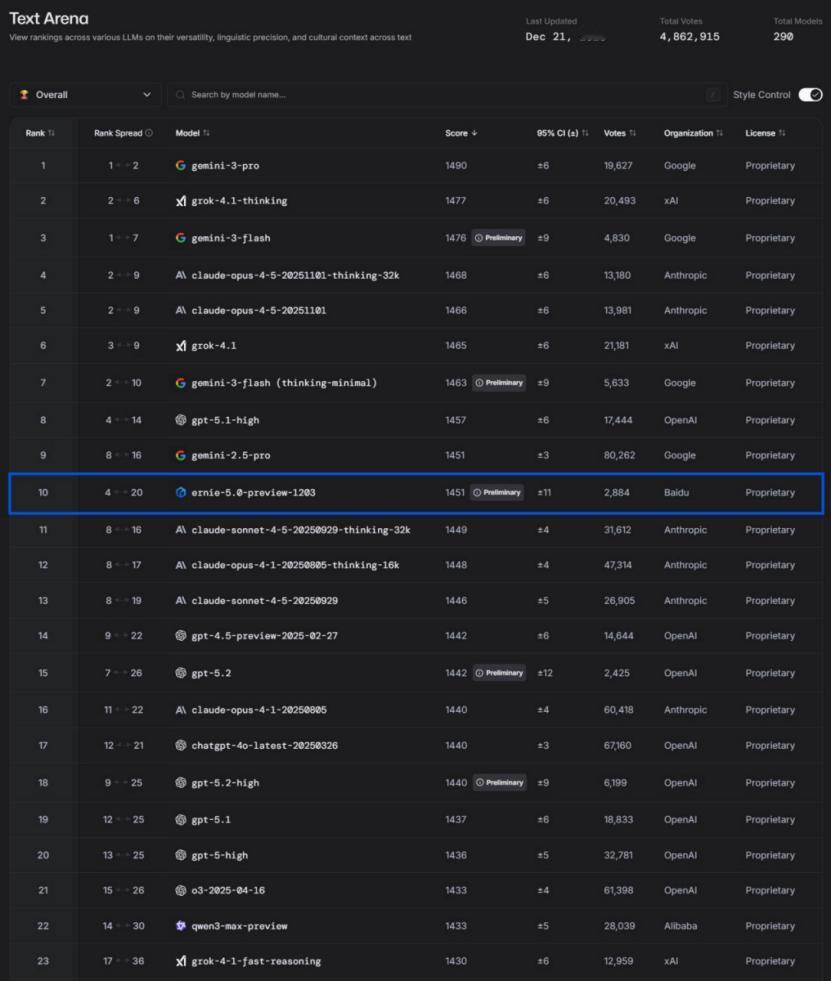
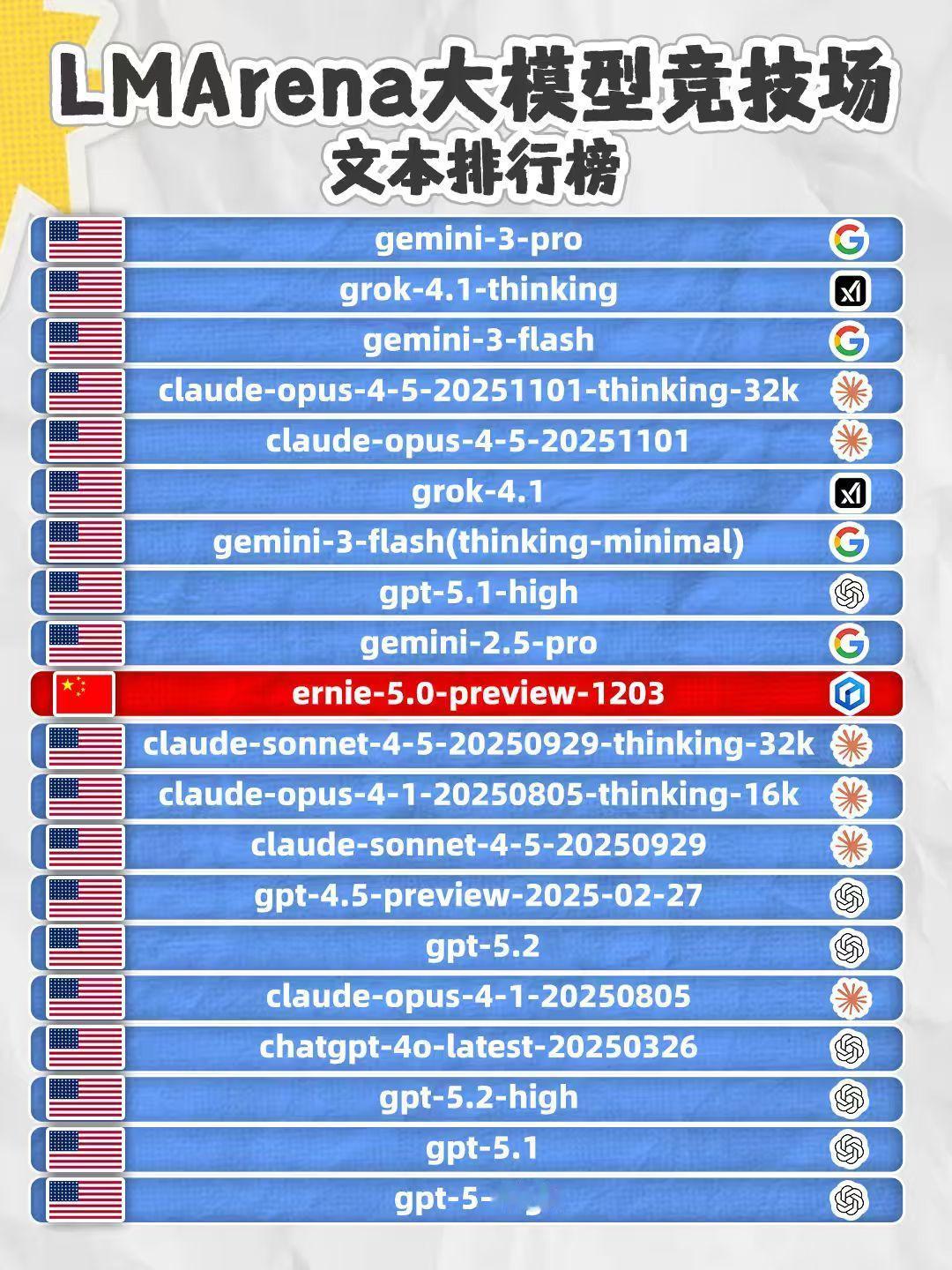
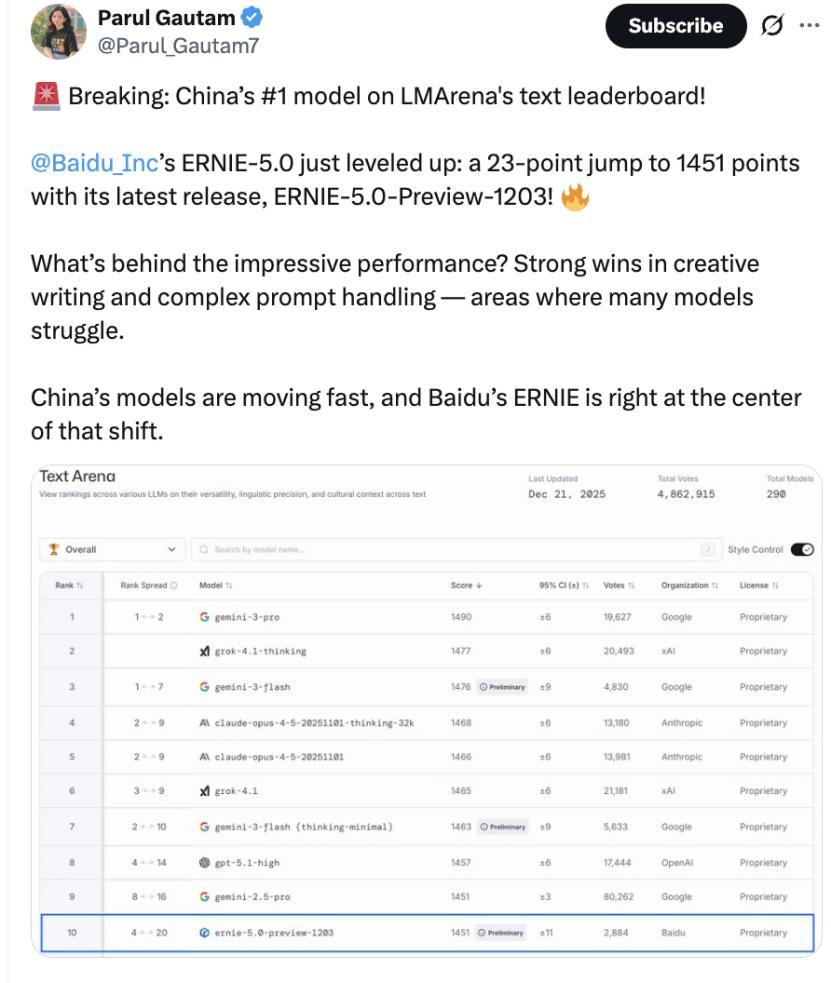
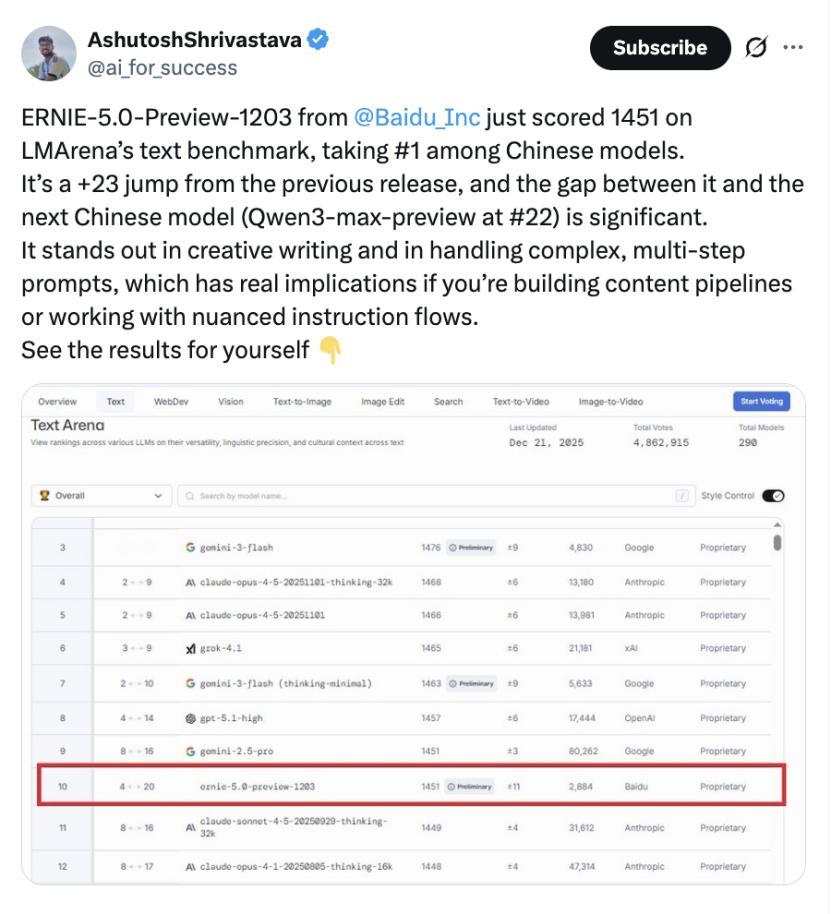
文心“刷榜”LMArena,是在为正式版铺路? 最近几个月,如果你持续关注AI大模型的竞技场LMArena,会发现一个有趣的现象:百度的文心大模型,出现得越来越频繁,排名也越来越靠前。 11月,文心模型在文本榜、视觉理解榜多次拿下国内第一;12月23日最新榜单中,其文本模型评分又较上一版本提升23分,继续稳居国内榜首。单看一次,或许是偶然;但连续在不同维度榜单上出现,且分数呈现稳步上扬的态势,这就很难再用“偶然发挥”来解释了。 