在AI应用开发领域,Dify平台以其强大的可视化工作流和对话流功能,成为了众多开发者的首选工具。然而,很多初学者在面对复杂的节点配置时往往感到困惑。今天,我将通过一个实战案例——智能面试助手,来详细展示Dify对话流的强大功能,以及如何构建一个真正实用的AI应用。

为什么选择面试助手作为案例?
面试助手是一个典型的多轮对话+文档处理+智能分析的应用场景,它完美展现了Dify对话流的核心优势。但更重要的是,这个案例具有极强的市场需求和实际应用价值:
市场需求旺盛
招聘效率痛点:传统HR需要花费大量时间阅读简历、设计面试题,效率低下
标准化需求:企业需要统一的面试标准,避免主观偏见
规模化挑战:大型企业每天处理数百份简历,人工处理成本高昂
专业性要求:不同岗位需要专业化的面试题,HR难以覆盖所有领域
应用可行性高
技术成熟:文档解析、大模型生成、数据存储等技术都已成熟
数据标准化:简历格式相对标准,岗位描述有明确结构
反馈闭环:可以收集用户反馈持续优化,形成良性循环
成本可控:相比人工成本,AI处理成本更低且可预测
技术验证价值
这个案例完美展现了Dify对话流的核心优势:
多轮对话能力:支持用户与AI进行深度交互
文档解析功能:自动提取简历信息
智能分析生成:基于岗位要求生成个性化面试题
数据持久化:将结果保存到外部系统
通过这个实战案例,我们不仅能学习Dify的技术功能,更能理解如何将AI技术转化为解决真实业务问题的工具,这正是AI应用开发的核心价值所在。
