做古籍研究这些年,我跑过 17 个省份的古籍数字化项目,试过的繁体字识别工具没有十几种也有七八种,云聪古籍是目前最让我离不开的一款。
大家都知道,简体字常用的也就六千多个,可古代繁体光是异体字就有十几万,普通工具根本扛不住,还得靠商用人工智能。云聪古籍在这方面的表现,是真能满足学术研究的严谨需求,用着特别放心。
先说说它的识别字数,这可是古籍 OCR 的核心本事。它支持 8.7 万个繁简汉字,像《国标 GB18030-2022》里收录的 27533 个常见繁体异体汉字,识别率稳定在 95% 以上,就连《国标 GB2312》里的 6763 个常用汉字,识别率更是能冲到 99.9% 以上。之前我处理一部清代方志,里面全是地方俗字和避讳字,换别的工具,我得逐字手动校正,费老劲了。
可云聪古籍能精准识别出八成以上的生僻字,剩下的用它内置的全字库字符查询工具补上就行,省了我太多功夫。这让我想起字节跳动 “识典古籍” 平台的理念,用 AI 把学者从基础转录里解放出来,专注研究本身,云聪古籍在这一点上做得特别到位。

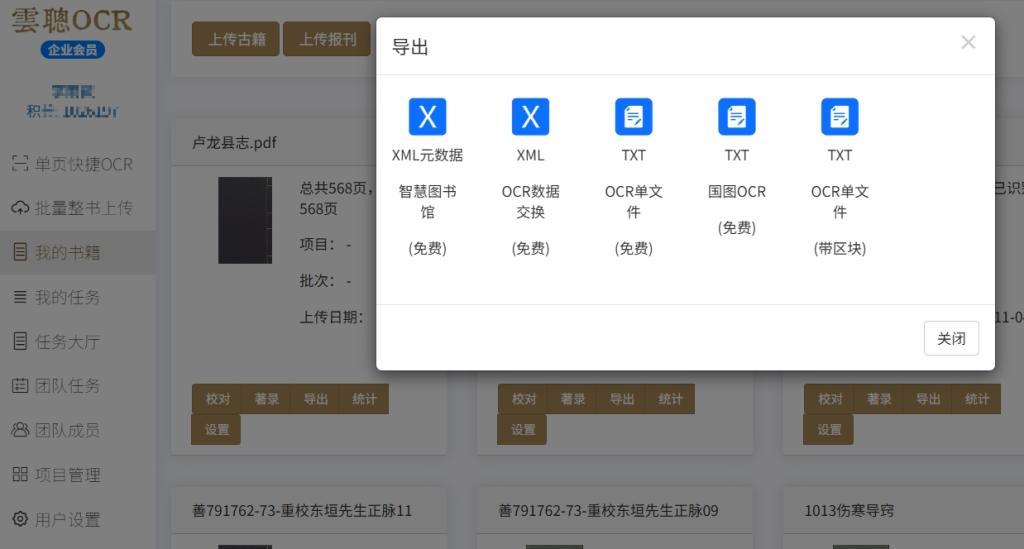
复杂版面处理能力也很关键。古籍排版向来折腾人,筒子页、半筒子页、三栏稿本,还有天头地脚的批注、正文里的双行小注,普通工具很容易把文字顺序弄乱,要么就把注释和正文混在一起。云聪古籍有个基于深度学习的版面自动分割引擎,不管是竖排横排混合的版式,还是上下栏布局,它都能精准识别文字区域、注释和插图,还能照着古籍从右到左、从上到下的阅读习惯输出文本。我去年处理一批明代军户文书,那些文书多是手写稿本,既有竖排正文,又有行间批注,之前用别的工具,批注总混进正文,越校对越上火。云聪古籍就完全没这问题,后续校对我只用盯着文字准不准,不用再花时间调格式,省心太多。

