在一个炎热的夏日午后,小明坐在他常去的咖啡馆里,手里拿着一本关于最新人工智能发展的杂志。
他一边啜饮咖啡,一边被杂志上的一篇文章吸引住了,标题很吸睛:**"超越DeepSeek-R1的RL算法——CMU的新微调范式MRT来了"**。
一读之下,小明发现这篇文章讨论的是一种新的机器学习方法,名为“元强化微调”(MRT),它更高效、更智能,甚至能超越现在流行的强化学习算法DeepSeek-R1。
更绝的是,这个方法居然是由卡耐基梅隆大学的研究人员提出来的。
你可能会想,算法这种东西有什么好讨论的?
非常高深莫测,也没有什么日常联系。

但事实上,新算法的出现往往会带来实实在在的应用突破,就像智能手机让我们随时随地都能上网一样。
小明读到的这篇文章,告诉他MRT比传统的强化学习方法更高效,大大节省了计算资源,这就意味着未来我们能用更少的计算力完成更多的任务。
想象一下,你的智能音箱能更快地理解你的意思,你的手机地图能更精准地为你规划路线,这些都离不开更先进的算法支持。
MRT与传统的强化学习算法有一个显著的不同点。
传统的强化学习更多依赖于大量数据和长时间的训练,这就需要大量的计算资源。
