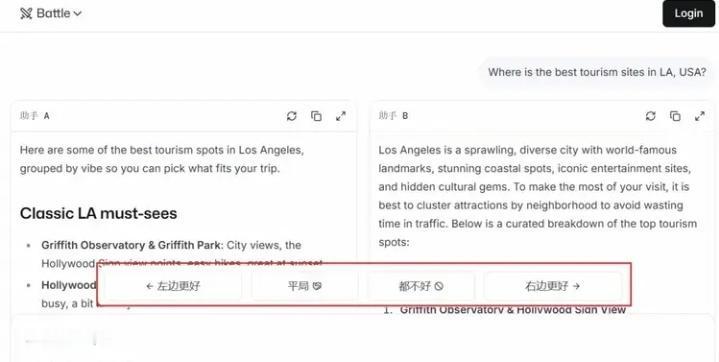
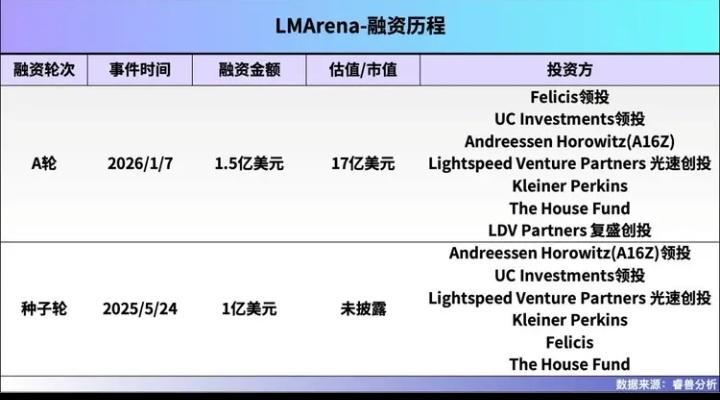
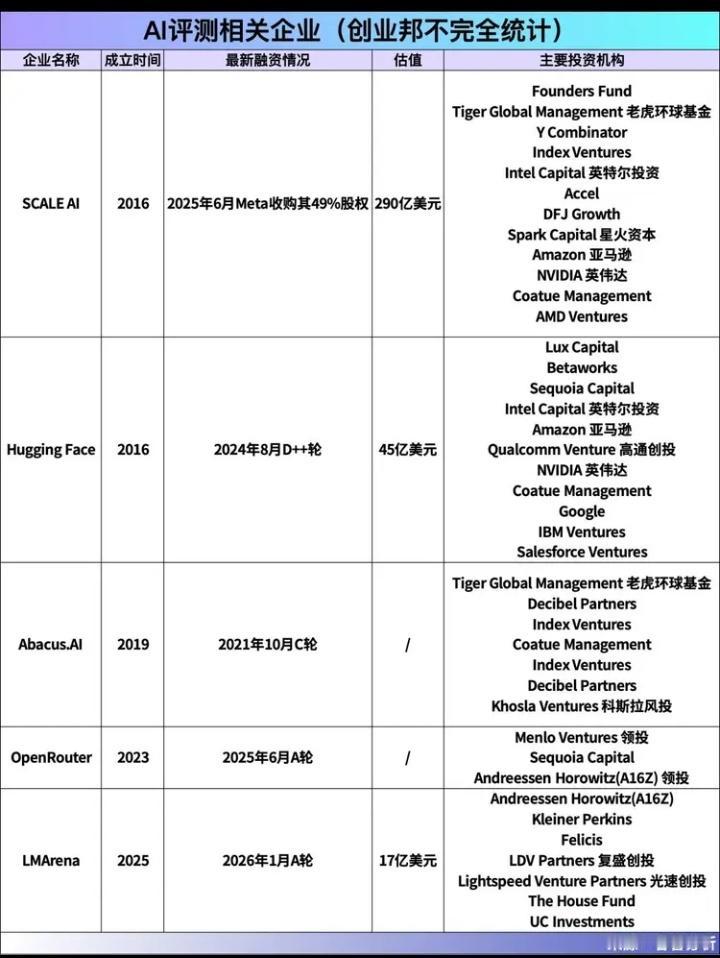
伯克利两博士玩转AI“选秀”:一年狂揽120亿,你的每次点击都在为独角兽投票! 当所有人都在埋头造AI模型时,两个来自加州大学伯克利分校的博士,却选择了一条与众不同的路——他们不做“选手”,而是当起了“裁判”。仅仅一年时间,他们打造的AI模型“竞技场”LMArena,估值已冲破17亿美元大关,成为硅谷最炙手可热的独角兽。这背后,是数百万普通用户每一次不经意的点击与选择,共同堆砌起的百亿帝国。 你或许从未想过,自己在某个无聊的午后,随手比较两个AI答案哪个更顺眼,这个微小的动作,正成为驱动AI进化的重要燃料。LMArena的核心,正是这样一个简单到极致的逻辑:将全球顶尖的AI模型匿名两两PK,把选择权完全交给用户。你的偏好,直接决定了模型的排名。 这听起来像是一场大型的、永不落幕的“AI超女”选拔赛。而两位博士创始人,Anastasios Angelopoulos和Wei‑Lin Chiang,则如同掌握了流量密码的制片人。他们从学术项目Chatbot Arena起步,敏锐地捕捉到了AI爆发时代最隐秘的痛点:当模型多如牛毛,谁更可靠?谁能真正理解人类? 资本用真金白银投下了信任票。硅谷顶级风投a16z等机构接连下注,两轮融资豪掷2.5亿美元。投资人看到的,不是一个技术壁垒高不可攀的工具,而是一个可能定义AI时代“质量标准”的平台。当AI要进入医疗、法律、金融等严肃领域,一个中立、基于海量人类真实反馈的“信任印章”,价值连城。 