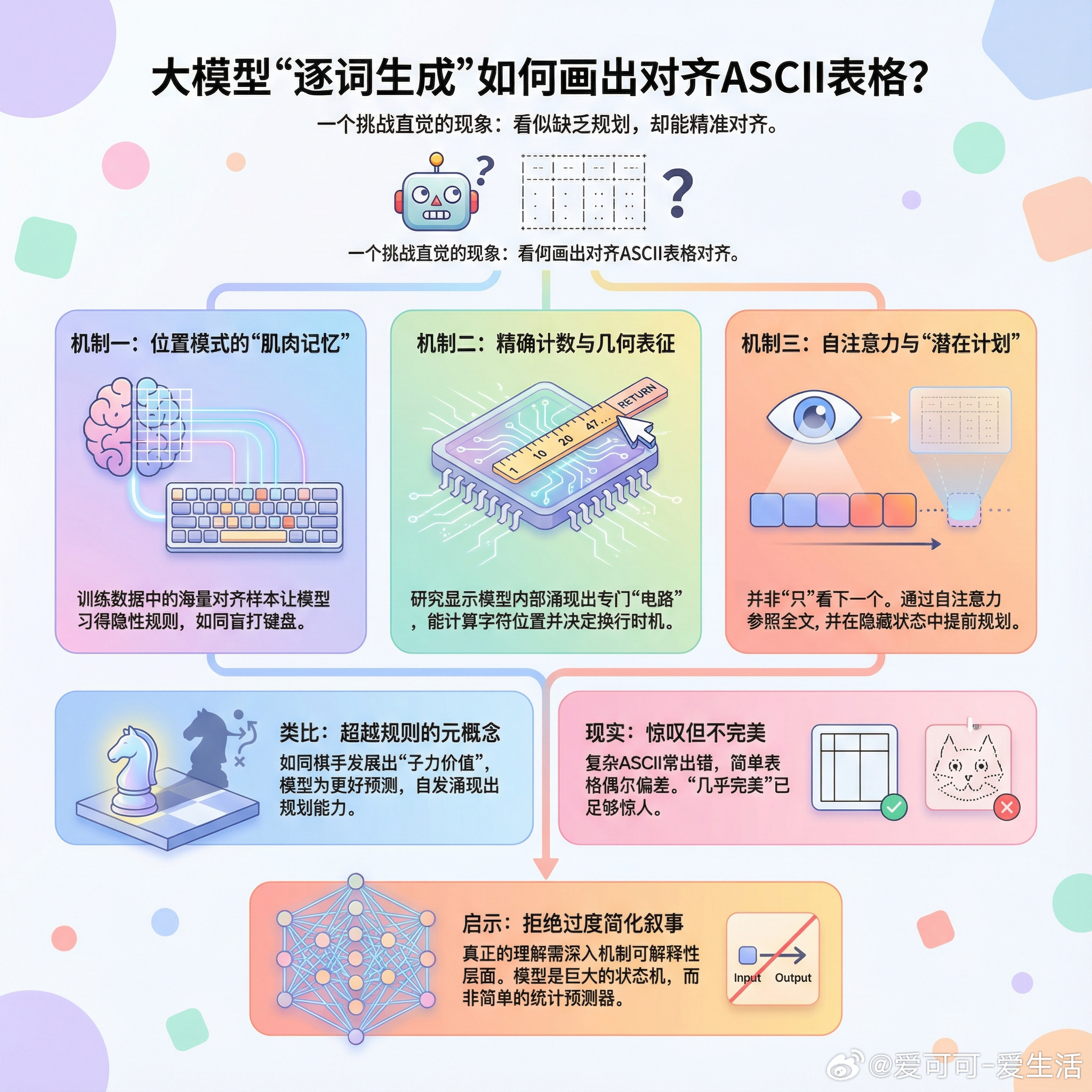
【大模型只看下一个词,为何能画出对齐的ASCII表格?】一个看似简单却直击本质的问题:大语言模型明明是逐个token生成的,为什么能画出几乎完美对齐的ASCII表格和图表?这个问题之所以有趣,是因为它挑战了我们对“下一个token预测”这个简化叙事的理解。画一个ASCII框,你得提前知道框的宽度,才能在正确的位置放上那个竖线。如果模型真的只看眼前,这似乎是不可能的。讨论中涌现出几个值得深思的解释:第一,位置模式的“肌肉记忆”。模型在训练时见过海量对齐的ASCII表格,它学会了一种隐性规则:第三行第47个字符应该和第一行第47个字符对齐——就像你不用看键盘也知道每个字母在哪里。第二,模型确实学会了精确计数。Anthropic的研究揭示了一个惊人发现:模型内部发展出了几何表征能力,能够计算字符位置来决定在哪里换行。这不是巧合,而是涌现出的专门“电路”。第三,也是最关键的一点:模型并非“只”关注下一个token。通过自注意力机制,每个新token都在参照上下文窗口中的所有前文。更重要的是,研究表明模型在隐藏状态中携带着“潜在计划”——当被要求写押韵诗时,它会在输出那些韵脚之前就已经规划好可能的押韵词。这让我想到一个类比:国际象棋的规则里没有“子力价值”或“位置优势”的概念,但棋手发展出这些元概念来更好地理解和规划棋局。同样,“预测下一个token”是训练目标,但模型为了更好地完成这个目标,自发涌现出了规划能力。把大模型简化为“统计预测下一个词”,就像把人脑简化为“电信号输入输出”一样粗暴。模型内部有海量中间状态,使其表现得像一个巨大的状态机,而状态机可以是图灵完备的。当然,诚实地说,这种对齐并非完美。复杂的真实物体ASCII艺术经常出错,简单表格也偶有一两个字符的偏差。但“几乎完美”本身就足够令人惊叹。这个问题的价值在于:它提醒我们,对大模型工作原理的流行叙事往往过于简化。真正的理解,需要深入到机制可解释性的层面。x.com/ahmetb/status/2011519932719382926