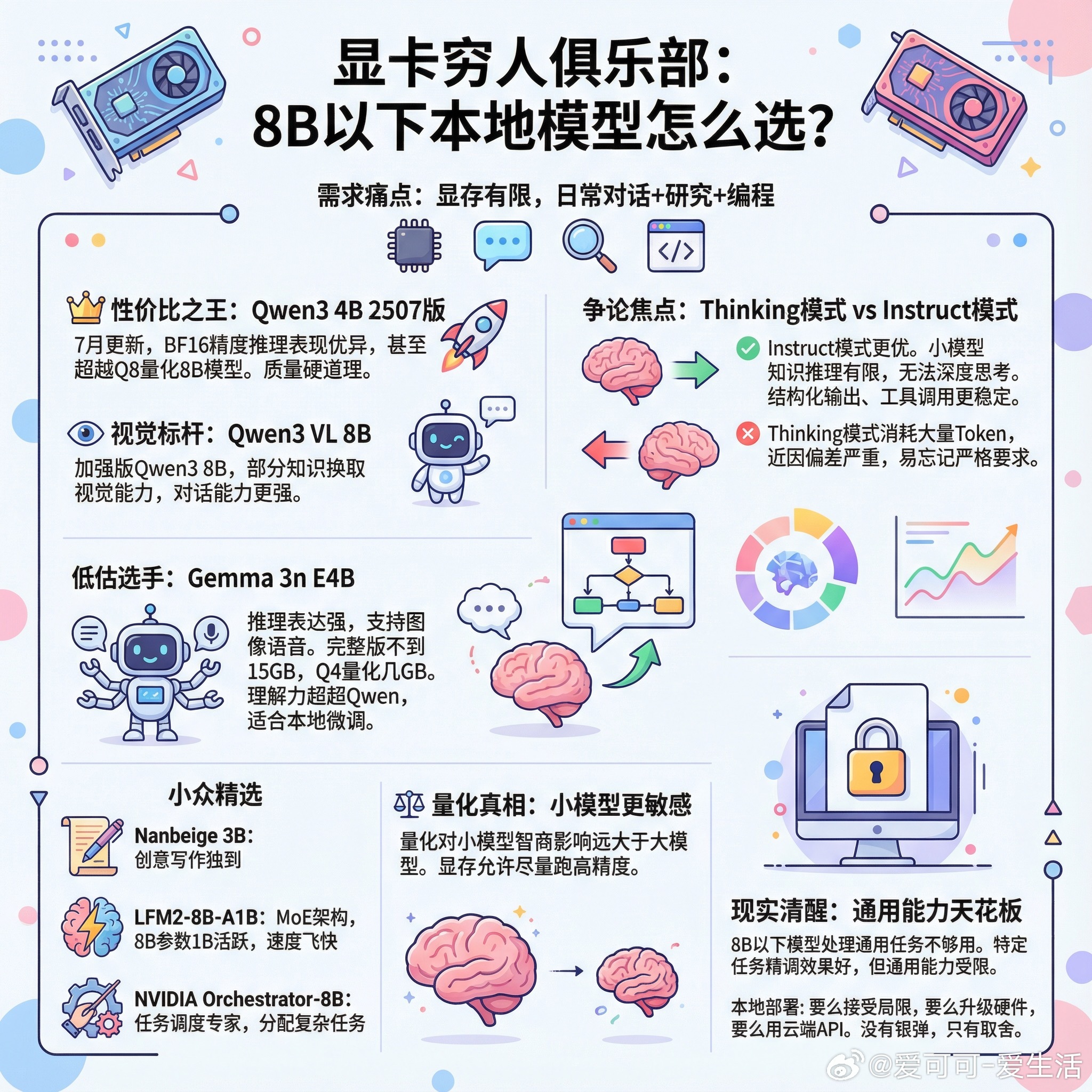
【显卡穷人俱乐部:8B以下本地模型怎么选?】最近Reddit上有个热帖引发了一场关于小参数本地模型的大讨论。提问者的需求很典型:想跑本地模型,显存有限,需要兼顾日常对话、研究和编程,审查别太严。社区给出的答案相当有料。目前公认的性价比之王是Qwen3 4B 2507版本。这个模型在7月经过更新重发,用BF16精度跑推理任务时,表现甚至超过同体积Q8量化的8B模型。质量就是硬道理。而Qwen3 VL 8B则是视觉模型里的标杆,本质上可以看作“加强版Qwen3 8B”,对话能力更强,只是用部分知识换了视觉能力。一个有意思的争论是:小模型到底该用Thinking模式还是Instruct模式?有位开发者给出了非常专业的分析:对于4B这个量级,Instruct几乎在所有场景下都更优。原因很直接——小模型的知识储备和推理能力有限,根本无法像前沿大模型那样通过深度思考实现突破。它们要么能理解任务,要么就是不能,中间没有“想通了”这个选项。更关键的是,Thinking模式会消耗大量token,而小模型的近因偏差更严重,思考完一大段后往往会忘记最初的严格要求。结构化输出、工具调用这些场景,Instruct模式的表现明显更稳定。另一个值得关注的模型是Gemma 3n E4B。这是个被低估的选手,推理和表达能力都很强,还支持图像和语音理解,完整版不到15GB,Q4量化后只要几个GB。有人认为它在理解力上超过了Qwen。而且它特别适合本地微调,低显存显卡也能跑。还有几个小众但值得一试的选择:Nanbeige 3B在创意写作上有独到之处;LFM2-8B-A1B是个MoE架构,8B参数但只有1B活跃,速度飞快;英伟达新出的Orchestrator-8B专门做任务调度,不自己回答问题,而是把复杂任务分配给不同工具处理。关于量化,有个容易被忽视的事实:量化对小模型的影响远比大模型严重。大模型即使压到Q2、Q3还能凑合用,小模型一压就明显掉智商。所以如果显存允许,小模型尽量跑高精度。最后是一个清醒的声音:如果你真的需要一个通用型助手来处理日常对话、研究和编程,8B以下的模型坦白说都不够用。它们可以在特定任务上通过精调达到很好的效果,但通用能力确实有天花板。这大概就是本地部署的现实:要么接受局限,要么升级硬件,要么老老实实用云端API。没有银弹,只有取舍。reddit.com/r/LocalLLaMA/comments/1qcl54which_are_the_top_llms_under_8b_right_now