AI在医学领域终于能做生成式任务了,而且并不是简单的分类任务。这次,它成功将最常规的病理切片,“翻译”成原本昂贵而稀缺的免疫检测图像。
“我们用更便宜易得的病理图片,通过AI生成了更昂贵耗时的免疫组化图片,这是癌症免疫疗法领域的里程碑工作之一,可能会极大加速癌症的临床检测流程。”谈及这项发表在Cell的论文,美国华盛顿大学王晟教授对DeepTech如是说。

近期,微软研究院潘海峰博士、华盛顿大学王晟教授团队合作,开发了一种AI框架GigaTIME,基于多模态AI技术,实现了将医院中常规的癌症病理切片(H&E染色)转化为多通道免疫荧光(mIF,multipleximmunofluorescence)。
该研究不仅展示了从H&E生成mIF图片的可能性,更重要的是,基于虚拟图片实现了下游的临床发现:研究人员将GigaTIME应用于1.4万余名病人的H&E图像中,这些数据来自美国最大的医疗机构ProvidenceHealth,共包括美国7个州、51家医院和1,000多家诊所。
研究人员一次性生成了近30万张虚拟mIF全切片图像,涵盖24种癌症类型和306种亚型。凭借这些空前规模的数据,研究人员系统地揭示了1,200多个蛋白质和生物标志物(如TP53、KRAS突变、TMB、MSI等)、病理分期(TNM分期)与具体癌症及亚型的关键联系。
这些数据有助于理解肿瘤免疫逃逸的机制,并首次基于此预测病人生存时间和初步评估免疫疗法的药效。目前,研究团队已公开预训练的GigaTIME模型代码,为肿瘤微环境大规模建模、临床生物标志物发现及精准免疫治疗方面提供了新的思路。
相关论文以《多模态人工智能生成肿瘤微环境建模的虚拟人群》(MultimodalAIgeneratesvirtualpopulationfortumormicroenvironmentmodeling)为题发表在Cell[1]。

当病理图像学会“翻译”另一种检测
H&E染色作为临床常规病理检查的基础技术之一,其优势是成本低且应用范围广泛,即便欠发达地区也能实现,但它的局限性在于细胞形态和组织结构。
相对而言,mIF是一种多重蛋白质空间表达信息的金标准技术,尽管其能够准确反映癌症病人状态,但因成本高和通量低难以大规模应用。目前,只有极少数发达国家、顶尖医院才配备mIF。
从检测技术价格来看,一个显著对比是:病理图片仅需要20-50美元,从切片、染色、封固全流程最快半天完成;由于人力与试剂成本高,免疫荧光/免疫组化相关检测通常需要1,500美元,用时至少5天。