这更像是一种有节奏的“技术预热”。结合近期业内传出的“文心大模型5.0正式版将于明年1月上线”的消息,这一系列动作背后的逻辑变得清晰起来:文心正在通过国际公认的公开评测,为其正式版的发布,进行一轮系统的“能力路演”与“预期管理”。 这种策略颇为聪明。在正式版亮相前,先将预览版(Preview)投入LMArena这样的“公开考场”,接受全球开发者最严格、最真实的盲测对比。这不仅能客观检验模型在创意写作、复杂指令理解等高阶能力上的真实水平,更能收集海量用户反馈,用于快速迭代优化。 更重要的是,它能提前在业界和用户心中锚定一个清晰的“能力坐标”。当正式版发布时,公众对其性能区间已有了基本认知和心理预期,避免了从零开始建立信任的漫长过程。近期分数的稳步提升,就像是不断抬高的“能力基线”,一步步强化市场对其进化速度和最终高度的信心。 纵观行业,这种“预览版先行公开验证,正式版随后重磅推出”的模式,正成为头部玩家发布重要版本前的常见打法。它既展示了技术自信,也构建了透明的沟通渠道。文心近期的频繁上榜,与其说是“刷存在感”,不如说是在执行一套严谨的上市前“压力测试”与“口碑铺垫”。 从“单点突破”到“全面稳定输出”,文心在LMArena上的轨迹,折射出国产大模型发展策略的成熟。它们不再满足于在单一评测中“惊艳一刻”,而是追求在持续、多维的公开竞技中,证明其综合实力的可靠性与进化潜力。 那么,当完成这一系列“预热动作”后,明年1月即将登场的文心大模型5.0正式版,究竟会交出怎样的答卷?或许,答案已经隐藏在这几个月稳步上扬的分数曲线里了。它可能不再需要从零开始证明自己“行不行”,而是要向世界展示,它究竟能“好到什么程度”,以及如何将评测优势,转化为真正赋能千行百业的生产力。这场始于榜单的期待,正等待着正式版带来一个更落地的回答。