李想又发微博了,这次他说的是理想在底层实现了核心突破,也就是原生3d vit(真正的三维视觉编码器)。 他到底是什么?有什么用?今天就给大家简单聊几句其中的一些事。
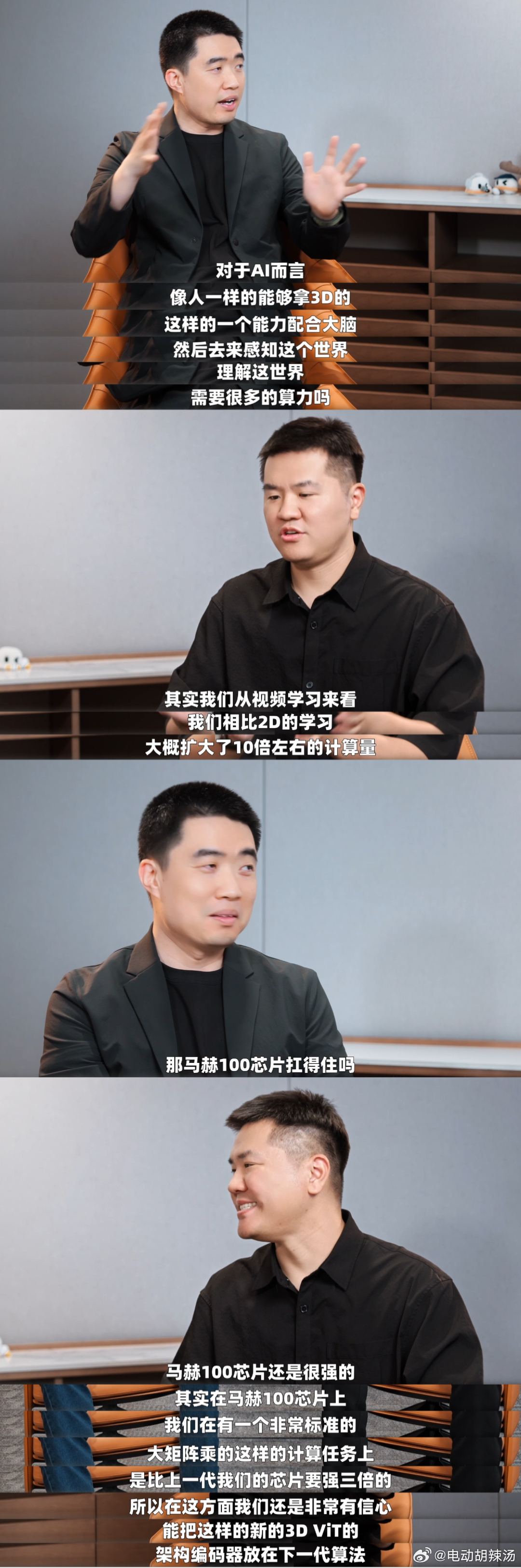
理想汽车在2026GTC 大会上,由基座模型负责人詹锟正式发布了最新自动驾驶基础模型 MindVLA-o1,把基础模型和原生3d vit联系在一起你就知道李想在说什么了。 过去很多年,自动驾驶发展缓慢,为什么?为什么人可以做好,自动驾驶却很难?因为人类在小时候就通过不断的训练学会了对三维物理空间的感知与理解。而自动驾驶模型却没有,模型训练一直更像是 看2d视频学开车。大家都用2D图片、2D视频做训练,只能识别物体、语义,没有真正的 3D 空间理解。它知道前面有车、有人,但对距离、深度、立体结构、物理空间的推理感知都是有缺失的。 而这一次理想的解决方案就是3D ViT+多模态思考,原生3dvit不再是从2d还原3d,而是让模型一开始就在真实的三维世界里去理解、去感知,不再只是单纯地看,而是身处其中地去理解、感受。
当然除了语言思考,模型在理解具体、形象化的物理空间关系时,还需要更多的对场景的想象和空间推演能力,今年年中的理想将让原生3d编码和大模型思考去结合,使模型能够真正理解三维空间并具备完整的3d认知能力。
那你可能又要问了,3dvit+多模态思考这么好,那为啥以前不干呢?是因为干不了,随着自研芯片的全面提升,才支撑得起这套技术落地。 有了原生 3D ViT,MindVLA-o1 第一次把空间理解、思考推理、驾驶行为统一在一个模型里,简单说就是不光看,还能分析、预测、感知,然后想清楚再去行动。 再展望一下,就是这一套 VLA 模型,不只车辆可用,同一套基座模型既能做自动驾驶,也能直接控制各类机器人。自动驾驶,只是物理 AI 的起点。
总结:从 2D 模仿到 3D 理解,从单一任务到多模态一体,从车用扩展到机器人通用 —— 理想这次的 MindVLA-o1,本质是把自动驾驶,推进到真正的物理世界 AI 时代。
李想称机器人也用VLA 理想发布下一代自动驾驶基础模型理想汽车