生成式AI领域正经历激烈的技术竞速,OpenAI于2025年12月11日正式发布GPT-5.2,这是对谷歌11月推出的Gemini 3模型的战略回应。面对Gemini 3在多模态处理与长文本理解上的突破,OpenAI CEO Sam Altman启动"红色警报"机制,将资源集中于核心模型迭代,使得GPT-5.2距上一版本GPT-5.1发布仅间隔21天,创下该公司历史上最快更新纪录。

竞争压力下的战略迭代:2025年8月GPT-5因专业知识短板遭质疑,11月GPT-5.1改进有限,而Gemini 3的强势表现迫使OpenAI加速产品路线图,此次发布标志着AI行业竞争已进入"月度迭代"新阶段。
GPT-5.2首次将定位从通用型AI转向"专业知识工作优化",聚焦编程开发、科学计算、长文档处理等专业场景,被官方称为"迄今为止在专业知识工作方面表现最好的模型系列"。OpenAI强调,新模型通过电子表格自动化、多步骤任务处理等能力提升,旨在"为人们创造更多经济价值",其GDPval评测70.9%的胜率数据,预示着AI对知识工作生产力的重塑进入实质落地阶段。这一定位转变不仅是技术路线的调整,更暗含OpenAI争夺企业级市场、支撑万亿美元基础设施投资计划的商业战略。目前智创聚合API平台已上线,并支持API接入,为开发者提供便捷的模型调用服务。

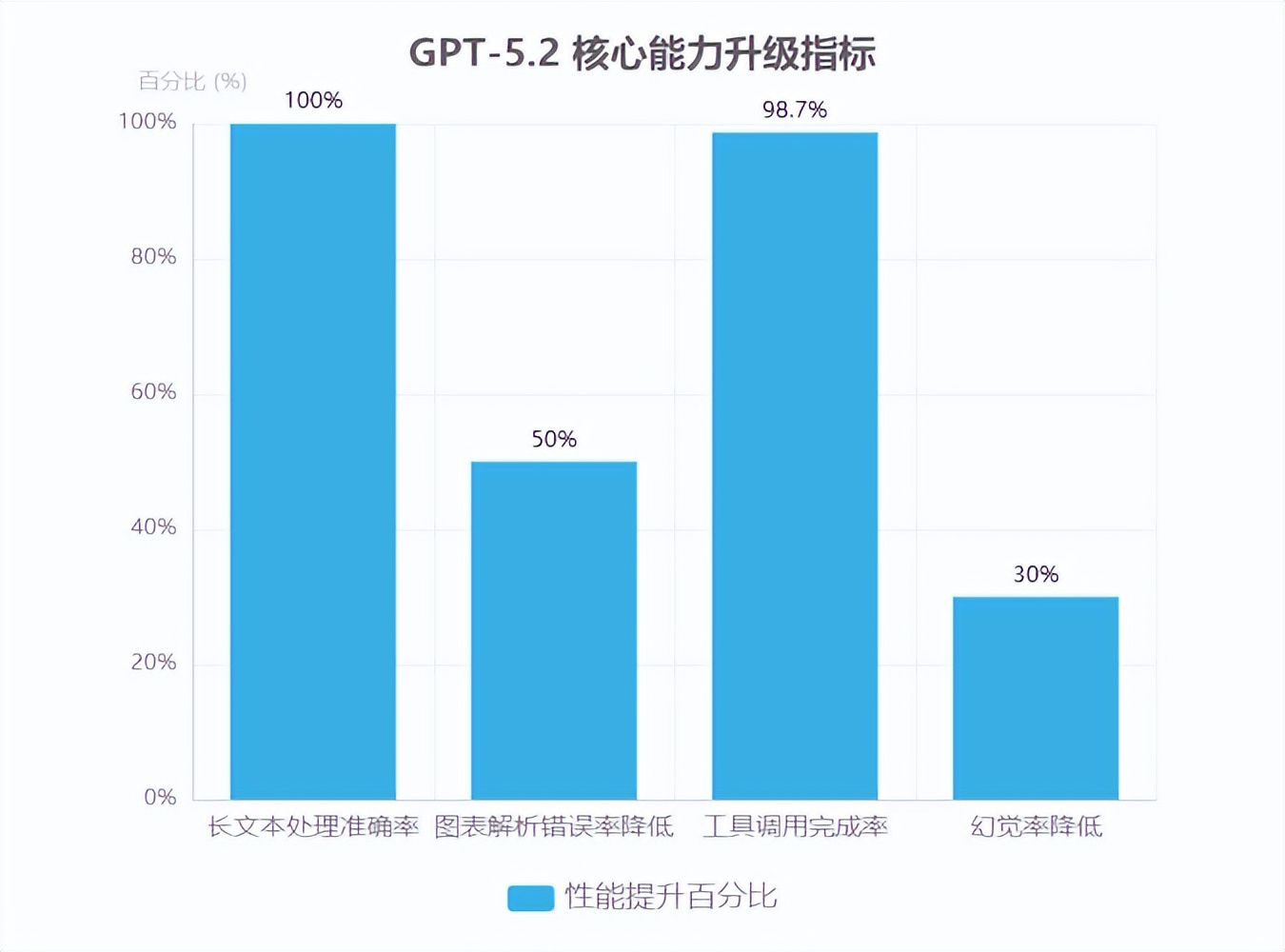
GPT-5.2 在基础架构层面实现重大突破,搭载 40 万 token 上下文窗口,支持文档级信息整合,可同时处理数百份文档,尤其适用于合同、研究报告等长文本场景。OpenAI MRCRv2 测试数据显示,该模型在 25.6 万 token 范围内准确率接近 100%,在多文档相似信息点区分任务中表现突出。
多模态感知能力显著增强,其视觉理解模块被官方称为“当前最强视觉模型”,图表推理与软件界面理解错误率较前代降低约 50%。实际业务场景中,可精准解析财务图表、技术仪表盘、工程图纸等专业视觉信息,适配金融运营、工程设计等领域需求。
执行效率方面,工具调用机制实现跨系统多步骤工作流优化。在 Tau2-bench Telecom 任务中,多轮工具调用完成率达 98.7%,能自主执行数据提取→分析→输出的全链条自动化处理。编码领域,初创公司反馈其实现“最先进的智能体编码性能”,支持复杂 API 调用与跨平台协作。
安全机制持续成熟,幻觉率较 GPT-5.1 降低 30%,专业知识密集型场景可信度显著提升。同时引入年龄预测系统,针对心理健康等敏感对话实施分级内容保护,进一步强化企业级应用可靠性。