临床中的一个长期的“恶性循环”是:因为不了解mIF图像到底在哪类病人、哪种蛋白质、哪种癌症上有用,所以临床上不会花几千美金做mIF检测;因而做mIF检测的病人数量很少,更难收集大规模数据;没有数据,又反过来不知道哪里有用。
这项研究始于ProvidenceHealth提出的实际临床需求:是否有可能将低成本的H&E图像生成更高价值的mIF图像?
此前,病理专家基于医学图像推断病人肿瘤状态:如果只有便宜的医学图像,需要资深专家才能基于此进行推断;而一旦有了高价值、更清晰的医学图像,普通专家甚至刚入门的病理医生也能做出准确判断。
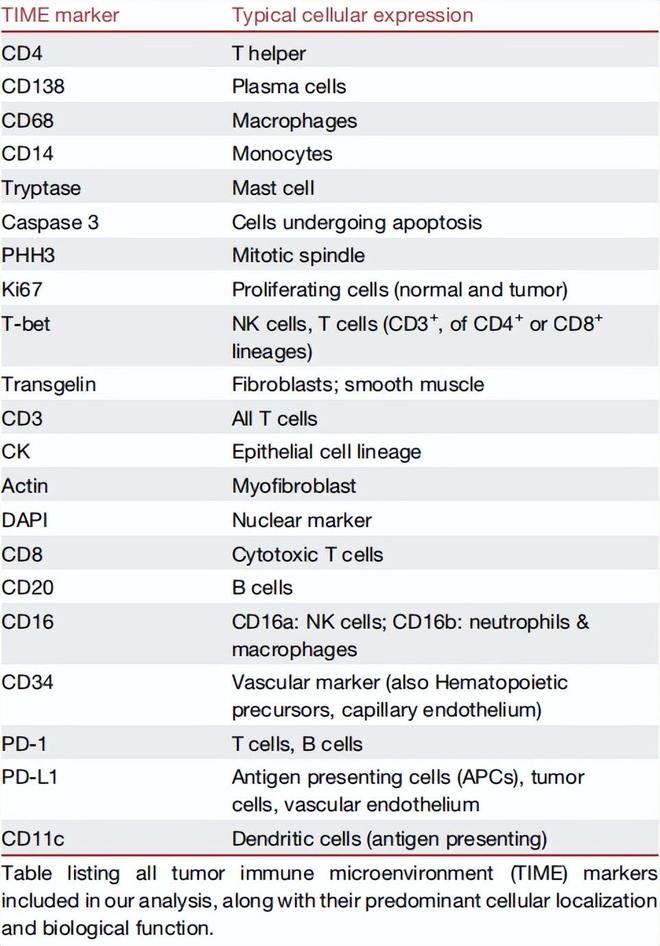
跨模态翻译模型是GigaTIME的核心所在。基于深度学习算法在不依赖昂贵试剂和复杂设备的条件下,将H&E染色切片转化为高分辨率的虚拟的mIF图像。研究人员对4,000万细胞的配对H&E和mIF数据进行训练,涵盖了21种蛋白质通道。
多模态AI技术的最大优势,是让模型同时“吃透”不同模态的数据,实现数据利用效率最大化,而不是给每种模态单独训一个模型。也就是说,各模态间共享的特征信息能同时被迁移。
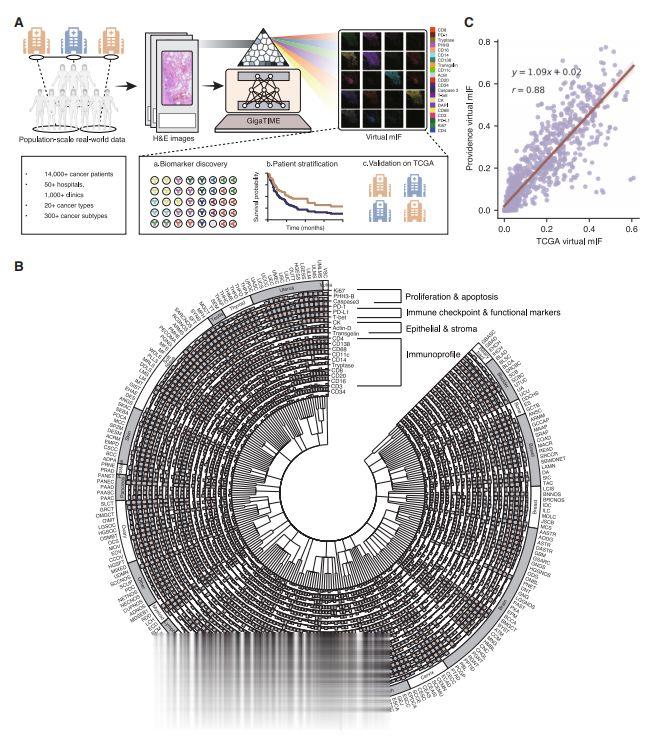
此外,GigaTIME的虚拟人群可根据虚拟蛋白质的激活状态,支持对病理阶段和病人分层的系统性研究,并预测病理分析与生存期。
通过整合所有21个虚拟蛋白质通道,GigaTIME能够更有效地对病人进行分层,预测癌症分期和生存结果。传统病理指标只能靠H&E图像分层,而这项研究使用的虚拟mIF图像分层是传统手段无法实现的。
从泛癌水平角度,GigaTIME发现肿瘤大小(T阶段)与免疫检查点标记物(如PD-L1和PD-1)以及免疫浸润标记物(如CD68和CD138)呈正相关。
研究人员进一步在特定癌种和亚型水平进行了深入研究。即便虚拟mIF是从H&E生成,其分层效果仍优于真实的H&E图像。未来某些癌症亚型可能继续用便宜的真实H&E分层更好,但在另一些亚型上,用虚拟的mIF图像分层效果更佳。
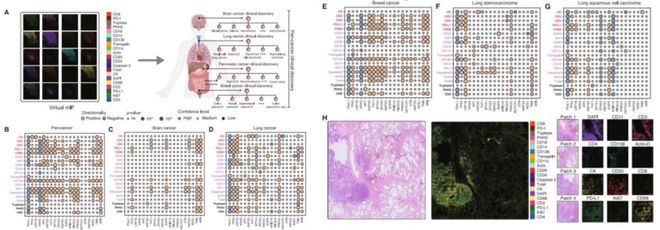
“我们并非要全盘取代传统指标,而是为不同亚型、不同人种、不同病人提供另一种分层工具,以补充现有临床分层的不足。”王晟表示。
此外,GigaTIME还揭示了蛋白质激活之间的协同作用。通过结合浆细胞标记物CD138和巨噬细胞标记物CD68的虚拟激活,研究人员发现,该组合与多个生物标志物的关联强于单独的蛋白质。这种协同作用有可能反映了抗体介导的免疫反应,其中浆细胞产生的抗体可激活巨噬细胞攻击肿瘤细胞。
30万张虚拟mIF图像,是如何被“算”出来的?
