哈喽,大家好,我是小方,今天,我们主要来看看,那些在屏幕上能说会道的AI大模型,一旦被扔进真实世界的复杂场景,比如手术室或工厂车间,它们的“眼睛”和“脑子”还能不能跟上。
 学霸“翻车”:当AI离开日常舒适区
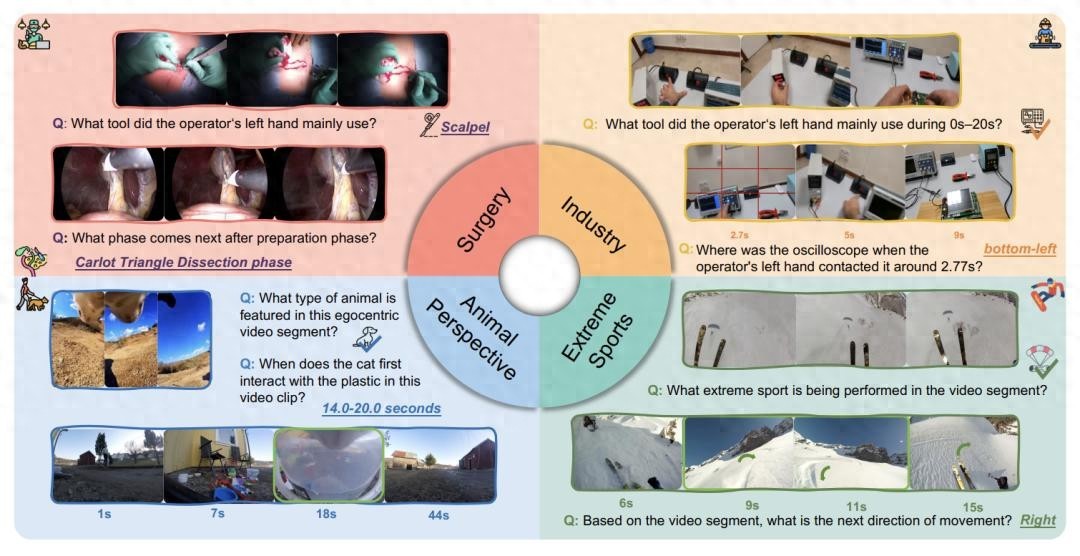
学霸“翻车”:当AI离开日常舒适区相信大家都习惯了AI生成美图、对答如流的样子,仿佛它无所不知,但最近一项来自华东师范大学等机构的突破性研究,给这种乐观泼了一盆冷水,研究团队创建了一个名为“EgoCross”的评测基准,专门考核AI模型在手术、工业维修、极限运动和动物视角这四个专业领域的第一视角视频理解能力。

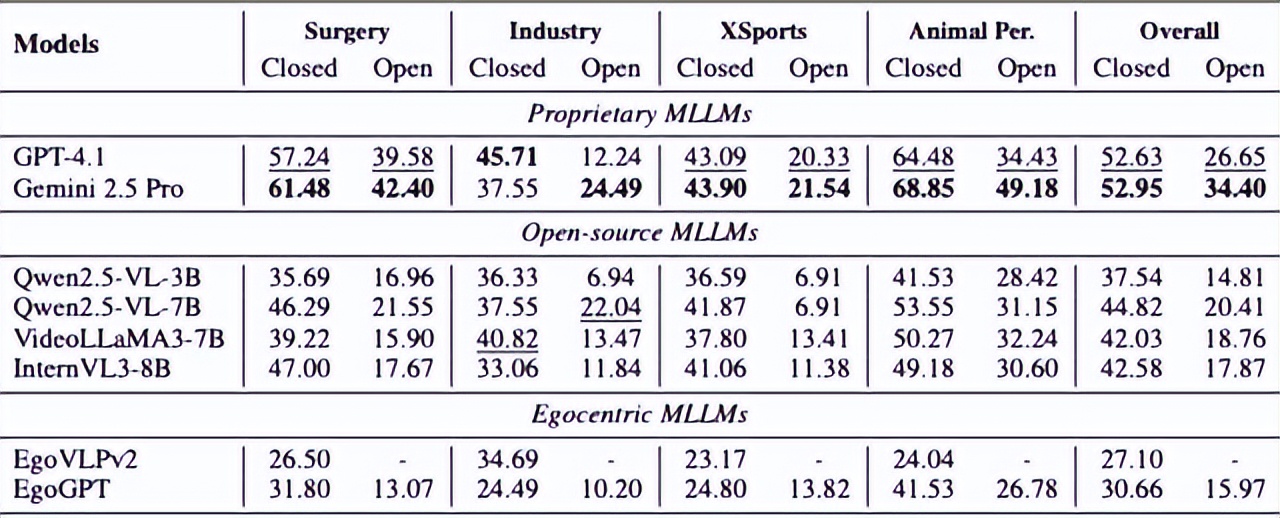
结果呢?即使是顶尖的GPT-4.1、Gemini等模型,表现也堪称“滑铁卢”——在选择题上的准确率骤降至55%以下,开放式问答更是低于35%,说白了,让AI看着主刀医生的视角选下一把手术钳,或者看着维修工的视角判断电路板故障,它很可能就懵了,这跟它在“如何切菜”这类日常问题上的娴熟表现,形成了鲜明对比。
 “水土不服”的根源:不止是画面变了
“水土不服”的根源:不止是画面变了为什么会出现这种断崖式的性能下跌?研究发现,核心问题在于“领域差异”,这不仅仅是画面从厨房变成了手术室那么简单。
首先,专业细节要求极高,日常生活中,识别“一把刀”可能就够了,但在手术中,模型必须精确区分“抓钳”、“手术刀”和“双极电凝镊”,每一种器械的用途和出现时机都关乎生命。