这些技术突破已通过智创聚合API平台开放,开发者可一键接入40万token上下文处理与多模态推理能力

核心能力升级要点
长文本处理:40 万 token 窗口实现 25.6 万 token 近 100% 准确率
视觉理解:图表解析错误率下降 50%,支持复杂业务场景图像分析
工具调用:Tau2-bench 任务 98.7% 完成率,实现全链条自动化
安全优化:幻觉率降低 30%,新增年龄预测与分级保护机制
OpenAI 为 GPT - 5.2 推出 Instant、Thinking 和 Pro 三个版本,采用“定位—能力—适用场景”分层框架,平衡速度、推理深度与成本,优化用户效率与总体拥有成本。
版本定位差异
Instant:速度优先,日常轻量任务主力,如信息查询、翻译、技术写作,延续亲切对话风格。
Thinking:专业人士“主力工具”,聚焦结构化任务,支持高级工具调用与深度推理。
Pro:最高精度版本,面向关键任务,强调复杂领域准确性与可靠性。
各版本能力与场景形成梯度:Instant 以低延迟处理轻量任务;Thinking 在编码(SWE - Bench Pro 评测 55.6%)、数学推理(AIME 2025 竞赛 100%正确率)表现突出;Pro 则在专业场景领先,如 GPQA Diamond 研究生级科学测试 93.2 分,FrontierMath 专家级数学问题解决率 40.3%。
分层策略通过精准匹配任务需求降低成本。API 定价为:基础版本每百万输入 token 1.75 美元、输出 14 美元;Pro 版本输入 21 美元、输出 168 美元,缓存输入享 90%折扣。虽单 token 价格高于前代,但模型效率提升使相同质量任务总成本更低。
针对不同业务需求,智创聚合API平台提供灵活的版本选择方案,支持按调用量弹性计费

为全面评估GPT-5.2的技术突破,本章节构建"横向(版本内)+纵向(代际)+竞对"三维对比体系,通过多维度基准测试揭示其性能边界与行业价值。
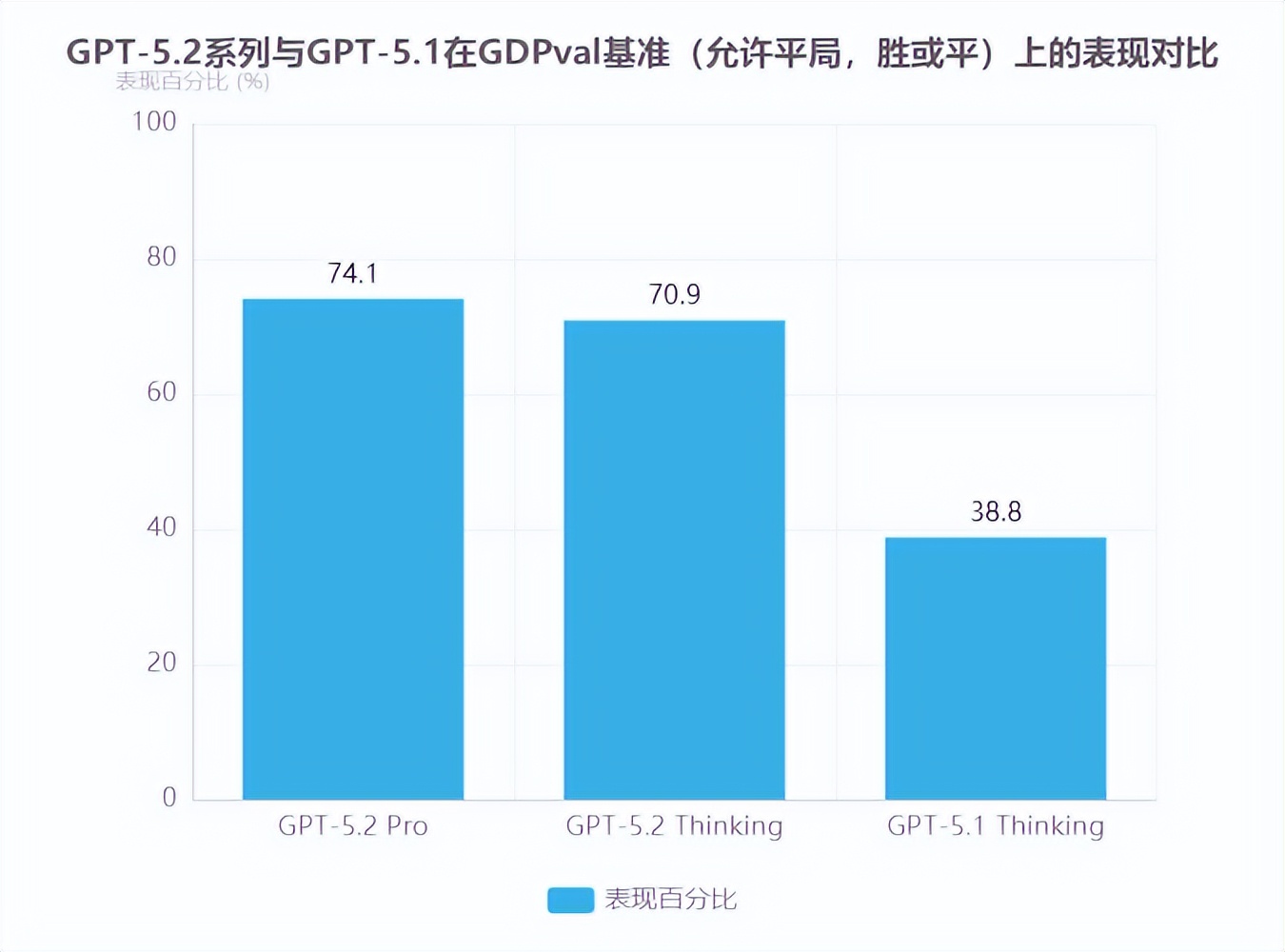
横向版本内性能分化GPT-5.2系列在核心基准测试中呈现显著版本差异。GDPval基准作为衡量AI职业任务能力的关键指标,涵盖44种知识型工作场景(如金融分析、法律文书、工程设计等),Pro版本以74.1%的综合表现(允许平局时胜或平)领先,Thinking版本紧随其后达70.9%。在专业领域细分中,投资银行电子表格任务处理准确率达71.7%(Pro版本),编码领域的SWE-Bench Pro测试准确率达80%,验证了模型在结构化任务中的高精度表现。