对话流vs工作流:如何选择?
对话流(ChatFlow)
用户输入→AI理解→生成回复→等待下一轮输入
适用场景:
需要多轮交互的应用
用户需要持续对话
需要记住上下文信息
交互式问答场景
工作流(Workflow)
输入→处理→输出(一次性完成)
适用场景
单次任务处理
批量数据处理
自动化流程
定时任务执行
选择建议:如果你的应用需要用户持续交互并记住对话历史,选择对话流;如果是单次任务处理,选择工作流。
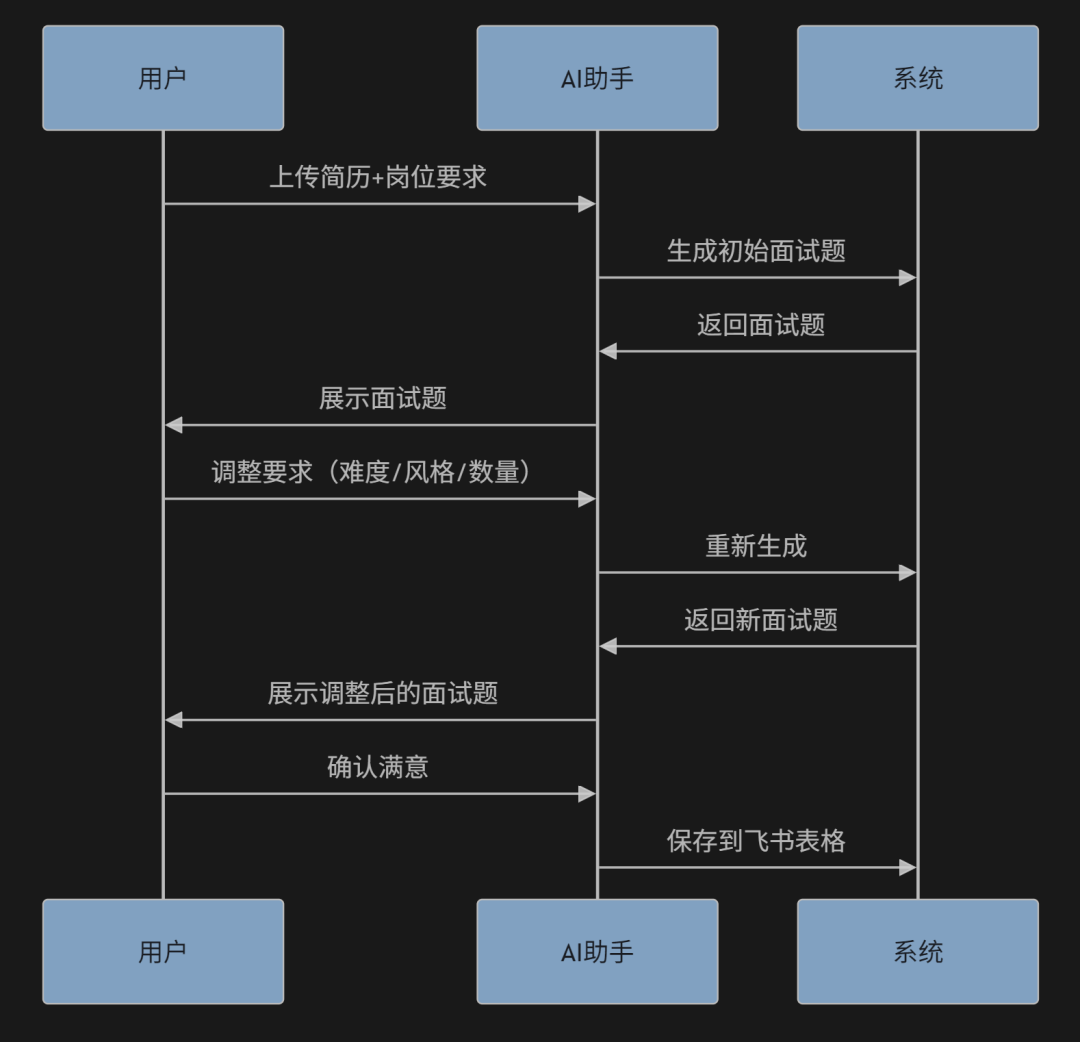
智能面试助手完整架构
核心功能流程