研究团队在数据预处理方面投入了大量精力。由于使用的是临床真实病人数据,而不是为研究特意新建的数据集,因此必须从医院现有病历里筛出“高质量、多样化、又不过于罕见”的病例。同时,图像本身还要统一染色、去噪、对齐等。
研究人员发现,此前领域内只有简单数细胞,但这些远远不够,更关键的图像层面空间特征仍然空白。
为此,他们搭建了一整套科研流程,并加上了数据、模型、验证的相关指标。“我们直接借用了传统图像领域已被反复验证、久经考验的空间指标,首次把它们搬到免疫图像分析里。通过大量实验和摸索捋顺了这套预处理流程,未来从事该方向的研究人员可以直接沿用。”王晟表示。
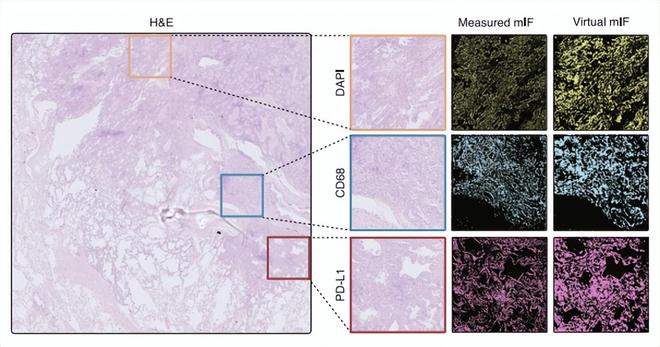
另一方面,将训练好的AI模型应用到1.4万余名病人,并一次性生成30万张虚拟mIF图像也带来了不小的挑战。为解决GPU/CPU资源大量消耗的问题,研究人员进行了大量纯工程层面的并行优化,将生成周期压到1-2个月,并使用了微软研究院提供的海量计算集群。
GigaTIME相当于用简单图像学习出复杂图像,就像搭起了一座桥梁,通过为初级病理医生提供高价值图像参考,缩短其从初级到专家的学习和经验累积周期。
“得益于生成式AI近年来的发展和进步,我们把海量真实的成对数据喂给AI模型,再用生成式AI技术把模型建起来,这个全新的医学问题才有了这种新的方案。”王晟表示。
数据规模带来的直接影响是,临床流程因此显著降低了成本。研究团队用AI虚拟手段打破了传统的“恶性循环”:生物学家和医生在得到这些关键信息后,相当于可“按图索骥”大致判断哪些蛋白质可能关键,有了突破后再针对特定的蛋白,用较低的成本补做真实的mIF检测以及深入挖掘。
比如,当医生发现某些蛋白质在肝癌中具有关键作用,就大规模给肝癌病人上真实mIF,同时配合虚拟图像,真实数据量随之暴涨,最终让mIF变成临床常规技术。
用虚拟图像开启“数字试验”新范式
王晟指出,虚拟细胞、虚拟图片方向的AI技术,并不会取代医生或取代生物学家。AI承载的使命并不是从头到尾地“包办”新药开发和科学发现,而是通过生成虚拟病人、虚拟样本来验证医生或生物学家所开发药物的效果。
用AI生成虚拟病人做疗效和毒性的验证,相当于AI生成的“数字小白鼠”来做实验,不仅可以大幅度提高开发效率,也能降低试药对受试者带来的损伤。“生成式AI更像是一个用于验证的高通量数字试验平台,这也是团队后续持续推广的方向。”他说。
此前,领域内只能基于真实的mIF数据推断哪些蛋白质对癌症重要。王晟指出,尽管近30万张虚拟的mIF图像未必像真实图像那样完美,但它能清晰地看到蛋白质和癌症之间的显著关系,这也是这项工作中最大的贡献之一。
未来,研究团队希望通过引入更多前沿AI技术来生成医学图像和病人特征,来解决更多以往难以解决的问题。
此前,研究团队在Nature报道了数字病理学全切片基础模型GigaPath[2],其中针对肺癌的一项指标已在美国纪念斯隆凯特琳癌症中心完成临床验证。本次研究是上以工作的延续,需要了解的是其并非覆盖所有癌种,从癌症种类来看,这项研究中核心验证的是肺癌,其次是脑癌和胃癌。
目前,研究团队正在开展更大规模的跨人种、跨国家的数据验证,预计数月后会呈现初步结果。后续验证若持续成功,将继续扩展到更多国家验证,并进入临床审批等环节。
基于本次H&E到mIF的跨模态生成技术基础,他们计划在接下来的研究中进一步突破模态边界,打通病理图片与影像科图片之间的关联。其希望未来不仅用H&E图像生成病人的mIF,还能进一步用CT、X光、核磁共振成像这类影像科图像,配合少量病理图来更好地生成mIF。
“即便H&E图像病人也需半天时间,还要打麻药、取切片。如果能用更简单的CT或核磁图像,能减少对病人带来的创伤。”王晟说。
现在,该团队正致力于构建一个更大的多模态模型,不仅将影像科图像纳入其中,未来还将加入DNA、基因等更多种类数据,其终极目标是形成能统一理解各种模态生物医学临床数据的超大模型。
这或许预示着,医学正在从“一次检测得到一个结果”,走向“一个模型理解整个病人”。
参考资料:
1.https://doi.org/10.1016/j.cell.2025.11.016
2.https://doi.org/10.1038/s41586-024-07441-w
排版:刘雅坤