专业领域
GPT-5.2 Thinking
GPT-5.2 Pro
GPT-5.1 Thinking
GDPval(允许平局,胜或平)
70.9%
74.1%
38.8% (GPT-5)
GDPval(允许平局,明确胜)
49.8%
60.0%
35.5% (GPT-5)
GDPval(无平局)
61.0%
67.6%
37.1% (GPT-5)
SWE-Bench Verified(编码)
80.0%
-
76.3%

纵向对比显示,GPT-5.2实现了标志性性能跨越。其GDPval综合得分较GPT-5.1提升超30个百分点,即使在最低推理强度设置下,综合表现仍显著优于前代产品。这种进步在成本效益维度尤为突出:模型完成任务速度达人类专家的11倍以上,综合成本却不足专家的1%,首次实现AI在知识型工作中"性能超越人类、成本指数级降低"的双重突破。
关键突破:GPT-5.2成为首个在GDPval测试中总体表现超越人类专家的AI模型,70.9%的职业任务表现达到或超过行业专家水平,标志着通用人工智能在知识工作领域的里程碑式进展。
行业竞对比较优势与Google Gemini 3相比,GPT-5.2在专业任务处理中展现差异化优势。编码领域,SWE-Bench Pro测试80%准确率显著领先行业平均水平;长文档处理场景下,256k上下文长度任务的处理准确率达89.8%,在GraphWalks图结构推理任务中更是达到94%的正确率。OpenAI CEO Altman指出,Gemini 3对公司核心指标的实际影响小于预期,侧面印证了GPT-5.2在技术路线上的领先性。
在科学研究领域,GPT-5.2 Pro在GPQA Diamond测试中达到93.2%的专家级准确率,Thinking版本在CharXiv科学推理任务(使用Python工具)中得分88.7%,显示出模型在复杂问题解决场景的深度竞争力。这种多维度优势使得GPT-5.2不仅是工具性AI,更成为推动知识生产范式变革的基础设施。
基于实测性能数据,智创聚合API平台已针对金融、编程等场景优化模型参数,平均响应速度提升30%

值得注意的是,目前智创聚合API平台已上线,并支持API接入,助力各行业快速集成先进AI能力。