然而,争议随之而来。一个依靠大众“投票”的排行榜,真的可靠吗?批评者尖锐指出,这就像让路人决定哪位科学家的论文更优秀——用户可能仅仅因为答案更长、带了表情符号就投票,而非其真正的正确性与深度。甚至出现过用户集体为一道数学题的错误答案“点赞”的尴尬情况。 这恰恰戳中了人性与技术的微妙冲突。我们渴望AI严谨如科学家,却又本能地偏爱那些说话好听、体贴幽默的“伙伴”。LMArena的排行榜,某种程度上映射的正是人类这种矛盾的偏好:我们是在评选最“正确”的AI,还是最“讨喜”的AI?这个问题,连它的设计者也在不断反思与平衡。 放眼全球,AI测评战场已是硝烟四起。有像LiveBench那样,由“AI教父”杨立昆背书、专注防作弊硬核考试的“学术派”;也有像OpenRouter那样,直接看API调用量的“市场派”。而在中国,虽有OpenCompass、SuperCLUE等榜单聚焦中文场景,但像LMArena这样引发全球资本狂潮的商业化测评平台,仍属空白。 这不禁让人深思,在AI狂飙的赛道上,最大的金矿或许不是挖矿的锄头,而是那把检验金子成色的秤。LMArena的故事告诉我们,在技术高歌猛进时,衡量与评价体系本身,就是一门足以孕育独角兽的顶级生意。它满足了人类对秩序、对可比性的根本需求。 回到最初,每一次你面对屏幕,在两个AI答案间做出选择时,你不仅是在表达喜好,更是在无形中参与塑造AI的未来走向。这个百亿估值的故事,由全球数百万像你一样的用户共同书写。当技术日益复杂,或许最简单的“人的选择”,反而成了最珍贵的标尺。这场由伯克利博士发起的AI“全民公投”,最终会将我们带向何方?时间,会给出答案。 (来源:创业邦) AI测评 百亿独角兽