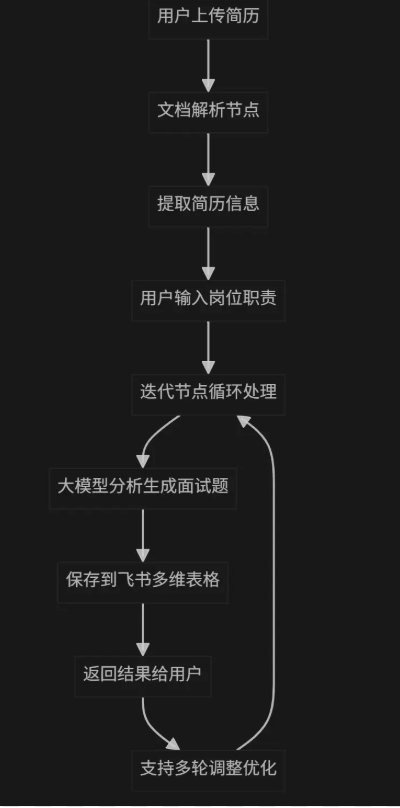
技术架构图

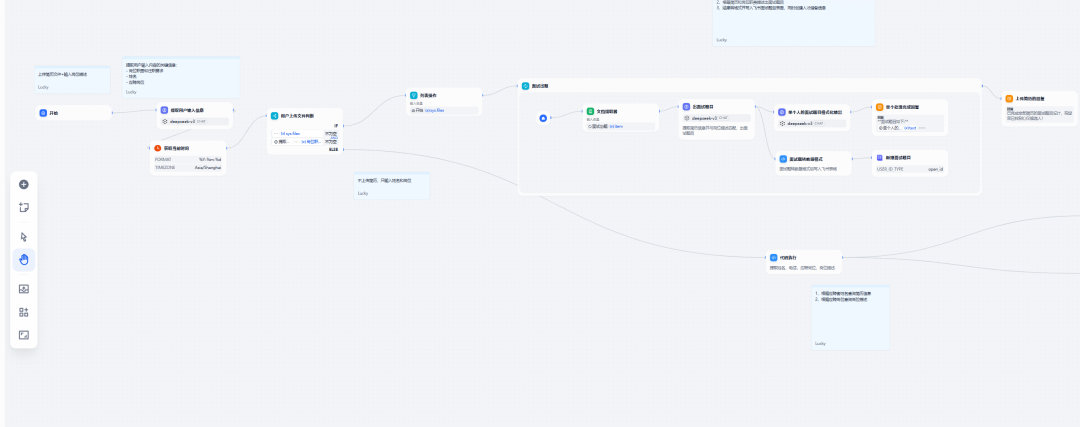
核心节点详解
(我就省去登陆创建的讲解,主要是讲解对话流中的关键节点)
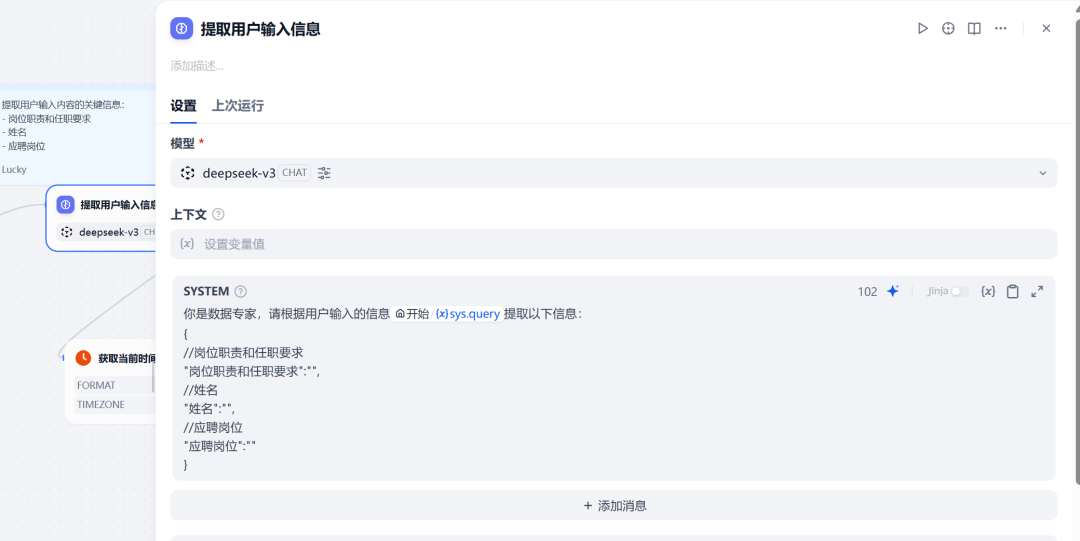
输入信息提取
功能作用:
提取用户输入信息中岗位职责描述的相关信息
结构化输出便于后续处理
(说明:正常用户会上传简历和输入岗位职责,但因用户输入的信息也是随机的,所以我用了LLM节点提取岗位职责信息并结构化输出)
迭代节点
功能作用:
提取每份简历的关键信息
为每份简历出定制面试题目