金融领域:投资银行电子表格任务自动化在金融分析场景中,GPT-5.2 针对投资银行电子表格任务展现出显著优势。其 Pro 版本在内部测试中准确率达到 71.7%,Thinking 版本为 68.4%,该性能已接近或超过行业专家水平,尤其适用于金融建模、预测及数据分析等需要高精度数学推理的任务。技术支撑方面,模型的视觉处理能力实现关键突破——图表推理与软件界面理解错误率较前代降低约 50%,可精准解读数据仪表盘与复杂可视化报告,直接提升电子表格生成与校验的效率。
软件开发:工程效率的量化提升编程领域,GPT-5.2 在 SWE-Bench Pro 基准测试中取得 55.6% 的成绩,在 SWE-bench Verified 上更是达到 80% 的新高,这一技术突破已转化为实际生产力。初创公司如 Windsurf 和 CharlieCode 报告称,该模型实现了"最先进的智能体编码性能",尤其擅长处理大规模、多文件、跨模块的复杂编码任务。其长上下文处理能力(40 万 token)与代码逻辑推理能力的结合,使开发团队在多文件协同开发中减少 30% 以上的调试时间,显著降低了大型项目的维护成本。
科研场景:跨文档知识整合与科学发现GPT-5.2 的 40 万 token 超长上下文能力,使其成为科研工作的高效辅助工具。在多文档信息整合任务中,模型准确率接近 100%,尤其擅长区分相似研究结论与实验数据,支持研究者快速构建跨多篇论文的知识图谱。科学推理方面,Pro 版本在 GPQA Diamond 专家级测试中达到 93.2% 准确率,Thinking 版本在 FrontierMath 高阶数学测试中解决了 40.3% 的问题,为材料科学、生物医药等领域的文献综述与假设生成提供强大支持。
企业办公:生产力工具的范式革新作为新一代生产力工具,GPT-5.2 在办公自动化场景中展现出"速度-成本"双重优势。在 GDPval 任务测试中,Thinking 版本完成速度是人类专家的 11 倍以上,而成本仅为专家的 1%。其多模态能力支持电子表格、演示文稿等办公成果的全自动生成,Instant 版本在信息查询、技术写作和翻译任务中也实现显著提升,推动企业文档处理效率提升 3-5 倍。
技术能力与应用效果的核心关联
长上下文处理(40万token)→ 跨文档科研整合、多文件代码开发
视觉-文本融合推理 → 金融图表解读、工程图纸理解
数学推理优化 → 金融建模准确率提升至71.7%
多模态内容生成 → 办公成果自动化与成本压缩

目前智创聚合API平台已上线,并支持API接入。
GPT-5.2 对知识工作效率产生颠覆性提升,在评估 44 个职业知识型任务的 GDPval 测试中,该模型成为首个总体表现达到或超过人类专家水平的 AI 模型,70.9% 的任务表现与行业专家持平或胜出,且完成速度是人类专家的 11 倍以上,综合成本不足专家的 1%,显著优化企业运营成本。
