[LG]《Understanding the Challenges in Iterative Generative Optimization with LLMs》A Nie, X Daull, Z Kuang, A Akkiraju… [CNRS & Stanford University & CMU] (2026)
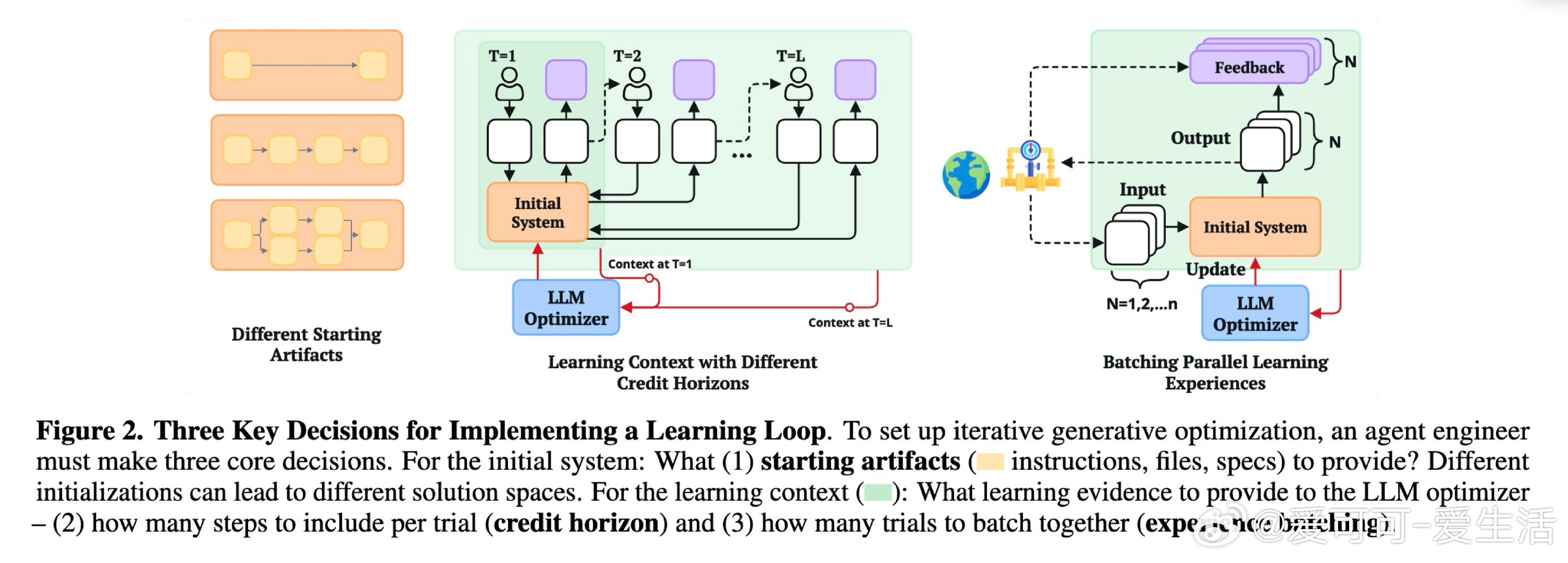
在智能体自动优化领域,如何让大语言模型通过执行反馈迭代改进自身系统,是通往自主进化代理的关键路径。