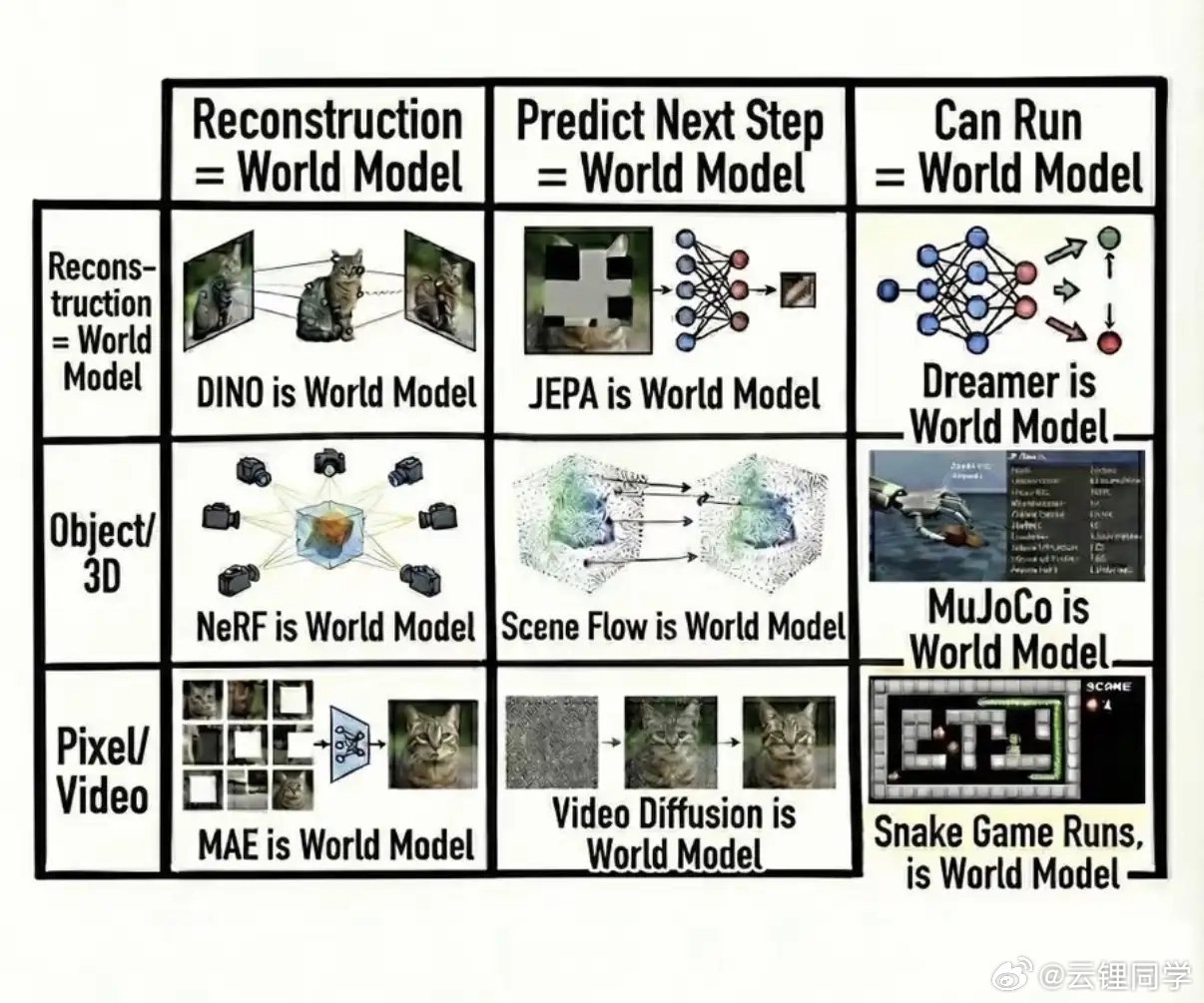
高保真渲染+视频预测+帧生成=世界模型?这其中的等号能不能画上,我持保留意见。
世界模型离我们想象中的有多远?这个问题放在现在依然适用。这其中的核心矛盾不在于世界模型路线在具身智能、自动驾驶领域的正确与否,而在于真正的世界模型,应该是更侧重「生成质量」还是「物理规律」。
从这个角度来看,我认为我们离「世界模型」的效果并算不遥远,但我们离「世界模型」的理念本身还是挺遥远的。
因此我其实挺欣赏鹏鹏这家企业的风格,他们似乎是非常注重「工具理性」的。很早提出保留语言Tokens的重要性、探索语义CoT的可行性,同时最大程度利用世界模型的精华来强化他们的云端基座,以实际效果产出的速度为第一要务,在2026年开年走在了行业前面。
当然,「世界模型」这一概念,从更广阔的行业视角来看,「价值理性」一定是重于「工具理性」的,因为最终的目标还是如何解决「物理一致性」问题,并让它回归到行业的主流价值取向。
举个不太恰当,但很有意思的类比:或许我们距离真正的physical intelligence的差距,大概可以类比我们距离固态电池真正大规模量产的差距吧。VLA行业观察