潜在挑战方面,就业结构将面临显著变化。一方面,基础任务存在替代风险,GPT-5.2 在 GDPval 任务中展现的高效低成本特性可能导致部分重复性知识工作岗位需求减少;另一方面,高端技能需求将同步增长,如与 AI 协作、复杂问题定义等能力的重要性日益凸显。
竞争格局上,GPT-5.2 的发布巩固了 OpenAI 的市场领先地位,其作为首个在职业任务上达到专家水平的 AI 模型,对 Google 等竞争对手形成强大压力。OpenAI CEO 萨姆·奥尔特曼对此表达了乐观态度,认为该模型的推出将在 1 月份显著稳定公司的市场地位。
伦理监管问题亦随之凸显。例如,OpenAI 已开始在部分地区推出年龄估算系统以控制 ChatGPT 对 18 岁以下用户的内容回复,此类应用引发了对隐私保护的担忧,这也进一步呼应了 OpenAI 升级安全机制的必要性。
核心影响总结
效率革命:在 44 项职业任务中 70.9% 达到专家水平,速度提升 11 倍,成本降低 99%
就业重构:基础任务替代与高端技能需求增长并存
竞争加剧:巩固 OpenAI 领先地位,对 Google 等形成技术压制
伦理挑战:年龄预测等应用的隐私风险推动安全机制升级
最后GPT-5.2 的演进路径呈现出“短期迭代—中期生态—长期治理”的三阶段发展脉络。短期来看,OpenAI CEO 山姆・奥特曼在 2024 年 12 月透露的“圣诞礼物”暗示,结合其“红色警戒模式”将于 2026 年 1 月结束的规划,预示图像能力增强与个性化功能优化将成为下一阶段迭代重点。这一方向与 GPT-5.2 从“问答”到“交付”的能力跃升形成延续,有望进一步满足细分场景需求。
中期维度,GPT-5.2 通过 API 向开发者全面开放的策略,正在加速垂直领域解决方案的构建。开发者可将模型能力集成至专业工作流,推动 AI 在法律文档生成、科研数据分析等专业领域承担更核心角色。这种生态扩张不仅体现为应用场景的拓宽,更标志着 AI 从工具属性向“专业知识工作助手”的阶段性跨越。
长期挑战则聚焦于技术狂奔下的平衡艺术。尽管 OpenAI 已部署年龄估算等安全机制,但数据隐私保护、模型滥用风险及全球监管适配仍是核心议题。多模态融合深化、自主学习能力突破等技术演进,将持续对现有治理框架构成考验。正如行业观察指出,GPT-5.2 的价值不仅在于当前能力边界的拓展,更在于其揭示的 AI 发展范式——技术突破与风险防控必须形成螺旋上升的动态平衡。