然而现实中,尽管相关库已相当完善,仅有9%的生产系统采用了任何形式的自动优化。这一低采用率的根源,既非工具缺失,也非认知不足,而是隐藏在循环搭建过程中的三个工程决策,长期未被显式研究。
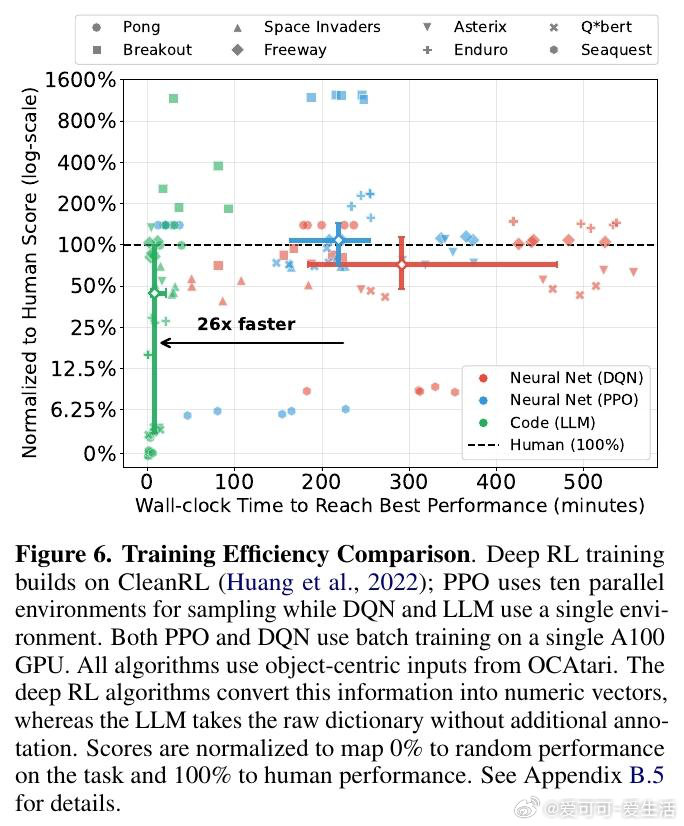
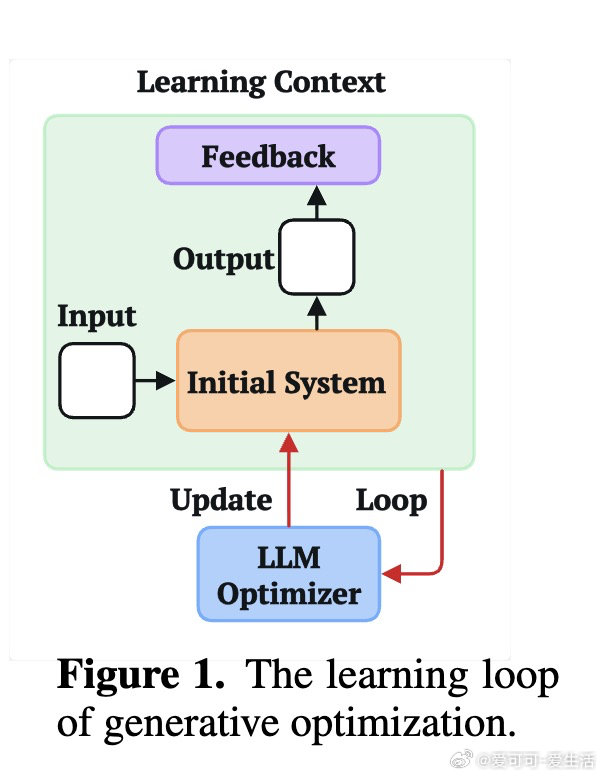
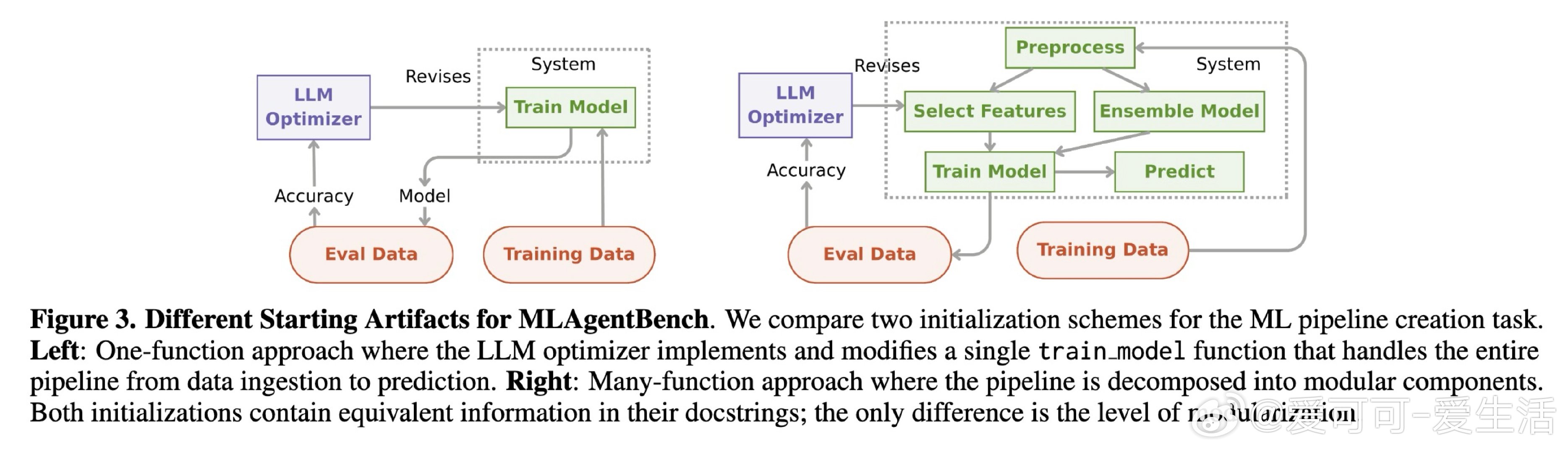
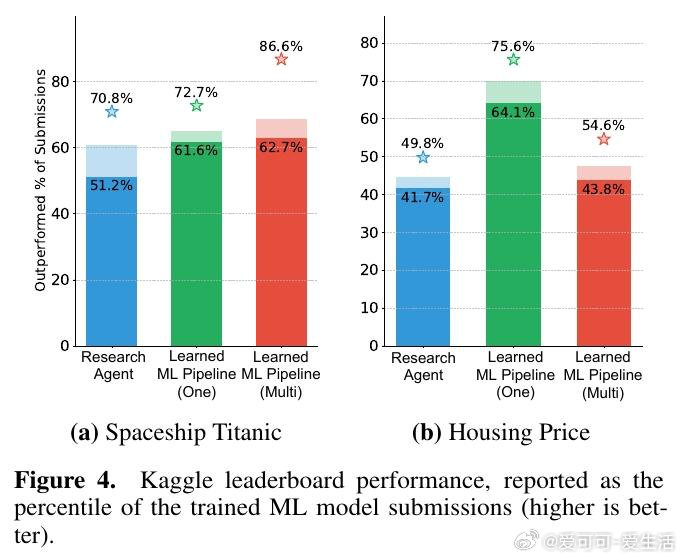