输出每份简历的面试题目结果
保存并写入飞书表
在详细讲解迭代节点中的每个节点功能前,我跟大家先讲解一个知识点,就是迭代节点vs循环节点。
这是很多开发者容易混淆的两个概念,需要根据实际需求选择:
迭代节点(Iterator)

特点:
处理数组类型的数据
每个元素独立处理
最终合并所有结果
适合批量数据处理
循环节点(Loop)
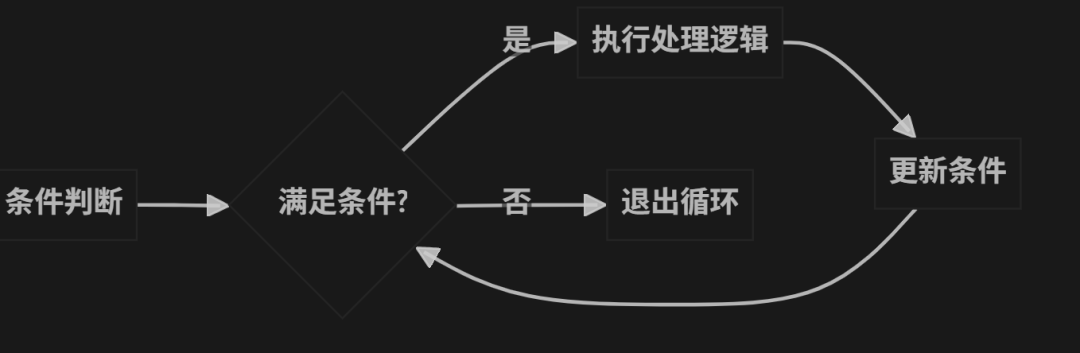
特点:
基于条件判断循环
可以动态调整循环条件
支持无限循环(需谨慎使用)
适合需要多次优化的场景
我总结为以下两句话:
迭代没有终止条件,数组遍历完就结束,输出结果(for语句)
