2026年1月6日,全球科技圈最期待的盛会——CES 2026,即将拉开帷幕。如果说2025年10月,英特尔首次向业界展露其“王炸级”产品Panther Lake的“真容”,那么这一次,可能就是这款处理器真正隆重登场的时刻了。

老实讲,对于Panther Lake,业界已经期待太久了。早在2025年10月,英特尔就在架构层面给出了详细的技术方案,但那时候就像看预告片。
Panther Lake并不仅仅是某个前代产品的简单升级。它汲取了Lunar Lake(比如酷睿Ultra 200V)那套“省电秘诀”,又融入了Arrow Lake(酷睿Ultra 200H/HX)的强悍基因,让这两个看似矛盾的方向在Panther Lake上实现了某种平衡。这样的架构思路说起来容易,做起来可能需要经历无数的调试过程,它究竟实际体验如何,让人期待拉满。
生产工艺:首发Intel 18APanther Lake为什么能做到这样的平衡与融合?首先得说说它核心秘密——Intel 18A工艺。这是英特尔首个2nm级别的量产制程,也将是英特尔未来三代客户端和服务器产品的技术基座。更重要的是,它带来了两项重要创新。

先说RibbonFET。这个技术其实之前我们的技术栏目已经有过很多次介绍。简单讲,它就是给晶体管“换了个新身体”。从前那种鳍片式的FinFET结构被完全改造成纳米薄片。栅极从四面把电流通道完全“锁死”,这样做的好处是晶体管的开关控制变得更敏捷,响应速度更快,漏电现象明显下降。这次创新为英特尔摩尔定律的后续延展预留了相当大的想象空间。

再说PowerVia——背面供电技术。PowerVia的思路是把所有供电网络搬到晶圆背面去,正面只留信号通道。这一个看似简单的“搬家”,却能把芯片密度提升10%,同时把供电压降减少30%左右。对于高频电路来说,这意味着能拿到更“干净”、更稳定的电流。
这两项技术叠加起来效果如何呢?对比Intel 3工艺,18A的每瓦性能可以提升15%;同样的性能水平下,功耗能降低25%以上;芯片密度提升了大约30%。翻译成一句话:同样的笔记本电脑,续航时间会变长,发热会控制得更好,整体体验更顺滑。
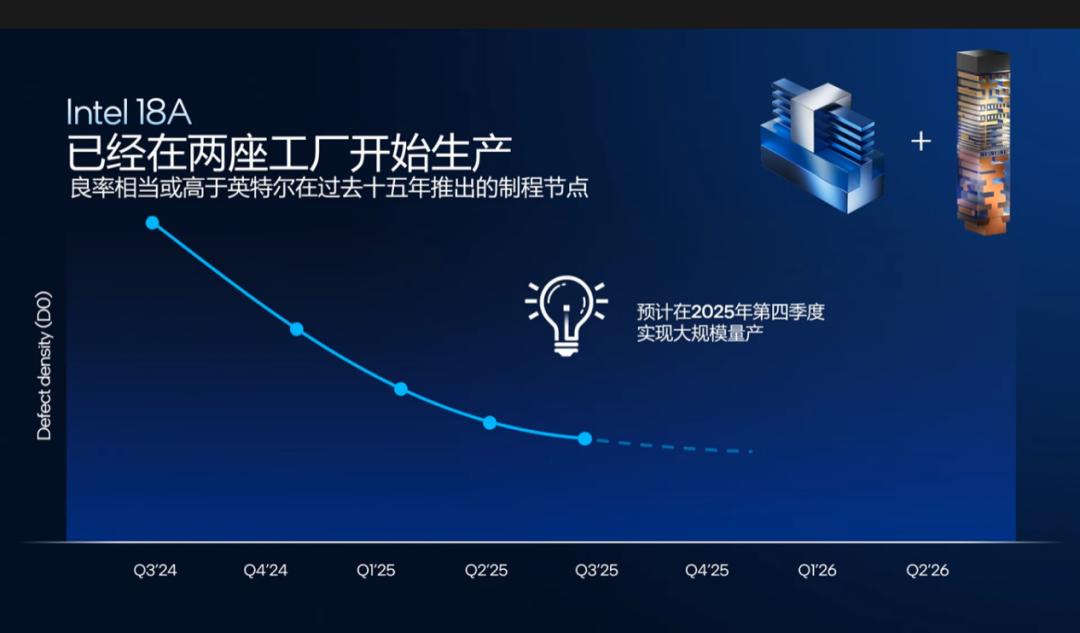
英特尔此前表示,Panther Lake的计算模块已经在亚利桑那州的Fab 52晶圆厂投入生产,量产良率甚至超过了过去15年推出的任何制程节点。这意味着这次应该产能比较“充裕”,虽然最近存储方面面临周期性波动,但英特尔的合作伙伴相信都已经做好准备。
混合核心:三种核心的“各司其职”Panther Lake的CPU设计有点“各司其职”的意思。

