[CL]《Reinforcement Learning on Pre-Training Data》S Li, K Li, Z Xu, G Huang... [Tencent] (2025)
大型语言模型训练迎来新范式:RLPT——在预训练数据上用强化学习提升能力
• RLPT(Reinforcement Learning on Pre-Training data)突破传统监督学习瓶颈,直接在大规模无标注预训练文本上进行强化学习。
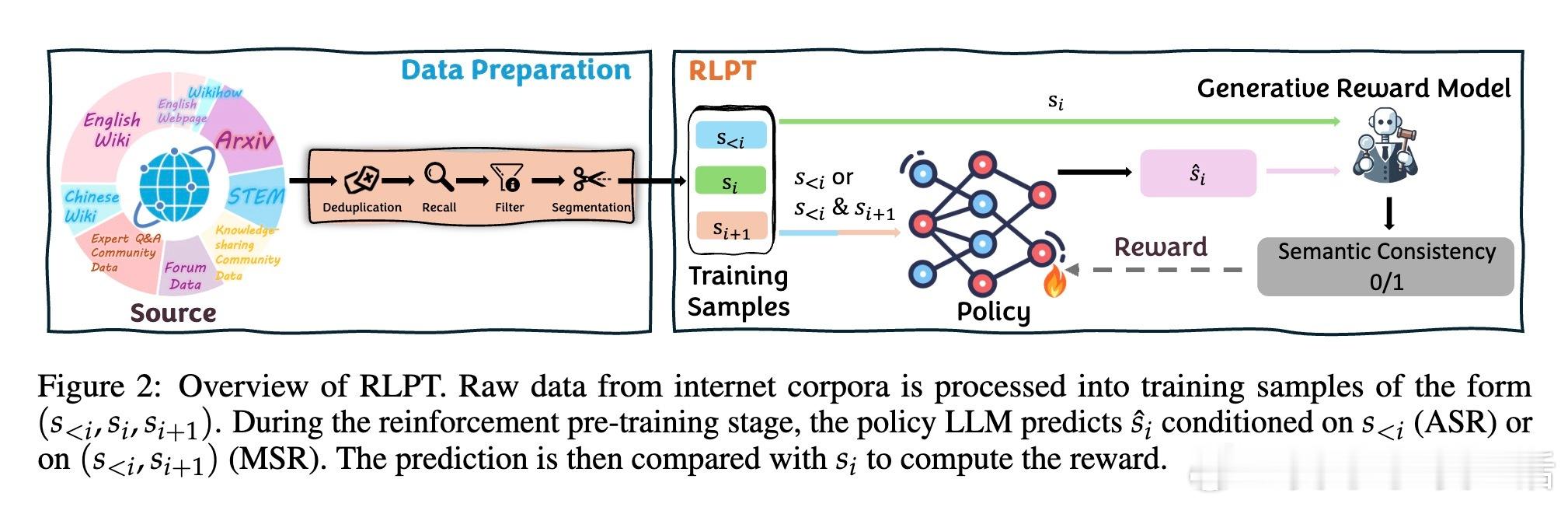
• 采用“下一段推理”自监督目标,通过预测上下文后的连续文本片段,自动生成奖励信号,无需人工标注即可扩展训练规模。
• 两大核心任务:自回归段落推理(ASR)促进模型预测下一个完整句子,和中段推理(MSR)利用前后上下文填补中间缺失段落,强化上下文理解与生成能力。
