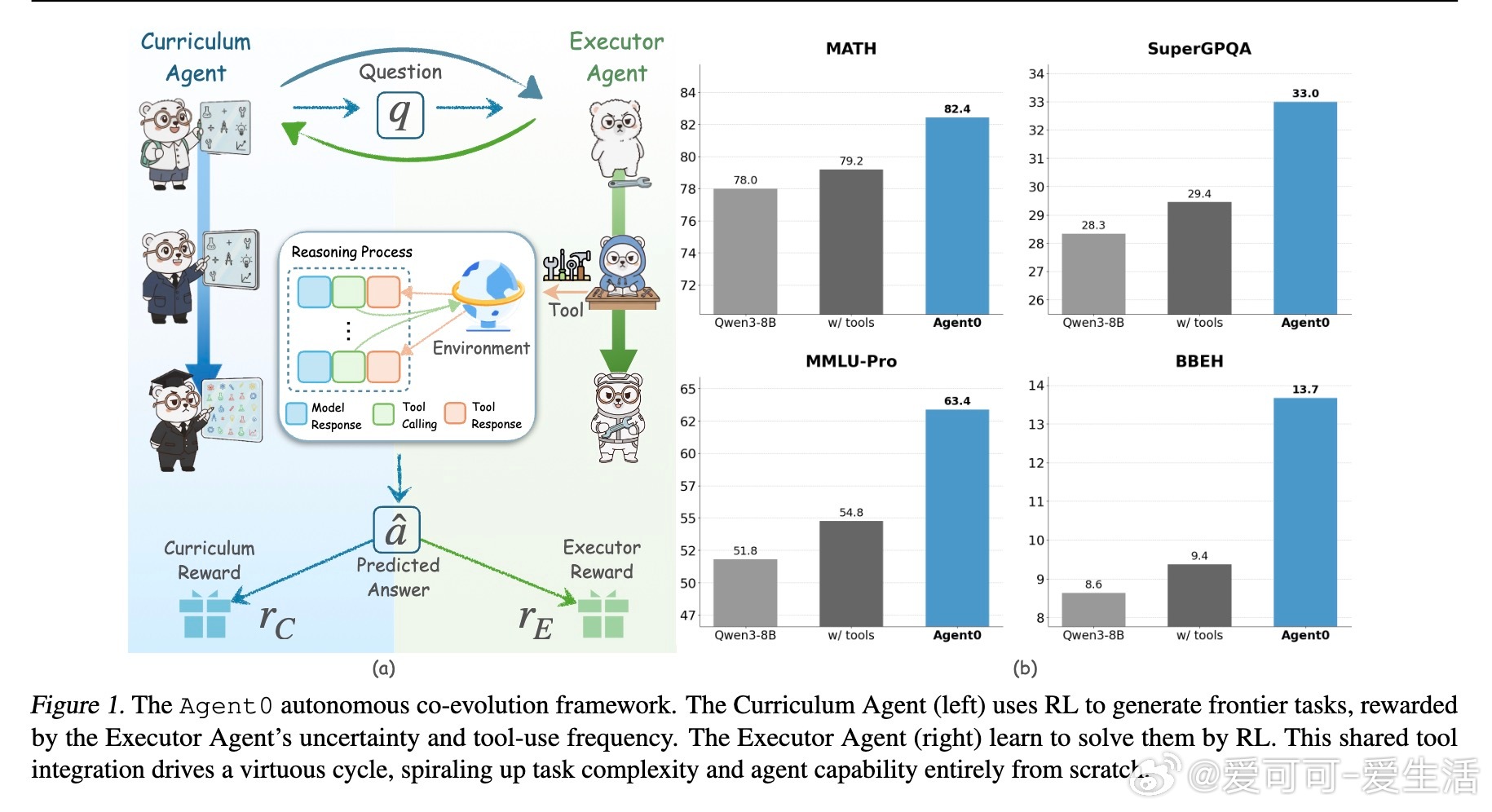
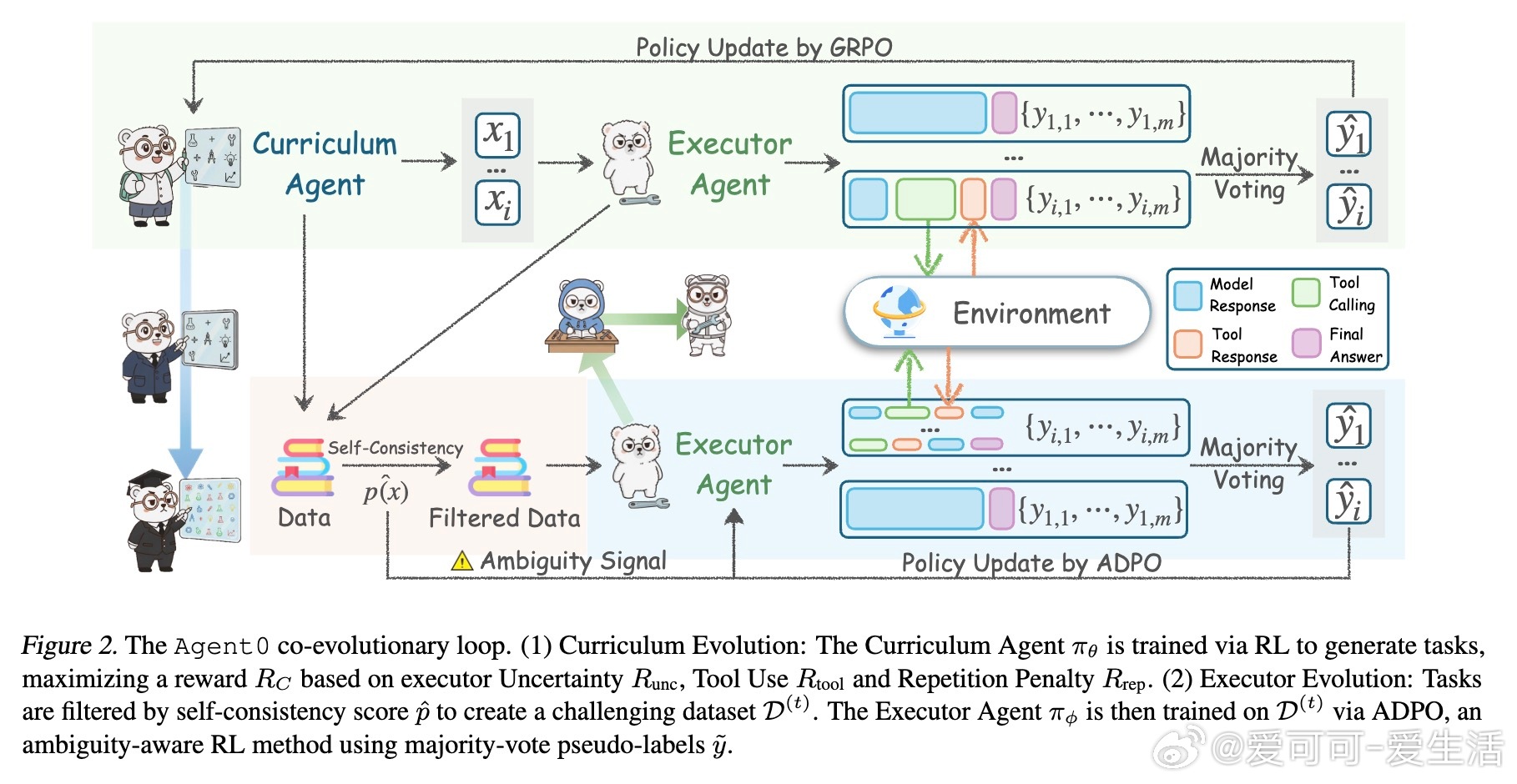
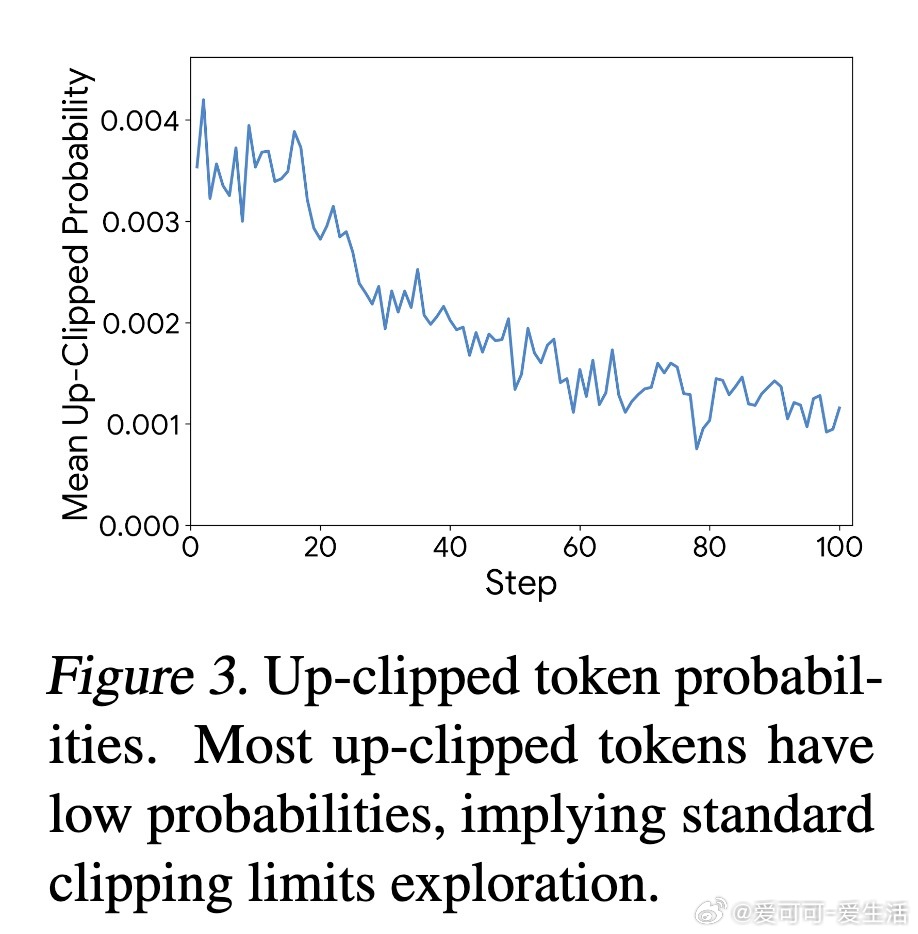
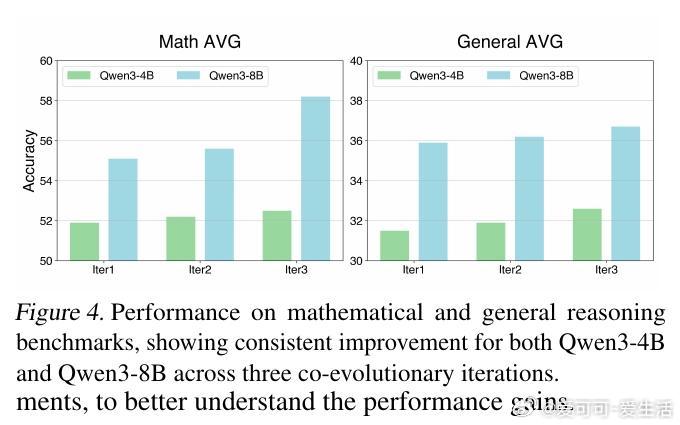
[LG]《Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning》P Xia, K Zeng, J Liu, C Qin... [UNC-Chapel Hill] (2025) 在AI训练领域,依赖大量人工标注数据成为瓶颈。本文提出了Agent0框架,开创性实现了无需任何人类数据的自主进化语言模型代理。