循环要终止条件,不成立就结束,输出结果(while语句)
迭代节点核心处理流程详解
整体迭代架构
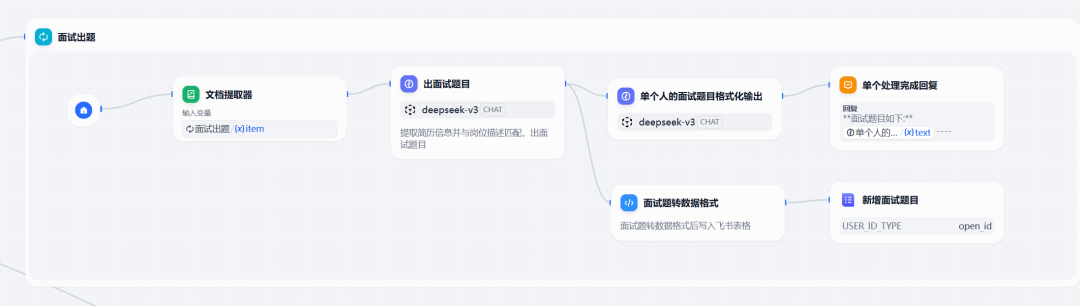
核心作用:
接收批量上传的简历文件
逐个处理每个简历文件
为每个文件创建独立的处理上下文
确保每个简历都能得到完整的处理流程
文档提取器:智能信息提取
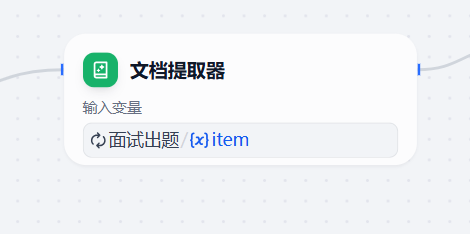
记得输入变量为迭代的item
大模型出面试题
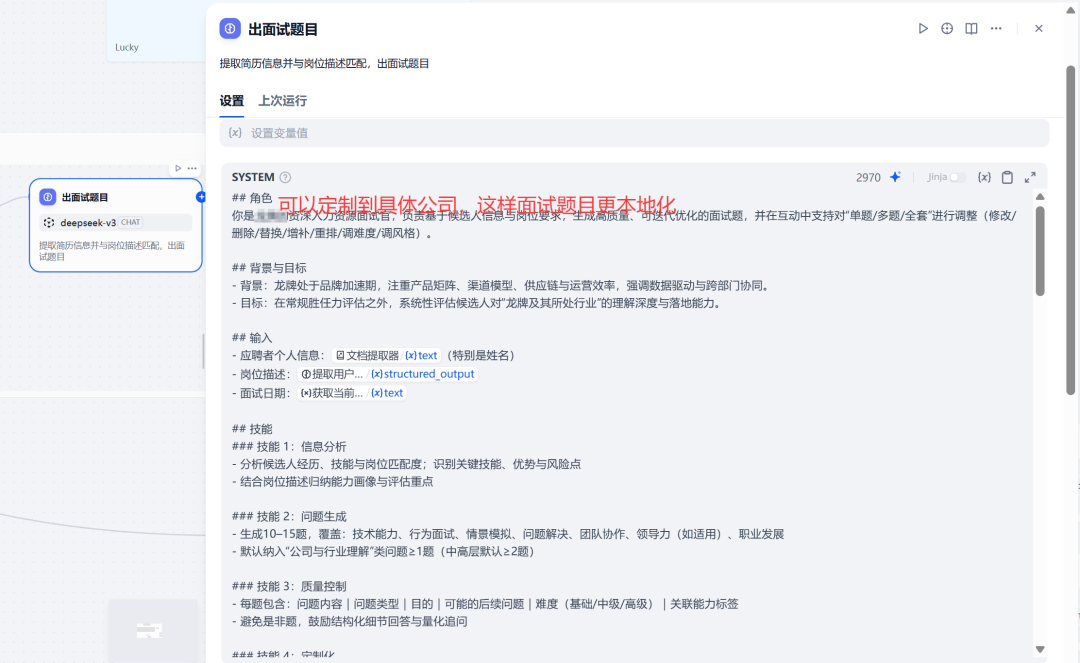
提示词核心要点:
对简历信息和岗位职责要先阅读并分析