再说说影响识别效果的因素。我天天跟不同保存状况的古籍打交道,特别在意工具的实用性。云聪古籍能适应轻微页面歪斜、透光、透字这些常见问题,只要扫描时分辨率设到 300DPI 以上,亮度对比度调适中,识别效果就很稳。不过它也实在,会明确提醒你,文字倾斜超过 10°、页面污损严重时识别率会下降,建议先做预处理。去年我处理一批民国油印本,纸张泛黄还有霉斑,按它提示预处理后,识别准确率仍有 92%,大大减少了我的校对工作量。
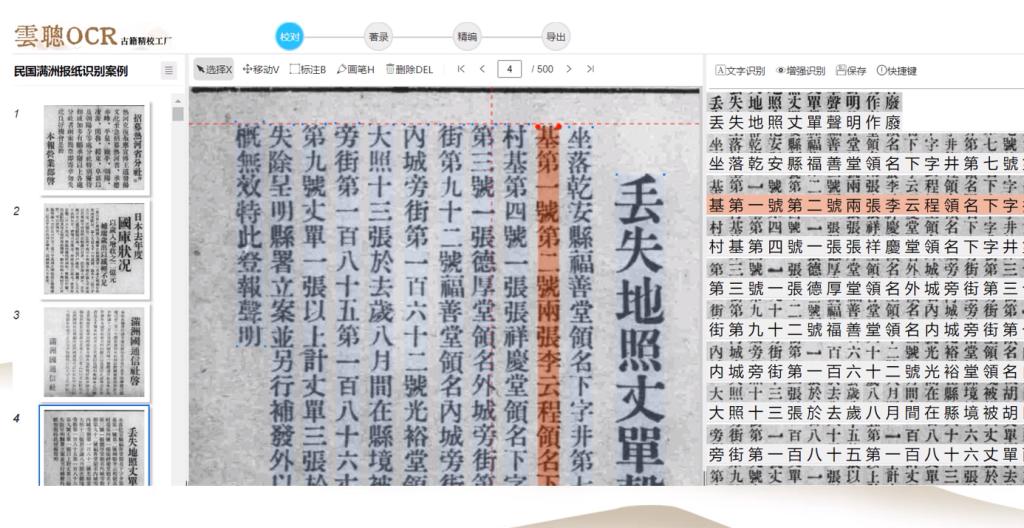
在文字与字体适配上,云聪古籍也考虑得很全面。它对明清的方体字、宋元以来的软字体,像颜体、欧体、柳体、赵体这些,识别效果都很好,尤其是笔画清晰、字形厚重的刻本,识别准确率几乎不受影响。对于楷宋体书写的写本、稿本、抄本,它也能较好适配,只是行书、草书风格的文字识别效果还有提升空间,不过这也是行业通病,云聪古籍已经算上游水平了。

我曾用它处理一部清代学者的手写日记,正文是楷书,识别率超过 90%,只有少数潦草批注需要手动修正,比我之前用的工具高效太多。
而且云聪古籍的细节设计特别贴合学术需求。它支持把竖版繁体转成横版繁体,能逐字一对一校对,还能全程用快捷键操作,符合现代阅读编辑习惯。企业版里的集字校对功能(内测中)也很实用,能把多篇文档里相同字符的图像集中展示,避免校对时陷入上下文判断的麻烦,我处理系列文献或校勘类工作时,这功能帮了大忙。更重要的是,现在很多高校和社科院都在用它,还能开正规发票,我们课题组每年的古籍数字化经费,都能合规报销,没什么后顾之忧。

对比字节跳动的古籍数字化过程,我觉得云聪古籍的核心优势就是 “懂学术”。它没搞那些花里胡哨的功能,而是把古籍识别最关键的准确率、版式兼容性、操作便捷性做到了极致。就像 “识典古籍” 用 AI 提升古籍整理效率一样,云聪古籍也用扎实的 OCR 能力,让我们这些基层学术工作者的数字化效率提高了数十倍。

顺带提几款我用过的其他工具:
汉典重光阿里汉典重光,是阿里达摩院与川大联合开发的,繁体字识别准确率高,覆盖 3 万多字古籍字典,擅长处理复杂刻本异体字,批量识别效率强,适合大规模繁体文献整理,还带有免费公益属性,挺良心的。
如是古籍,专注古籍文字识别,对繁体及异体字有较好适配,支持基础的版面分割与繁简转换,操作界面简洁,适合中小规模繁体古籍处理,能满足日常学术研究基础需求。

古籍酷,集成了繁体字 OCR 识别、自动标点和繁简转换功能,操作简单易上手,处理基础繁体文献很顺手,适合学生或古籍研究入门者,能快速完成初步转录,性价比不错。

千百 OCR,专注文字识别领域,繁体字识别效果稳定,支持多种格式导入导出,对常见繁体文本识别精准,操作界面简洁直观,使用门槛低,适合日常繁体文字识别需求。
个人观点,仅供参考