Agent0由两个基于同一基础大模型初始化的智能体组成:课程代理负责设计逐步升级的挑战任务,执行代理则用强化学习解决这些任务。核心创新是引入代码执行工具,增强执行代理的推理能力,反过来推动课程代理生成更高阶的、依赖工具的任务,形成自我强化的螺旋上升循环。该框架支持多轮交互,使生成的问题更贴近真实复杂场景。训练中,课程代理以执行代理的“困惑度”和工具调用频率作为奖励,执行代理则根据课程代理生成的任务及其伪标签进行训练。为解决伪标签噪声和探索限制,Agent0设计了模糊度动态策略优化(ADPO),按任务难度动态调整训练信号和策略更新范围,提升了学习稳定性和效率。实验证明,Agent0在数学推理基准上使Qwen3-8B-Base模型性能提升18%,在通用推理任务中提升24%,显著超越包括R-Zero、Absolute Zero及Socratic-Zero在内的多种无监督或少监督自演化方法。多轮交互和工具整合被证实对提升复杂推理能力至关重要。消融实验显示,课程代理训练、工具奖励、多轮推理及ADPO均为性能提升的关键因素。Agent0展现了从零数据自主进化的可扩展路径,不再受限于人类知识和数据标注速度。其成功在于构建了工具赋能的协同竞争机制,智能体在挑战与解决中不断进步,推动AI能力跃迁。这一范式为未来打造更智能、更自主的AI代理奠定了坚实基础。详情与代码请见:github.com/aiming-lab/Agent0 论文链接:arxiv.org/abs/2511.16043