当大模型还在比拼千亿参数的“表面功夫”,华为用300万奥林帕斯奖的悬赏,把AI竞争的焦点拉回了底层技术的“生死线”。2025年发布的五道奥林帕斯难题,瞄准存储介质与Agentic AI数据底座两大核心,每一道都精准戳中AI规模化落地的底层痛点。这不是一次简单的技术悬赏,而是华为为下一代AI筑牢底座的战略布局,更是整个行业从“模型狂欢”回归“技术本质”的信号。

难题1:基于SSD的存算融合与高效索引技术
这道题的核心是双维度技术突破,绝非单一的硬件改造。传统存算分离架构下,AI数据在SSD与计算单元间的搬运消耗了70%算力,而AI发展让冷数据变温、温数据变热,数据调取频率呈指数级增长。华为要求在SSD中嵌入专用计算单元,让存储设备直接完成数据过滤、特征提取等预处理,同时设计适配该架构的索引算法,解决传统B+树索引在SSD中随机IO过高的问题。以盘古大模型为例,其训练需处理PB级多模态数据,若实现这一技术,数据搬运量可减少60%,训练周期缩短30%,这也是“以存补算”范式从概念走向落地的关键,能从根源上解决AI算力浪费的行业通病。
注释:
SSD是固态硬盘(Solid State Drive)的缩写。
IO是输入/输出(Input/Output)的缩写,指计算机系统中数据在存储设备、计算单元、外部设备之间的传输与交互过程。
PB是数据存储容量的计量单位,1PB=1024TB。

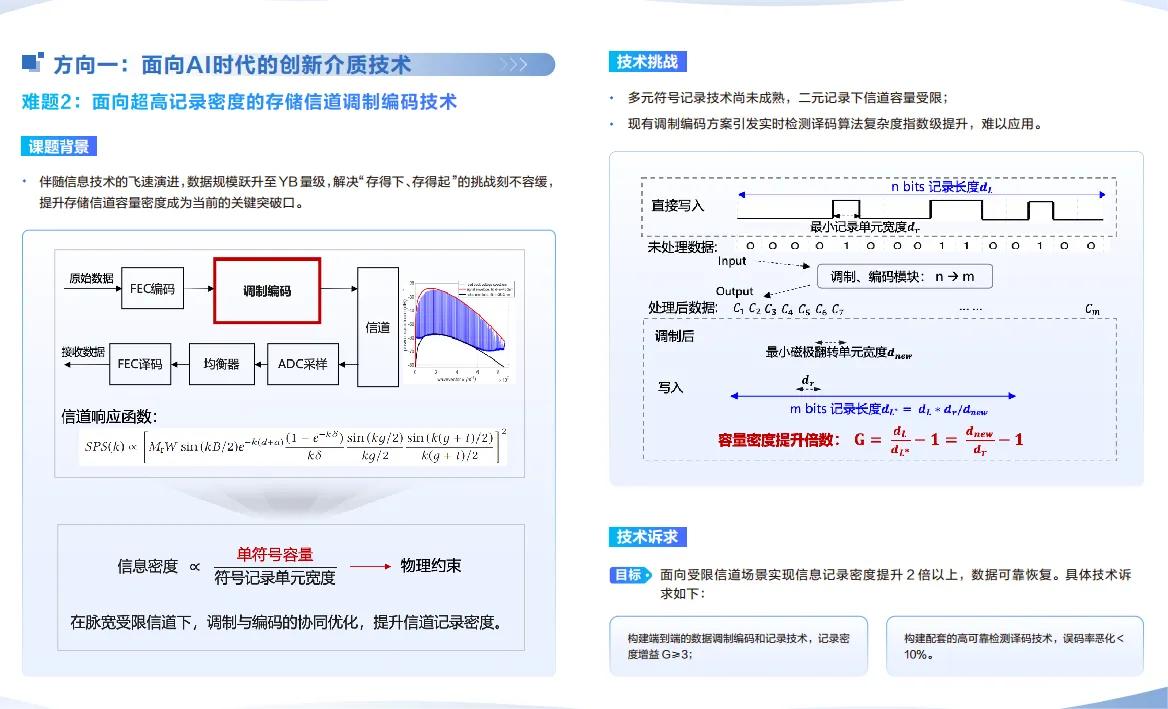
难题2:面向超高记录密度的存储信道调制编码技术