其次,视觉条件极端恶劣,极限运动视频充满剧烈抖动和模糊帧,动物视角则高度、运动轨迹完全不符合人类习惯。

最后,逻辑链条漫长且专业,工业维修往往涉及一系列严格的步骤,AI不仅要识别“螺丝刀”,还要理解它在这一步被使用的目的,并预测下一步该做什么,这些因素叠加,对仅靠海量互联网图文数据训练出来的大模型而言,构成了巨大的认知鸿沟。
 现实的回响:近期案例印证研究担忧
现实的回响:近期案例印证研究担忧其实,这项研究指出的问题,在最近的一些真实技术应用中已经听到了回响,就在上个月,国内某知名汽车品牌在测试其自动驾驶系统的城市通勤能力时,工程师就发现,系统在面对一场突如其来的、混杂着冰雹的暴雨时,对路况和障碍物的判断能力明显下降。

研发负责人对媒体坦言,尽管模型在数千小时的晴好天气和普通雨天数据中训练得很好,但对于这种极端且少见的“强对流天气混合降水”场景,感知模块的泛化能力遇到了瓶颈,这本质上也是“领域差异”问题——训练数据的主要“领域”是常规天气,而现实抛来了一个分布之外的“新领域”。

同样,在工业质检中,一个能精准识别标准零件瑕疵的AI视觉系统,当生产线更换了一种表面反光特性完全不同的新材料时,误检率可能会急剧上升。这些活生生的例子都在告诉我们,AI要真正在严苛的现实世界里“扛事”,远不是把实验室指标做高那么简单。
 寻找解药:从“提词”到“强化训练”
寻找解药:从“提词”到“强化训练”面对短板,研究人员也在积极寻找解药。EgoCross团队尝试了几种方法。最直接的是“提示学习”,就像考试前给考生划重点,在问题前加上“这是一个手术视频…”的提示,能稍微唤醒模型的一些相关知识,但提升有限,更有效的方法是“监督微调”,相当于让AI进行专项特训,用特定领域的数据去调整模型参数,在工业领域数据上微调后,模型性能提升了接近20%。

目前看来最有潜力的是“强化学习”,它让AI像学生做模拟题一样,自己生成多个答案,然后由一个“奖励模型”评判对错并打分,通过不断试错来优化策略,这种方法带来了平均22个百分点的显著提升,这些探索虽然初步,但指明了方向:要让AI变得更可靠,可能需要更精巧的、针对性的训练机制,而不仅仅是扩大通用数据的规模。
 结语
结语说到底,这项研究像一次精准的“体检”,暴露了当前大模型光鲜外表下的能力边界,它提醒我们,通往真正稳健、可信赖的人工智能,道路还很长,但每一次对局限的清晰认知,都是迈向下一步的坚实基石。

未来,随着更多针对性的数据和训练方法的出现,或许有一天,AI不仅能聊家常,还能成为各行各业真正得力的专业助手。