而MRT通过在训练过程中不断优化自己,对于具体问题给出更合理的解决方案,这不仅提高了效率,还显著减少了必要的计算量。
这一突破对AI的发展具有重要意义,未来我们可能会看到更快、更智能的AI系统进入我们的生活。
小明的心中充满了疑问,到底CMU的团队是如何实现这样的优化的呢?
其实,MRT背后的原理非常巧妙。
CMU的研究团队发现,现有的语言模型在测试时往往浪费了太多计算资源。
他们希望模型能够在每一步计算中都充分利用之前的计算结果,而不是不断重复低效的探索。
就像在考试时,如果你能够运用之前做题的经验,就能更快地找到答案,而不是每次都得从头想起。
具体来说,CMU团队通过设计一种元 RL 学习问题的方式,让模型在每一次计算中都能够学习到最优解的可能性,加快了整个推理过程。
他们将模型的输出划分为多个片段,并通过检测每个片段的有效性来优化整个过程。
这样一来,模型不仅能够在最少的步骤内找到正确答案,还可以避免不必要的计算资源浪费。
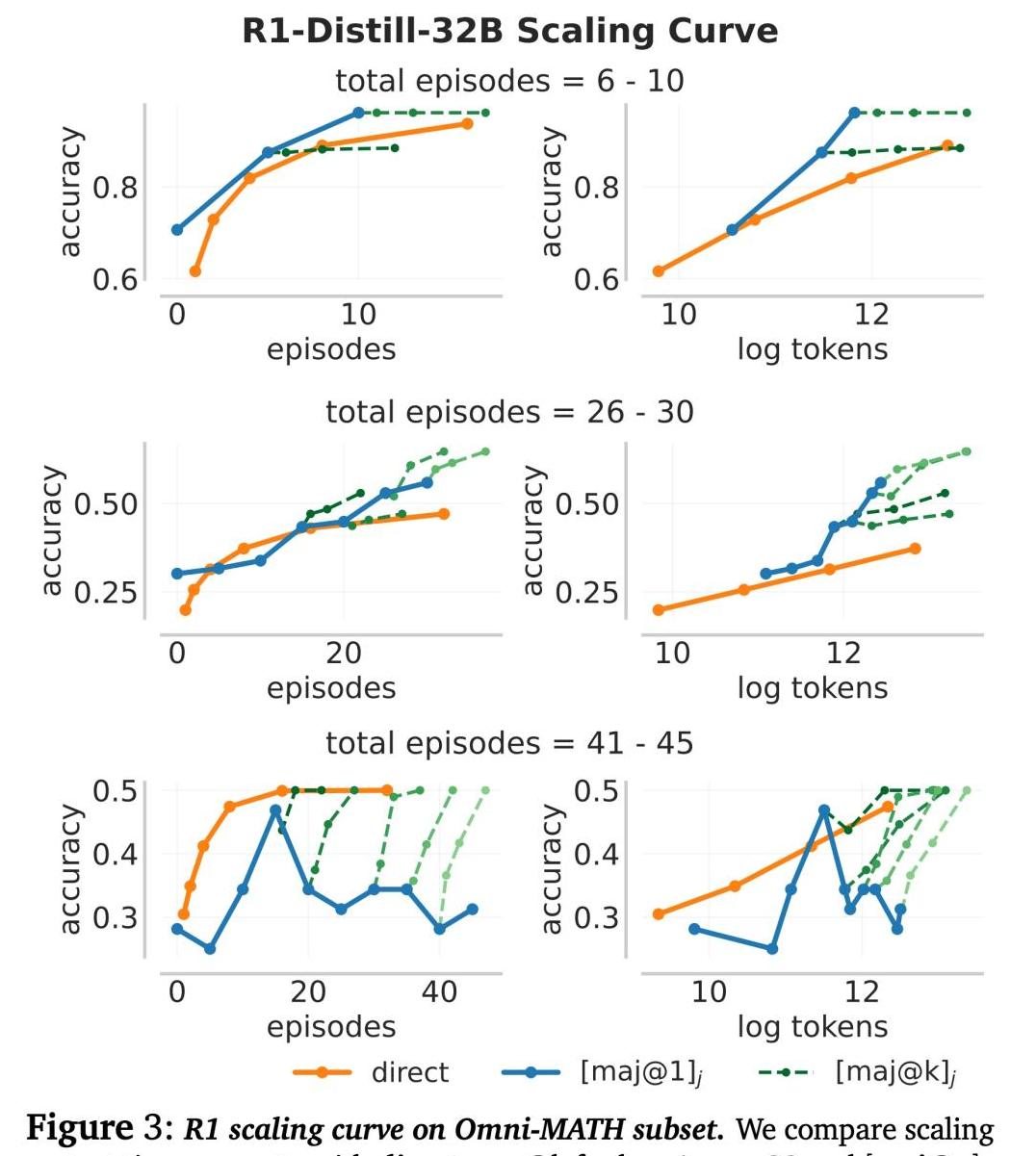