AI每年产生的数十ZB数据,正撞上存储介质的物理天花板——NAND Flash的密度提升空间仅剩10%。这道题的关键是信道调制与编码技术的协同创新,而非单纯提升存储密度。信道调制需优化存储信号的传输方式,减少不同介质(如全息存储、玻璃存储)的信号干扰;编码技术则要设计新的纠错与压缩方案,让单位体积存储容量翻倍,且数据误码率低于10⁻¹⁵。目前新存储介质虽在实验室实现高密度,但缺乏适配的调制编码技术,华为的考题正是要打通实验室到产业的最后一公里,解决AI数据中心存储成本居高不下的核心难题。
注释:
ZB是超大容量的数据单位,1ZB=1024EB,1EB=1024个PB。
NAND Flash是SSD、U盘里的核心存储芯片,靠存储电荷记录数据,断电也不会丢。
难题3:层次化大内存网络协议和IO路径优化技术
AI集群的层次化大内存架构(寄存器、缓存、SSD等),正面临数据流转的“堵车”困境。传统PCIe、CXL协议的延迟与带宽瓶颈,加上IO路径的冗余环节,让数据响应延迟占AI训练时间的40%。华为要求重构网络协议,实现多层内存的池化共享,让CPU、GPU能透明访问不同层级的存储;同时优化IO路径,根据数据热度动态调整流转路线,让热数据直接在内存中处理。对自动驾驶这类实时AI场景而言,该技术落地可使传感器数据传输延迟降低50%,是AI智能体实现实时决策的底层技术保障。
注释:
PCIe 是计算机里连接CPU、GPU、SSD等硬件的高速数据传输接口协议,通用性强,是目前消费级和工业级设备的主流连接方案。
CXL 是专门为数据中心、AI异构计算设计的新型协议,兼容PCIe。

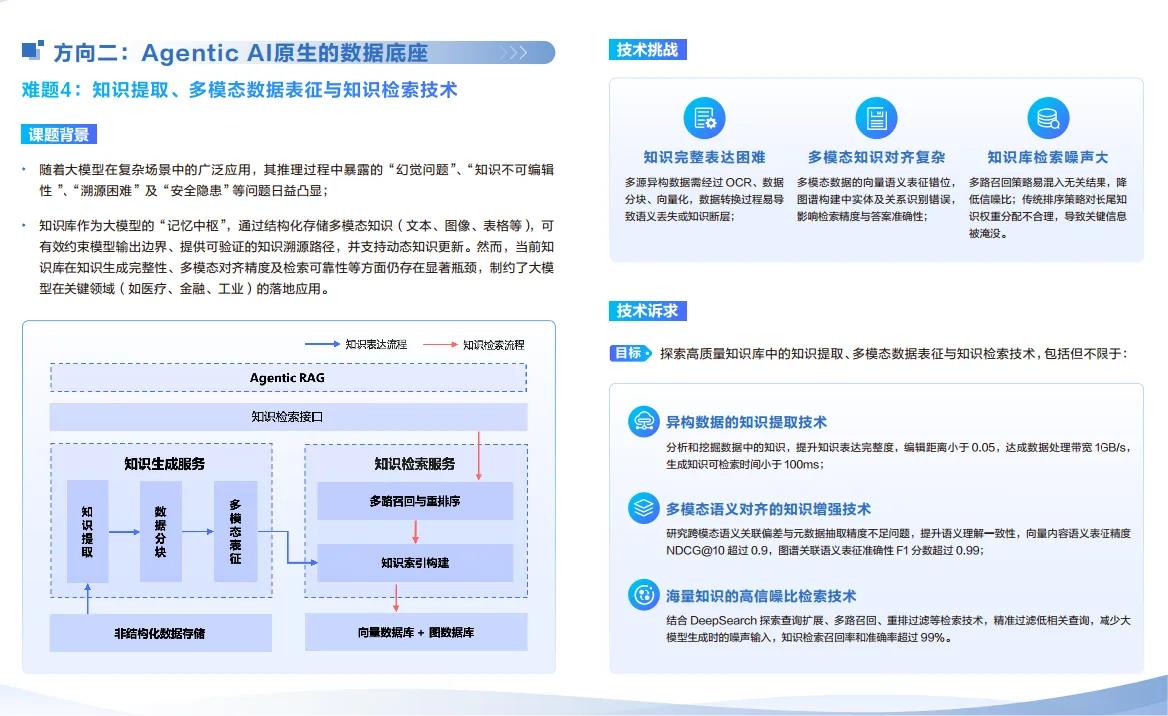
难题4:知识提取、多模态数据表征与知识检索技术
Agentic AI要从“工具”升级为“智能体”,首先得解决“看不懂”多模态数据的问题。这道题是知识提取、多模态表征、知识检索的三位一体要求:既要从文本、图像、视频中挖掘结构化知识,又要将不同模态数据映射到统一向量空间实现语义对齐,还要快速从海量知识库中调取匹配信息。