IT之家1月6日消息,科技媒体TechPowerUp今天(1月6日)发布博文,报道称在CES2026展会期间,英伟达发布了DGXSpark和DGXStation两款桌面级AI超级计算机,宣告本地AI开发进入“超算时代”。
这两款设备基于最新的NVIDIAGraceBlackwell架构,配备大容量统一内存和Petaflop(千万亿次)级AI性能。

其核心目标是让开发者、研究人员和数据科学家无需依赖云端集群,即可在本地桌面上开发、微调并运行从1000亿到1万亿参数的开源及前沿AI模型,打通了从本地原型设计到云端大规模扩展的通道。
DGXSpark:平衡效能与便携
作为入门级旗舰,DGXSpark专为1000亿参数级别的模型设计。该系统引入了NVFP4数据格式,能将AI模型压缩高达70%且不损失智能表现。

图源:英伟达
在实际应用场景中,DGXSpark展现了惊人的性能优势:在运行BlackForestLabs的FLUX.2等视频生成模型时,其速度相比搭载M4Max芯片的顶级MacBookPro快了8倍。
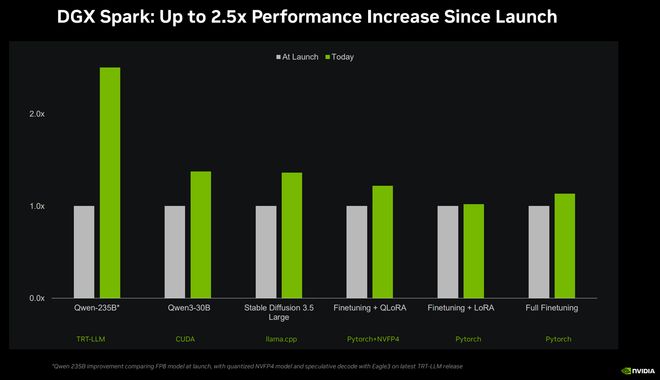

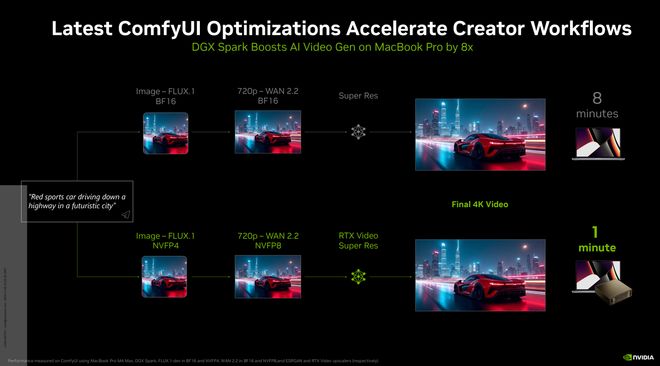
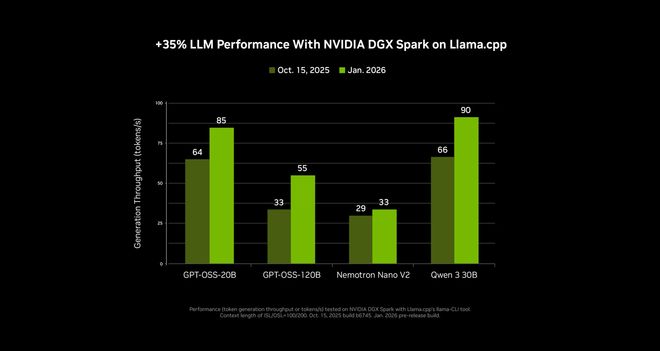
此外,英伟达优化与开源社区(如llama.cpp)的深度合作,该系统在运行SOTA(最先进)模型时平均性能提升了35%,并显著加快了LLM(大语言模型)的加载速度。
DGXStation:单机运行万亿参数模型
面向企业级和前沿实验室的DGXStation则不仅是性能怪兽,更是行业标杆。该机型搭载GB300GraceBlackwellUltra超级芯片,配备高达775GB的FP4精度一致性内存,这一配置让其能够本地运行高达1万亿参数的巨型模型。
IT之家注:一致性内存(CoherentMemory)指在CPU和GPU之间共享同一地址空间并实现硬件级数据同步的架构,通过2026年主流的NVLink-C2C或PCIeGen6/7互连技术,数据可以在不同处理器间自由流动,无需显式的内存拷贝过程,显著降低了延迟。
FP4精度是一种4位浮点格式(通常采用1位符号、2位指数、1位尾数的E2M1布局),专为Blackwell及后续Rubin架构优化,能在保持模型精度的前提下,将显存占用降低至FP16的四分之一,吞吐量提升高达2-3倍。
英伟达明确列出了其支持的一系列前沿模型,包括Kimi-K2Thinking、DeepSeek-V3.2、MistralLarge3、MetaLlama4Maverick以及OpenAIgpt-oss-120b。
vLLM核心维护者KaichaoYou表示,DGXStation改变了开发动态,让团队能以极低成本在本地测试GB300专属特性。
为了构建完整的本地AI生态,NVIDIA宣布了多项软件与合作伙伴计划。DGXSpark现已支持NVIDIAAIEnterprise软件栈,并提供了针对机器人(如HuggingFaceReachyMini)、基因组学和金融分析的全新开发手册(Playbooks)。
在硬件供应方面,DGXSpark及合作伙伴推出的GB10系统即日起通过戴尔、惠普、联想、华硕等厂商发售,而旗舰级的DGXStation将于今年晚些时候正式上市。