这个新方法在多个测试中取得了显著成绩,展示了其强大的应用潜力。
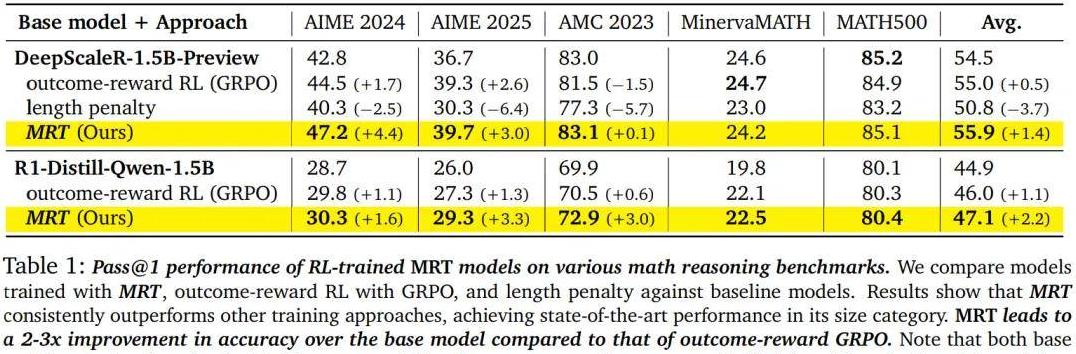
在实验测试中,CMU团队发现他们的MRT方法在多个基准测试中取得了领先成绩。
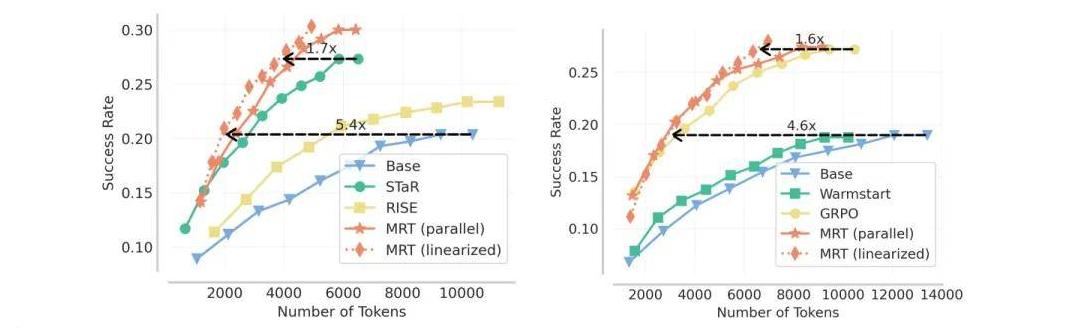
以AIME 2024和AIME 2025测试为例,MRT的准确率比传统的结果奖励RL方法高出很大一截。

同时,通过优化token的使用,MRT在相同数量的token下,取得的结果比基础模型高出大约5%。
这意味着,使用MRT的方法不仅能让AI系统变得更聪明,还能更高效地完成任务。
具体的实验结果也进一步证明了MRT的优势。
在实验中,不同规模的模型都显示了显著的性能提升。
例如,一个规模为15亿参数的基础模型使用MRT进行微调后,在多个测试数据集上的准确率提升了2-3倍,token的效率也提高了1.5倍。
这些数据无疑展示了MRT在实际应用中的巨大潜力。
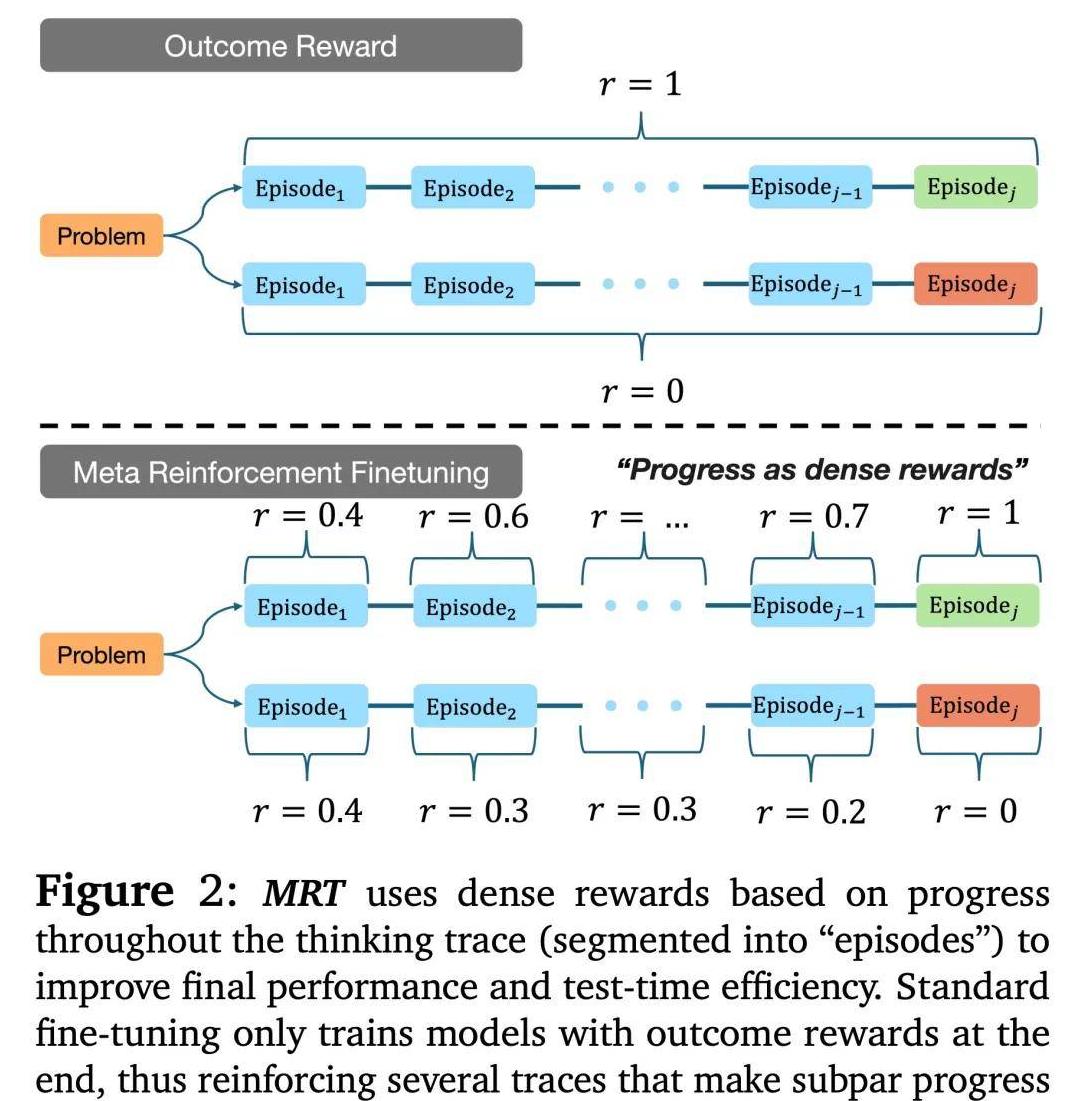
尽管MRT表现优秀,但它是否能完美替代现有的算法呢?