当前智能座舱无法理解“找海边日出的视频攻略”这类跨模态需求,核心就是多模态表征割裂、检索低效。华为要求知识提取覆盖隐含语义,表征保留数据的时空关联,检索召回率超95%,这一技术落地后,AI智能体才能真正具备“知识理解能力”,而非机械执行指令。
注释:
Agentic AI (代理式人工智能)是能自主感知、决策、行动,按目标完成复杂任务的智能系统。
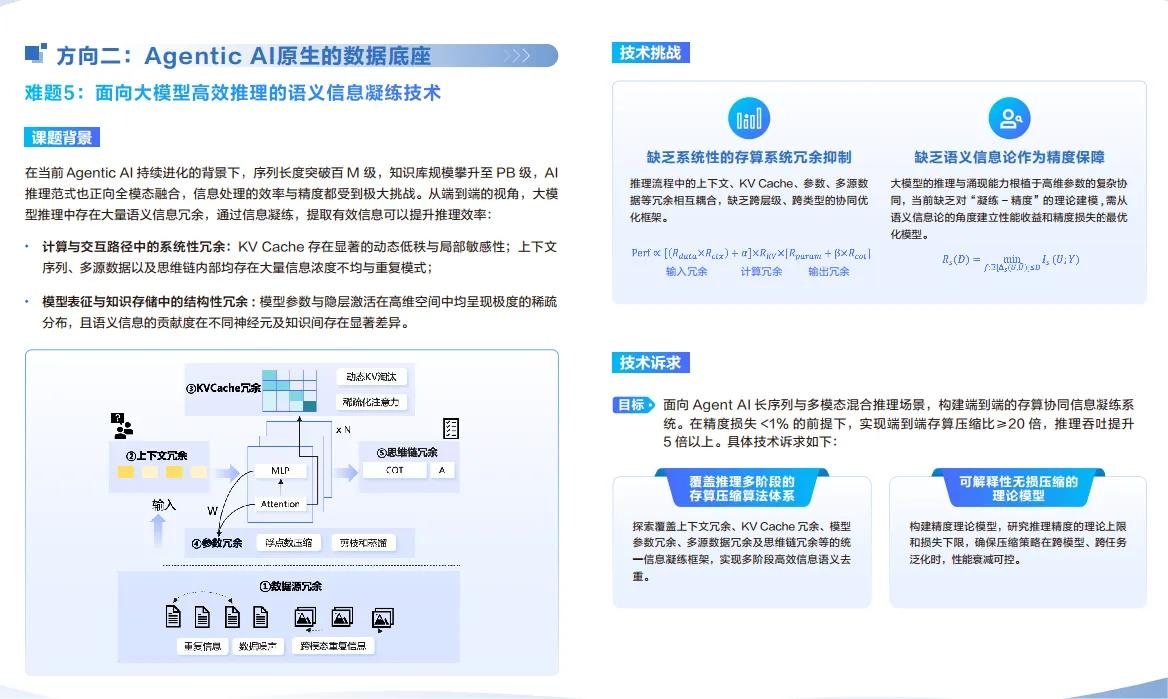
难题5:面向大模型高效推理的语义信息凝练技术
大模型推理的“上下文膨胀”是行业通病,万字文档会让token数超标,导致GPU内存溢出、推理速度骤降。这道题不是简单的文本压缩,而是要在剔除冗余信息的同时,完整保留核心语义与逻辑关联。传统压缩方法会让推理准确率下降20%,华为则要求凝练技术适配动态场景:自动驾驶的实时路况数据需毫秒级压缩且不遗漏异常特征,通用场景下上下文压缩率超80%且准确率损失低于5%。这一技术能让大模型走出云端,在边缘端、移动端实现高效推理,是AI从实验室走向普惠化的关键一步。
注释:
Token(词元) 是AI大模型处理文本的最小语义单元,可拆分为字符、词语等。
不少人认为300万奖金对顶尖技术而言杯水车薪,但华为的真实意图并非“买答案”。往届奥林帕斯奖的获奖技术,均直接融入华为OceanStor存储产品体系,获奖团队还能获得华为的算力支持与产业落地资源。这种做法意在打破产学研的技术壁垒,让实验室成果快速对接产业需求,更重要的是,这标志着AI竞争已从上层模型的“内卷”,转向底层底座的“攻坚”,谁掌握了存储与数据处理的核心技术,谁就能在下一代AI竞争中掌握话语权。而对科研者与中小企业来说,这也是切入AI底层赛道的绝佳机会,毕竟底座技术的突破,远比做一个跟风的大模型更具产业价值!