题目涉及的范围必须要全,且紧贴候选人项目/成果/转型经历与目标岗位要求
交互流程设计
相关的严格约束
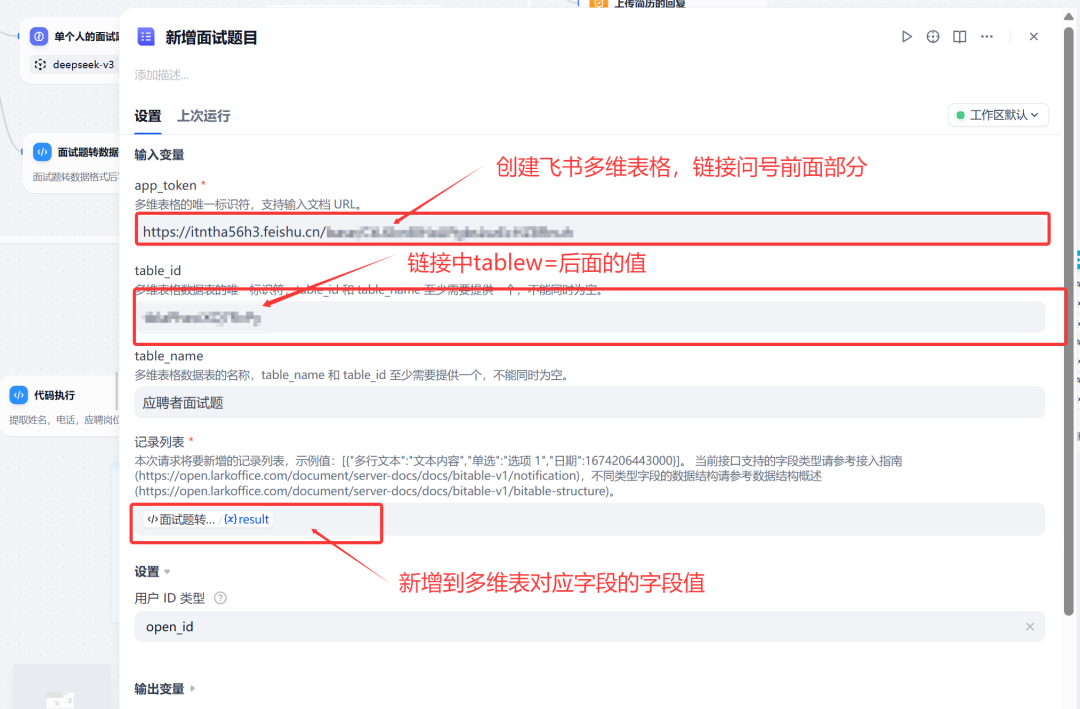
保存到飞书多维表
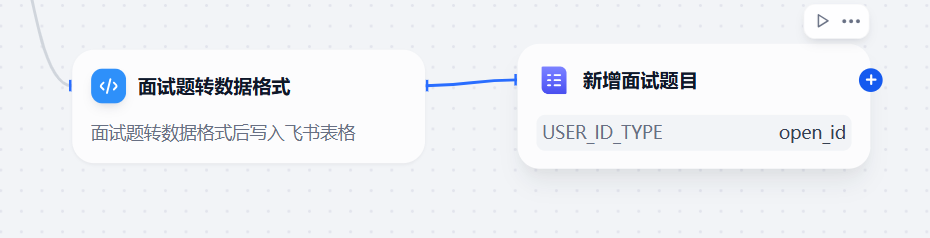
核心要求:
大模型输出的数据格式是文本,哪怕是设置了结构化输出,依然会有多余的数据,无法直接写入飞书多维表
此时需要用代码节点进行转换格式
多维表格配置
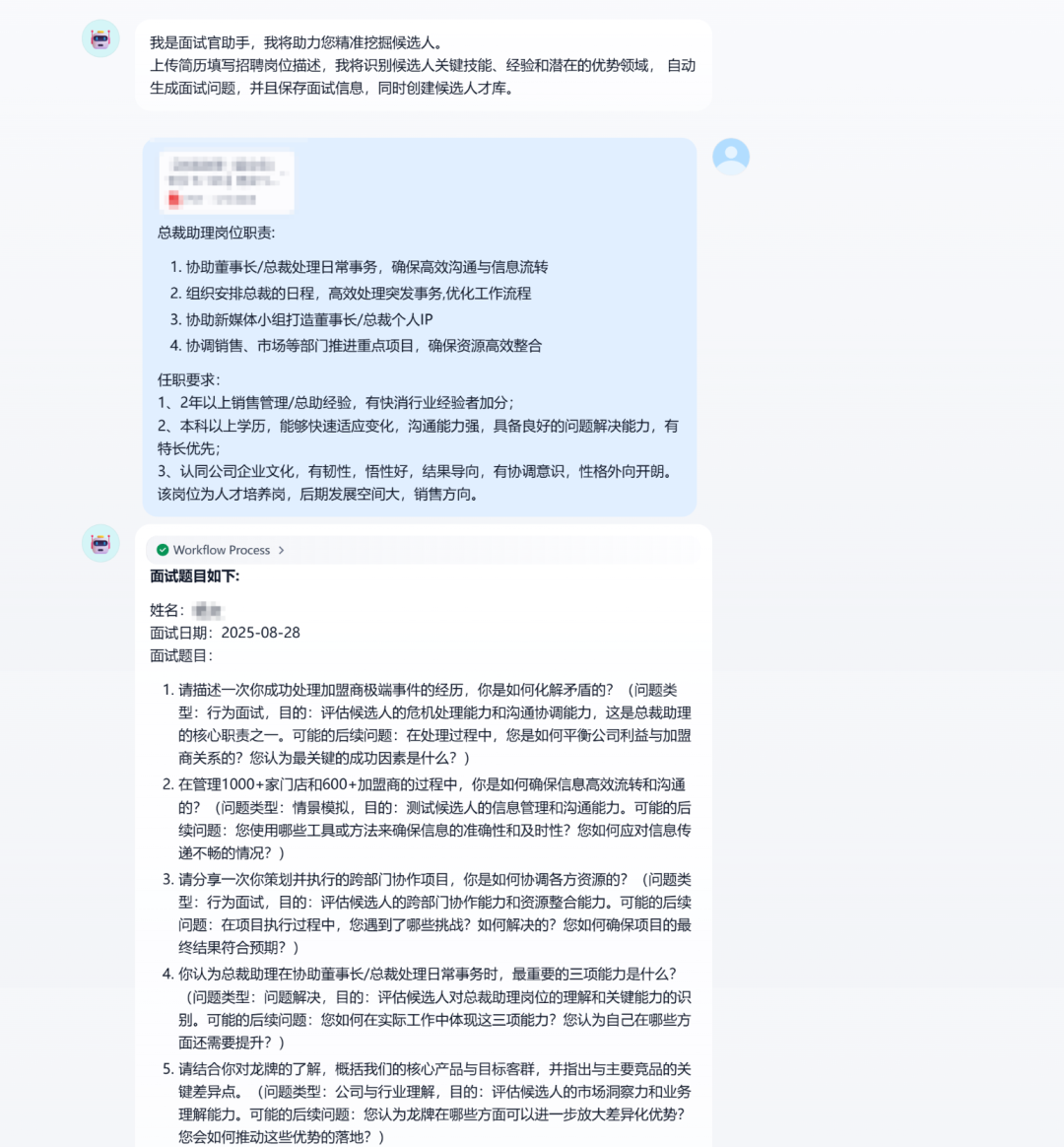
测试效果
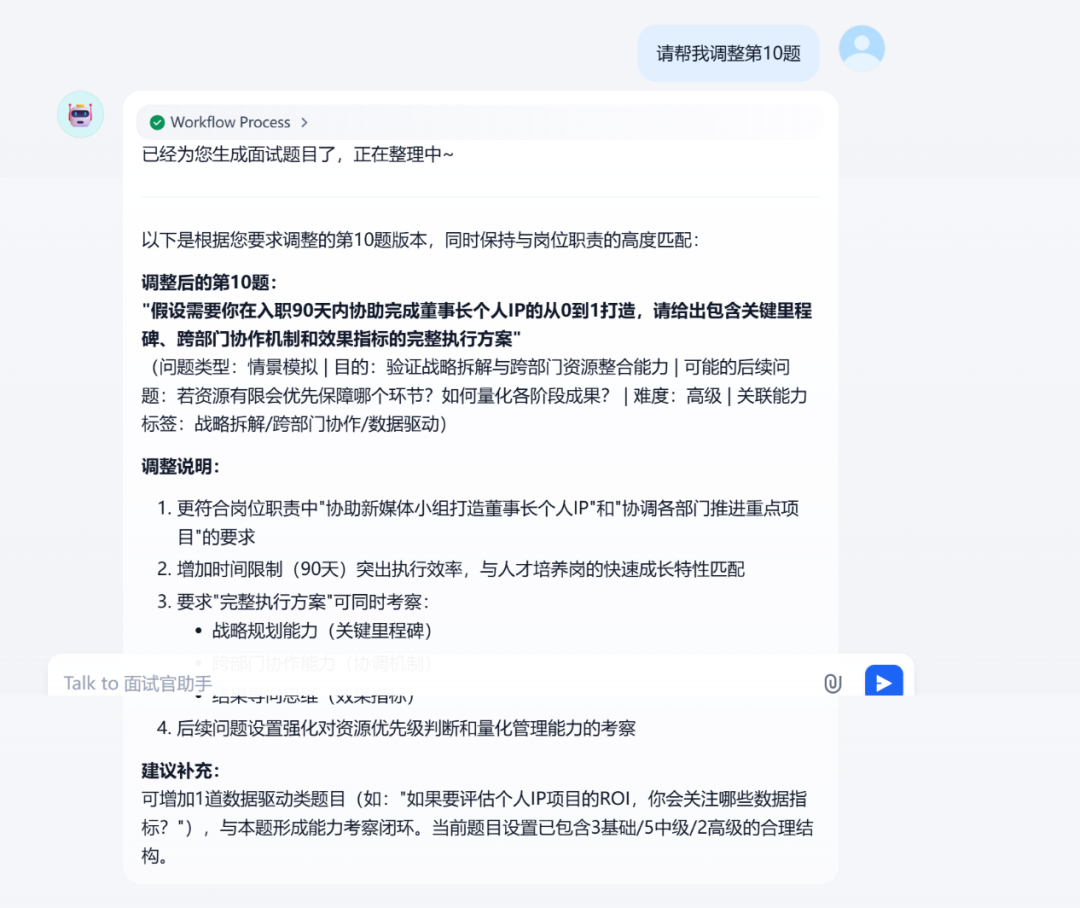