整个计算模块融入了三类核心:性能核(P核)、能效核(E核)以及低功耗能效核(LPE核)。每一种都有明确的“分工”。这样的组合方式给用户带来丰富的选择空间——8核心的入门配置、16核心的标准版,再到16核加强版,几种组合基本覆盖了从轻度使用到专业工作的各种场景。

性能核用的是Cougar Cove架构,这是全新设计的。为了提升单线程性能和吞吐量,英特尔在分支预测和乱序引擎部分下了不少功夫,直接给了多达18个执行端口。英特尔还嵌入了AI学习算法。就是处理器会学着“理解”你的使用习惯,实时捕捉CPU负载的变化,然后主动调配硬件资源。这样做的结果是性能可以充分发挥,同时电能可以更好地节省。
能效核方面,这次从Lunar Lake的Skymont升级到了Darkmont。这边的升级有点不一样——Darkmont既能处理多线程任务,又能保持良好的能效表现。英特尔在分支预测、动态预取、Nanocode和内存消歧等方面都做了优化。简单说,这些核心现在能进行更深的分支预测,准确度也更高;内存访问时也更“聪明”,能更有效地处理多线程负载,减少不必要的等待。
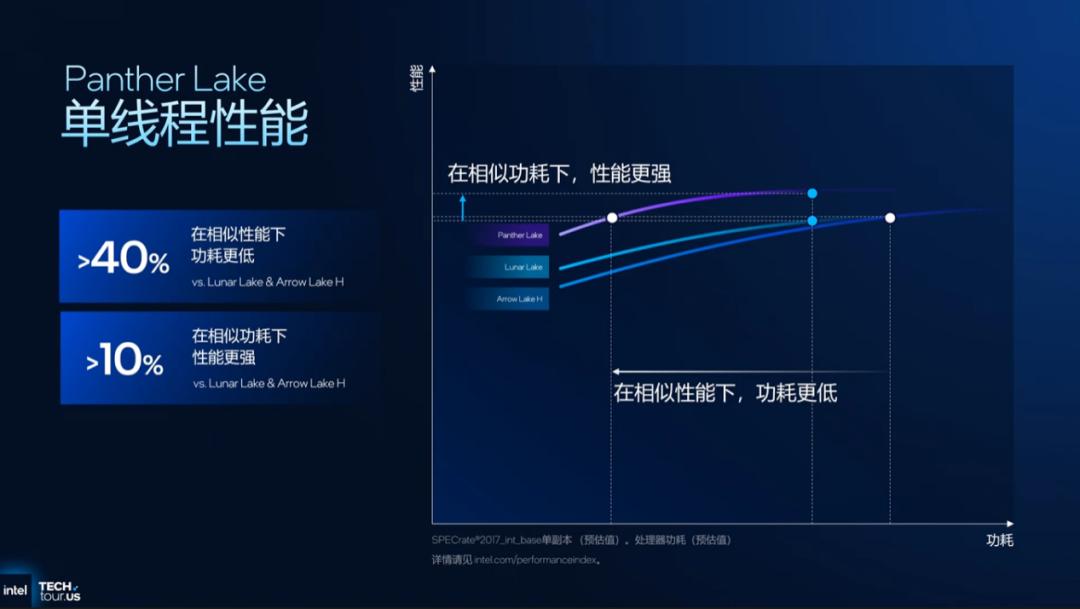
英特尔此前给出的数据是相当亮眼的。相同功耗下,Panther Lake的单线程比Lunar Lake快了10%以上;反过来比,同样的单线程性能,功耗能降低40%以上。多线程呢?相同功耗下,对标Lunar Lake能快50%以上;如果追求相近的多核性能,功耗相比Arrow Lake H能降低30%以上。
调度算法的“聪明劲”再来看调度。英特尔这次推出的“智能体验优化器”也挺有意思。