CMU团队也对此进行了深入研究。
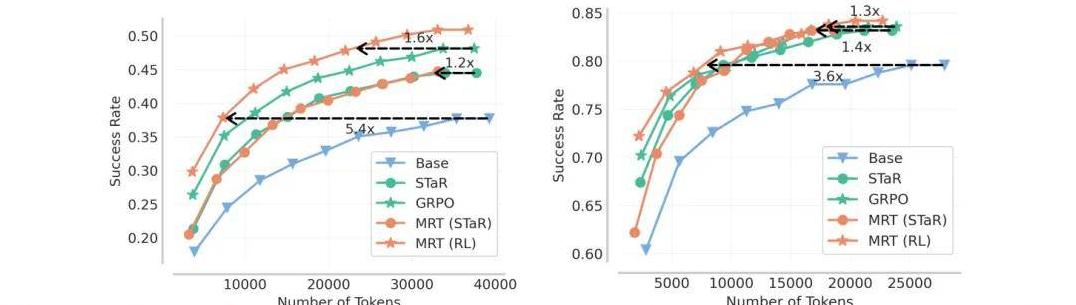
比如,在与GRPO等传统算法的对比中,MRT在复杂问题上的表现更加优秀。
在一些特定场景下,MRT优化了探索和利用的过程,不仅减少了错误率,还提升了整体效率。
传统的强化学习算法,如GRPO,虽然也表现不俗,但在面临新的、更复杂的问题时,往往显得有些捉襟见肘。
MRT则通过精细化的微调过程,不断优化每个步骤的计算,使模型能够更好地应对复杂问题。
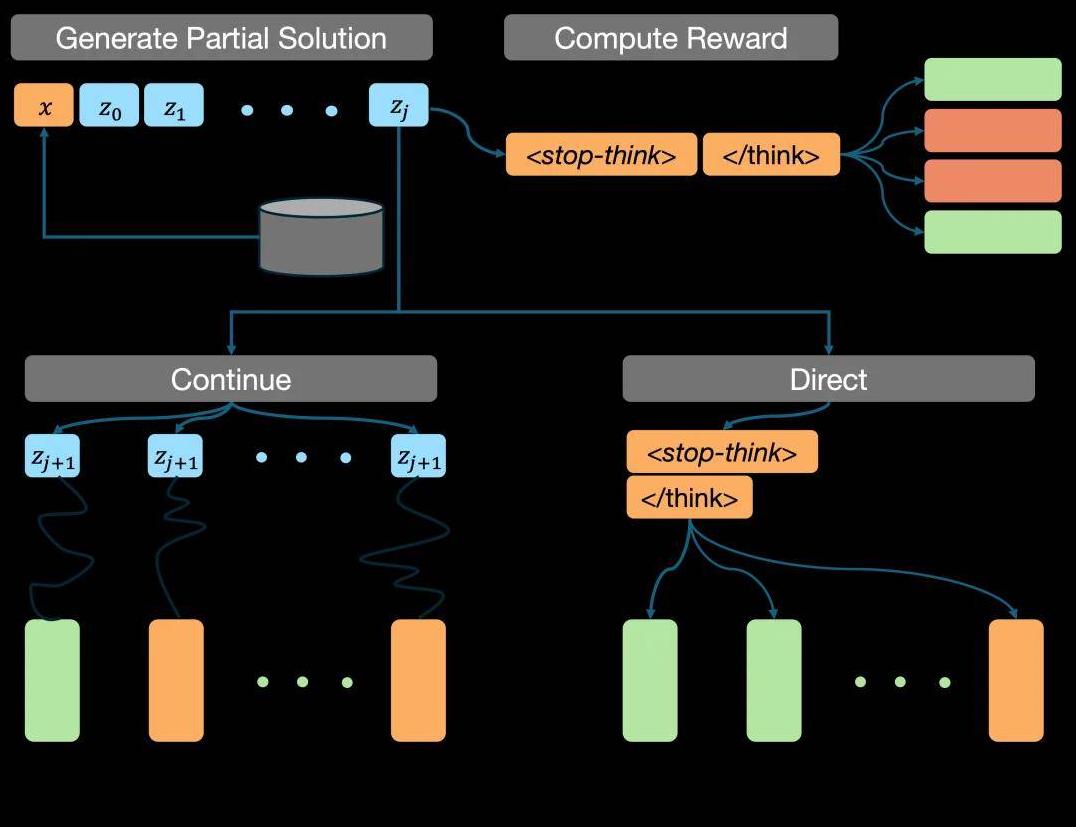
CMU团队的研究显示,MRT在处理高级数学推理问题时,其表现比现有方法稳定且更高效。
结尾部分,小明脑海中浮现出这样一个场景:道路上的自动驾驶汽车能够更加快速准确地处理复杂的交通状况,智能助手能够更智能地为我们解答各类问题。
这一切背后,都有赖于像MRT这样的新算法的支持。
未来,随着更多类似的技术突破,我们将在日常生活中享受到越来越多的智能化服务。
这些新技术不仅代表了科学的进步,更象征着我们对未知领域不断探索的勇气与智慧。
MRT的出现,让我们看到了一个更加美好的未来,也为我们带来了无限的遐想与期待。