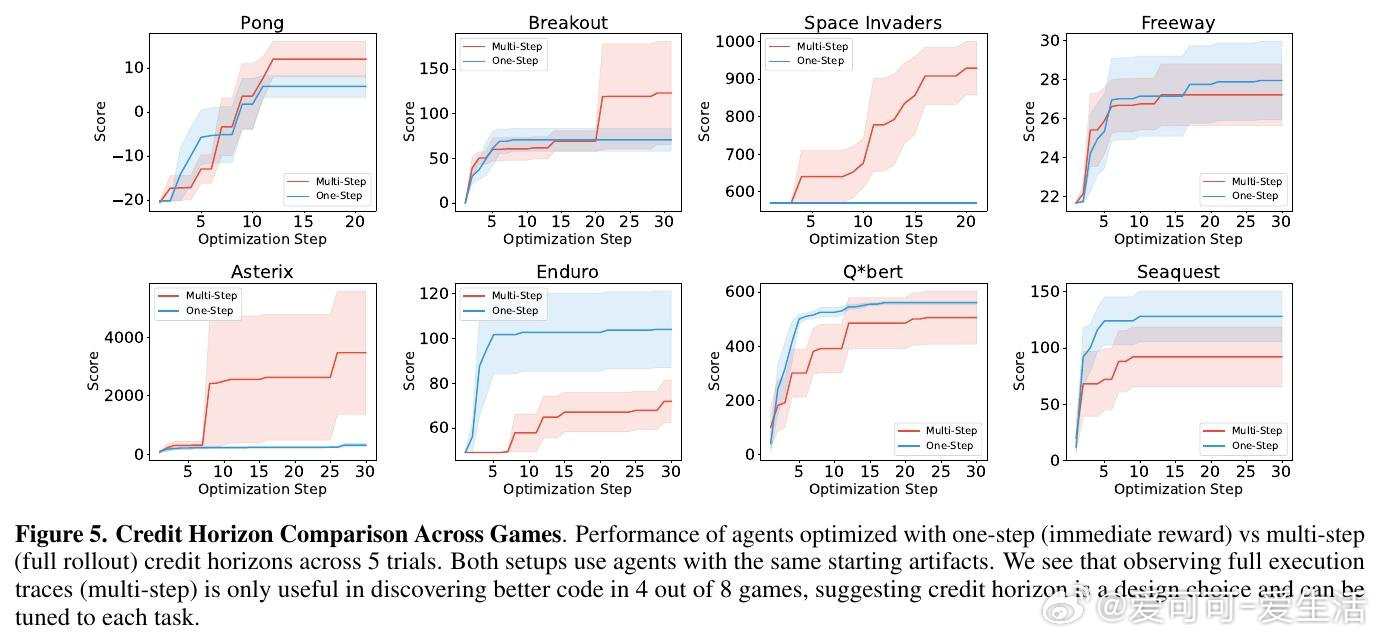
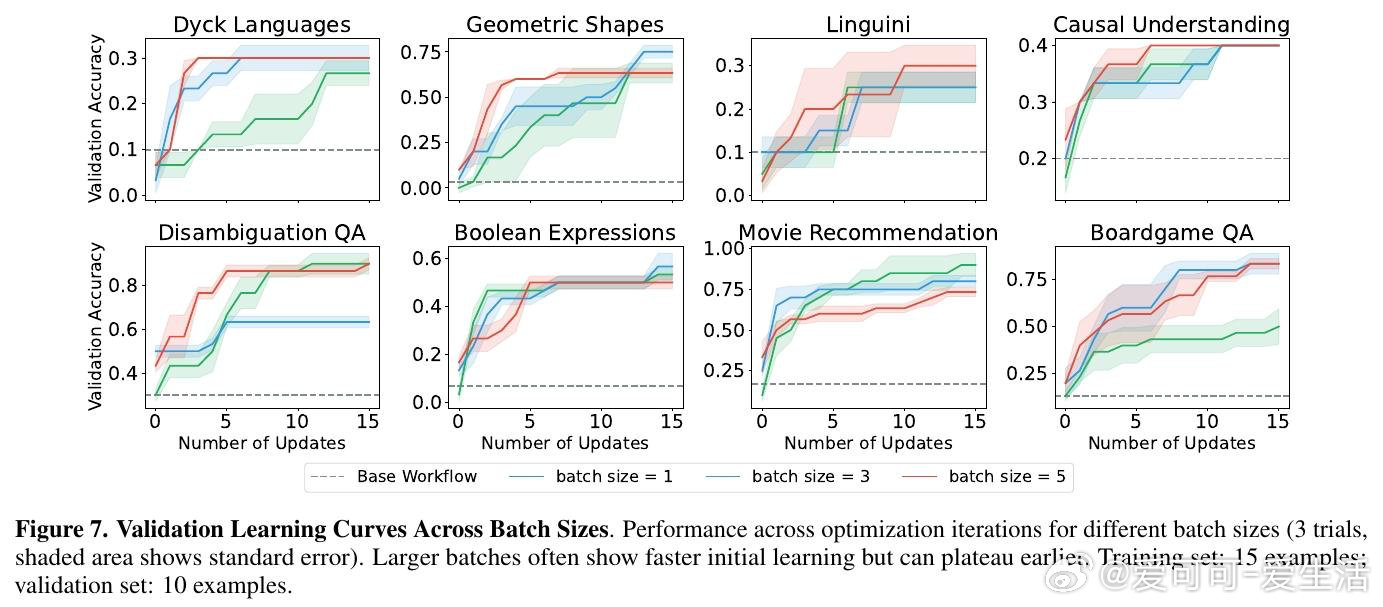
本文的核心洞见是:把LLM优化循环的搭建难题重新看作传统机器学习中已被系统研究的三类问题的类比。由此,围绕"起始制品选择""信用时域截断"和"经验批量大小"三个维度展开实验,研究者发现这些决策对最终性能的影响,足以决定优化成败——不同模块化程度的初始代码导致Kaggle排名相差近14个百分点,短时域奖励在半数Atari游戏中与长期成功对齐,而批量大小的最优值因任务而异且不单调。
这项工作真正留下的遗产是:将LLM优化循环的工程隐患从"玄学调参"提升为可系统研究的科学问题,并为每类决策提供了可操作的任务相关指南。它为后来者打开的新门是:借助ML理论框架(初始化、截断反向传播、随机梯度下降批量理论)来设计更鲁棒的通用优化默认值。但尚未跨过的门槛是:目前仍无跨任务通用的循环配置方案,每个新领域依然需要昂贵的超参搜索或人工经验介入。
arxiv.org/abs/2603.23994
机器学习 人工智能 论文 AI创造营