这套机制的核心逻辑是让系统根据实时负载自动在性能模式和节能模式之间切换。以前用户得自己手动调,现在完全不用。系统内置了这个功能,不管是什么操作系统版本,不管是什么OEM厂商做的笔记本,只要搭载Panther Lake,都能享受到这套智能调度。
效果呢?在UL Procyon生产力基准测试和CINEBENCH 2024单线程测试中,Panther Lake设备相比前代能实现19%的性能提升。要知道这19%是在用户什么都不用操心的前提下自动获得的,就像处理器“赠送”了这么一份大礼包。
集显“大升级”要说Panther Lake最吸人的改进,集显的升级一定也能算一个。

新一代集显基于Xe 3架构,图形性能提升超过50%。Panther Lake提供两种GPU配置:4核Xe和12核Xe。4核版本配备4个Xe核心、32个XMX引擎、4MB L2缓存、4个光追单元等标配;12核版本则是“豪华套餐”——12个Xe核心、96个XMX引擎、16MB L2缓存、2个几何管线、12个采样器、12个光追单元和4个像素后端。从纸面参数看,这都是相当好的集成显卡配置。
性能优化这块英特尔也没含糊,Xe 3架构从引擎到切片都进行了全面优化。此外,Xe 3的XMX峰值算力高达120 TOPS,原生支持FP8数据类型,这正好是当前主流AI模型的主要“方言”。Xe 3的光线追踪单元也升级了,支持异步光线追踪的动态光线管理,能大幅提升光线追踪负载的性能。
综合来看,这次的集显可能真的会成为“最强集显”的新代名词。此外,Panther Lake处理器还内置NPU,让整个平台的AI总算力能达到180 TOPS。这对于部署和运行AI大模型、以及更广泛的AI应用来讲,肯定更有帮助。
CES前的“剧透”现在,距离CES 2026的开幕不到一个月的时间。按照惯例,英特尔应该会在展会上正式公布Panther Lake的完整规格,可能还会有首批搭载这款处理器的笔记本电脑产品亮相。如果一切按计划,Panther Lake应该能在2025年第四季度实现大规模量产——英特尔已经说了,目前的量产良率已经超过过去15年任何制程节点的水平。这意味着至少CPU供应的压力应该不会太大。

从技术维度来看,Panther Lake真的是一款诚意满满的产品。它不是某一个方向的激进创新,而是在多个维度上的均衡发展:Intel 18A工艺给了它“底气”,混合核心给了它“灵活性”,智能调度给了它“好脾气”,而GPU和NPU的升级更是给了用户“更多可能”。
特别值得关注的是,Panther Lake所代表的架构思路——能效与性能的融合、本地AI计算能力的整合——这些应该不仅是这一代产品的特点,更像是英特尔对未来PC方向的一次全新规划。
当然,具体怎么在CES上“玩”,我们还得等英特尔真正开始发布的时候才能看到。说实话,Panther Lake的出现必然会大大提升“I饭”的期待。不过作为消费者,相信大家更关心的是价格,毕竟在存储疯狂涨价、首次采用Intel 18A新工艺的背景下,即将到来的Panther Lake笔记本会以怎样的价格面市呢?相信英特尔也会根据市场的承受力给出专业的定价策略。而对于今天的科技潮人来说,产品力本身可能才是影响购买的决定因素。让我们拭目以待。