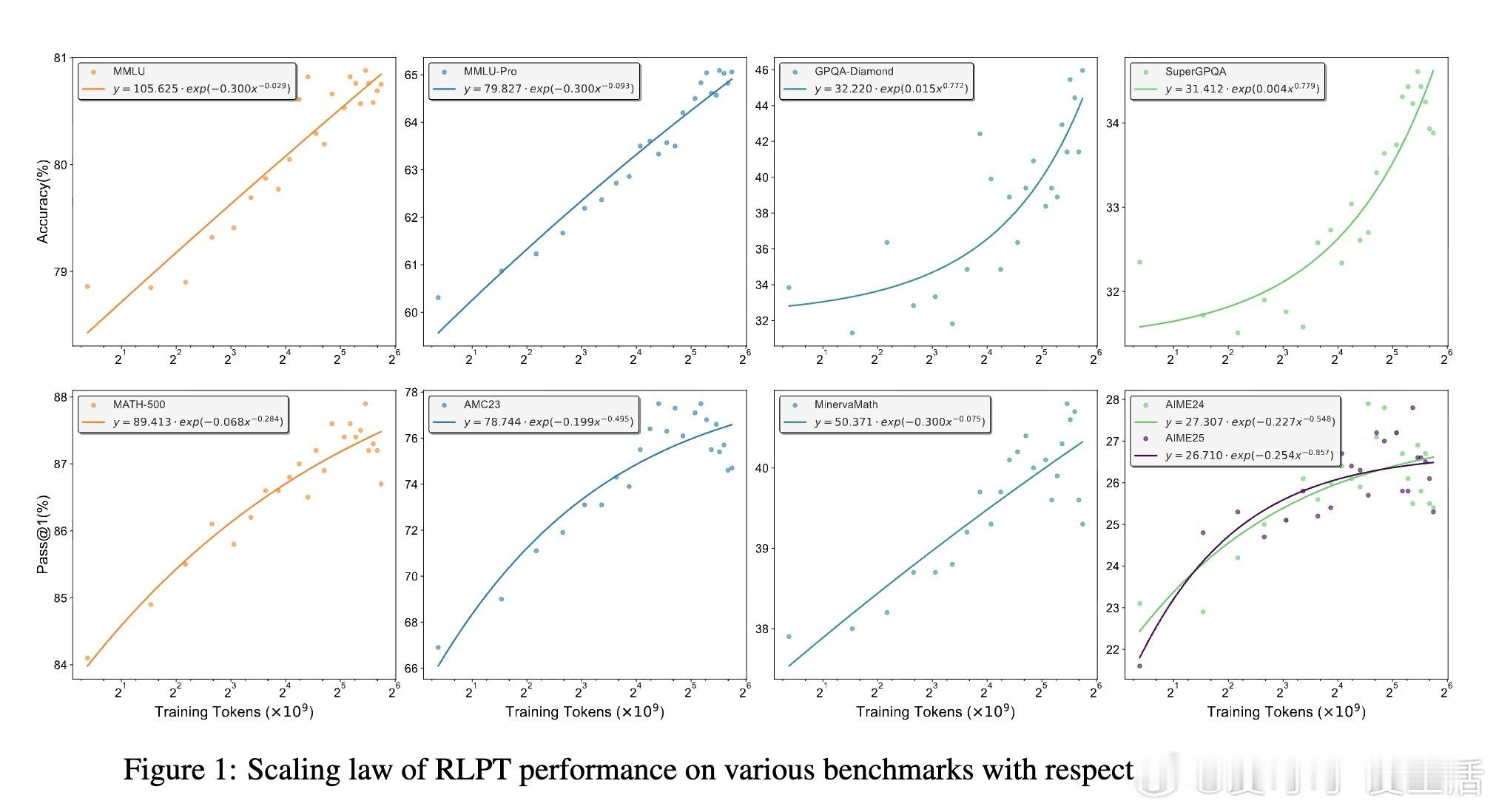
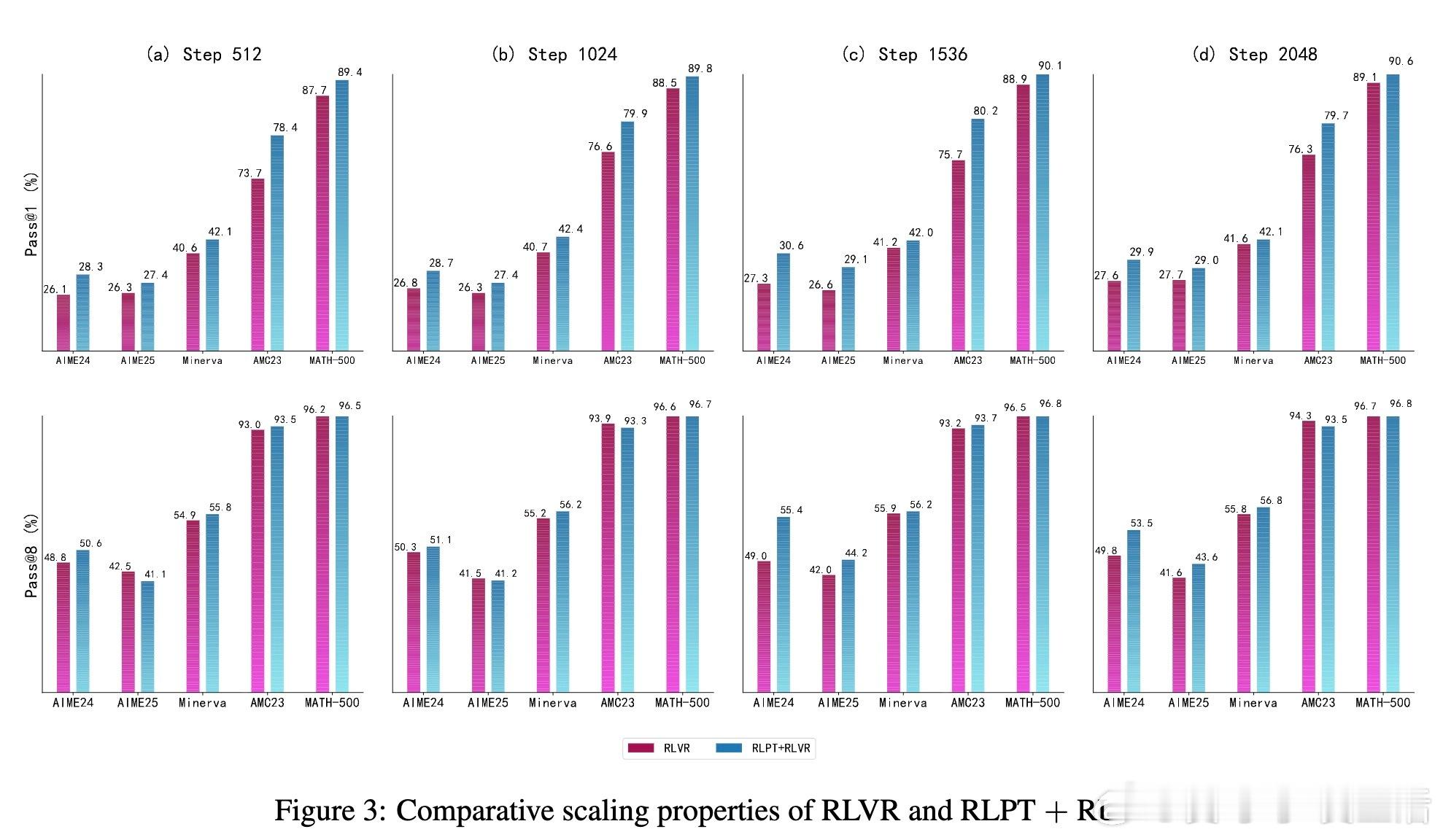
• 在通用领域和数学推理任务上均大幅提升表现,如Qwen3-4B-Base模型在MMLU、GPQA-Diamond等数据集提升最高达8.1个百分点,数学AIME24、AIME25 Pass• RLPT展现良好计算规模扩展性,性能随训练tokens指数增长,未来计算力提升带来持续收益潜力。
• 作为后续基于验证奖励强化学习(RLVR)的坚实基础,进一步拓展模型推理边界,提升复杂问题求解能力。
• 训练设计结合大规模去重、PII屏蔽及多阶段质量过滤,确保语料高质量与合规。
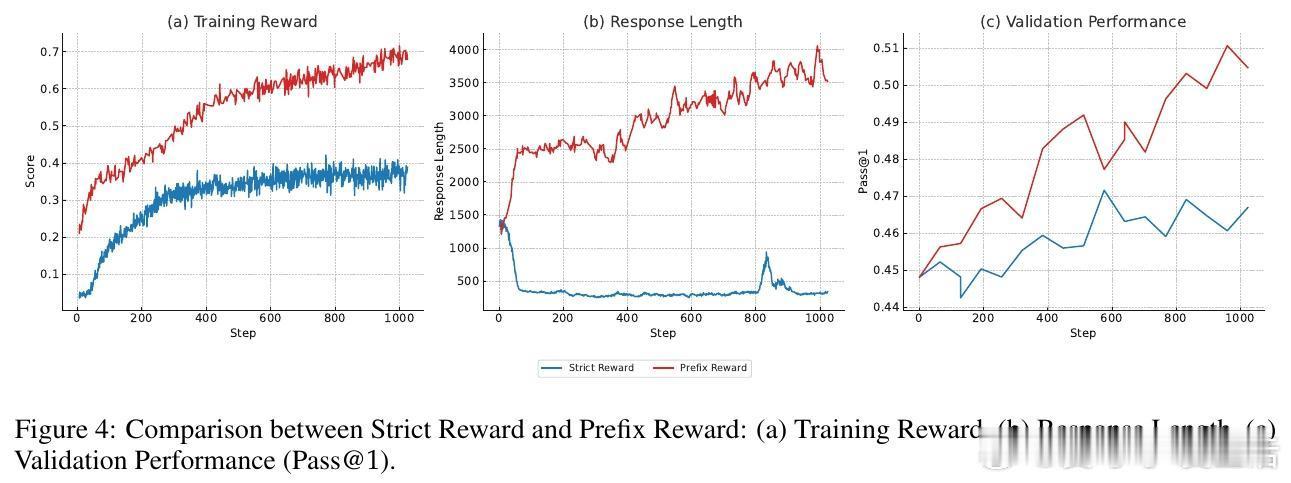
• 通过奖赏模型评估生成文本与真实段落的语义一致性,引入松弛的“前缀奖励”策略,解决生成文本跨度不一带来的训练不稳定问题。
• RLPT训练过程体现类似人类多步推理的思考轨迹:理解上下文→推断后续步骤→多方案探索→验证调整→输出答案,显著提升模型的深度推理能力。
心得:
1. 训练目标从单词级转向段落级,激发模型深层次语义理解与逻辑推理,远胜传统下一词预测。
2. 自监督奖励设计避免了人工标注瓶颈,极大提升了RL在预训练阶段的可扩展性和实际应用价值。
3. RLPT的多任务互补策略(ASR与MSR交替训练)有效融合了生成与理解能力,为复杂场景问答和代码补全等应用提供新思路。
详见🔗arxiv.org/abs/2509.19249
大模型训练强化学习自监督学习自然语言处理机器学习推理能力人工智能