VLA即视觉语言动作模型,能让机器通过“看”和“听”理解世界并直接输出动作指令,核心是“端到端”处理,无需人工设定规则。与蔚来“世界模型”不同,VLA侧重即时反应,适合处理突发情况;而世界模型通过模拟“数字世界”来预测未来,优化长期策略。VLA对智能驾驶的推进作用主要体现在深度决策上,能通过大量数据训练,自己总结出应对各种场景的策略,甚至处理未见过的状况。V LA与世界模型各有优势,未来可能结合使用,让智能驾驶更安全、聪明,提升驾驶体验。


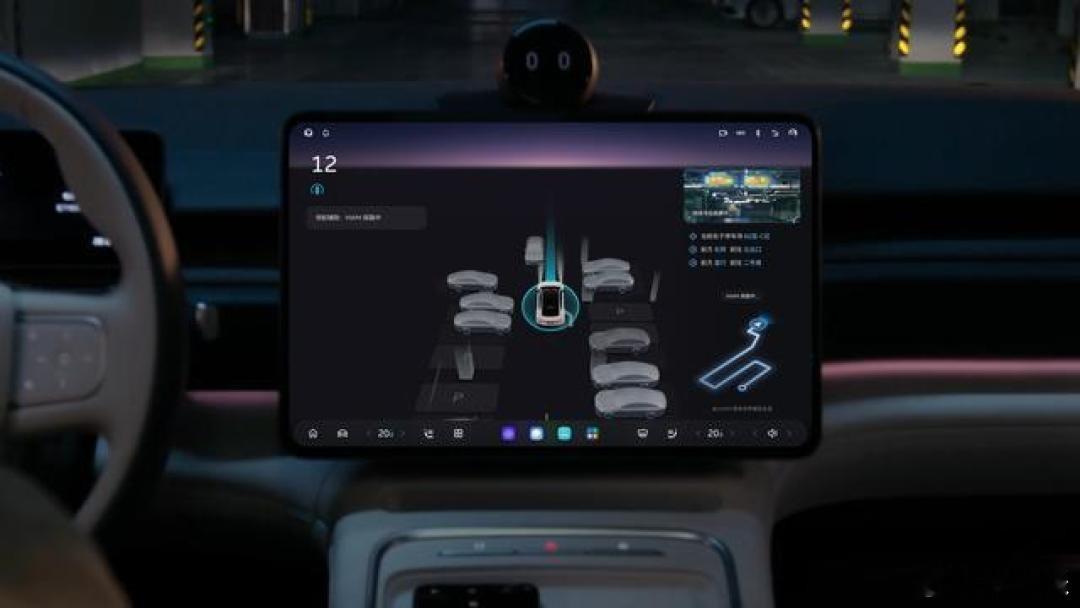

VLA即视觉语言动作模型,能让机器通过“看”和“听”理解世界并直接输出动作指令,核心是“端到端”处理,无需人工设定规则。与蔚来“世界模型”不同,VLA侧重即时反应,适合处理突发情况;而世界模型通过模拟“数字世界”来预测未来,优化长期策略。VLA对智能驾驶的推进作用主要体现在深度决策上,能通过大量数据训练,自己总结出应对各种场景的策略,甚至处理未见过的状况。V LA与世界模型各有优势,未来可能结合使用,让智能驾驶更安全、聪明,提升驾驶体验。