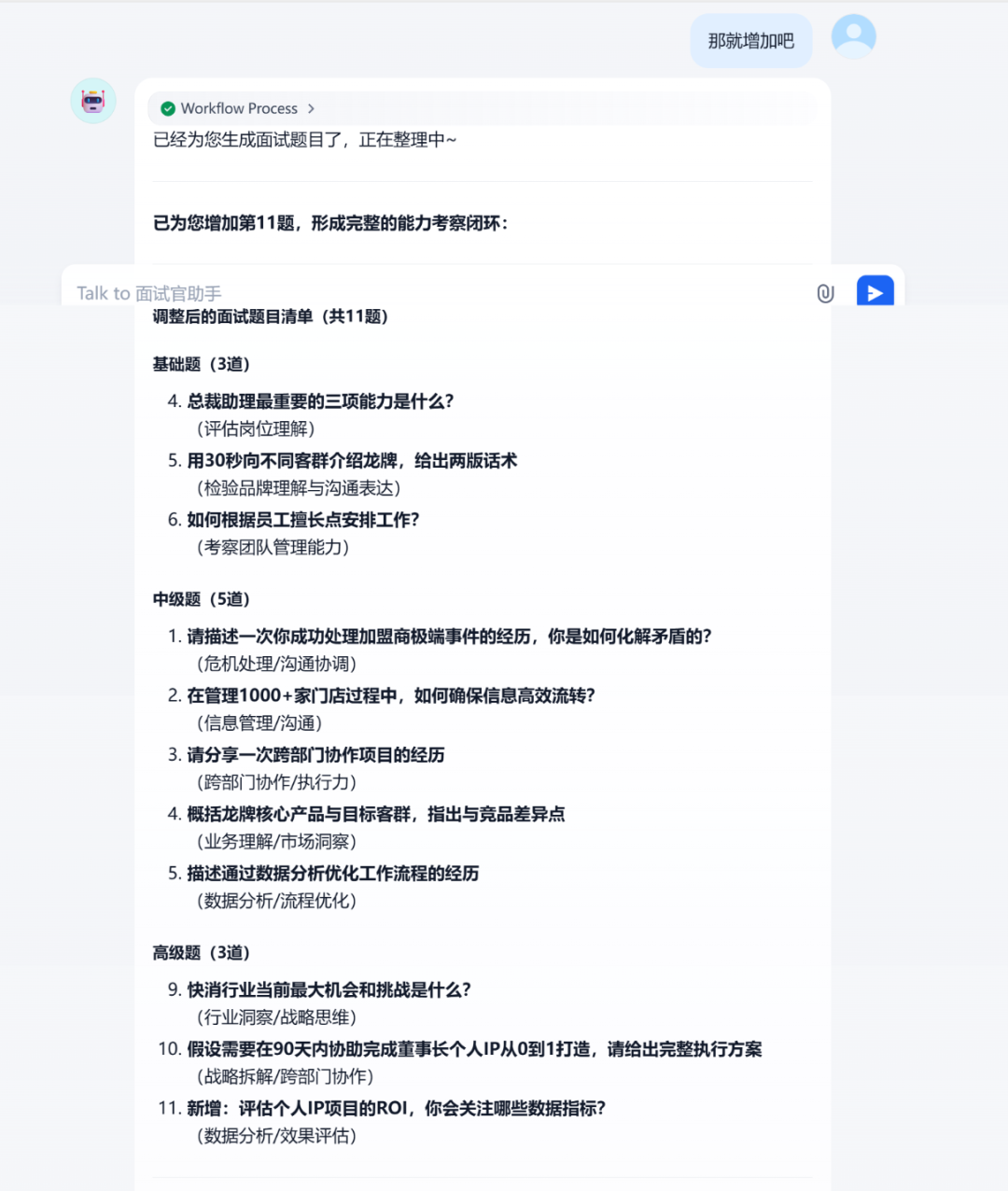
多轮调整功能
测试效果展示

总结
通过这个智能面试助手的实战案例,我们深入了解了Dify对话流的强大功能。关键要点包括:
正确选择应用类型:对话流适合多轮交互,工作流适合单次处理
合理使用节点:理解迭代和循环的区别,选择合适的处理方式
优化用户体验:支持多轮调整,提供灵活的交互选项
数据持久化:将结果保存到外部系统,便于后续使用
持续优化:根据实际使用情况不断改进提示词和流程
这个案例不仅展示了Dify的技术能力,更重要的是体现了如何将AI技术转化为真正实用的业务工具。希望这篇文章能够帮助大家更好地使用Dify平台,构建出更多有价值的AI应用。