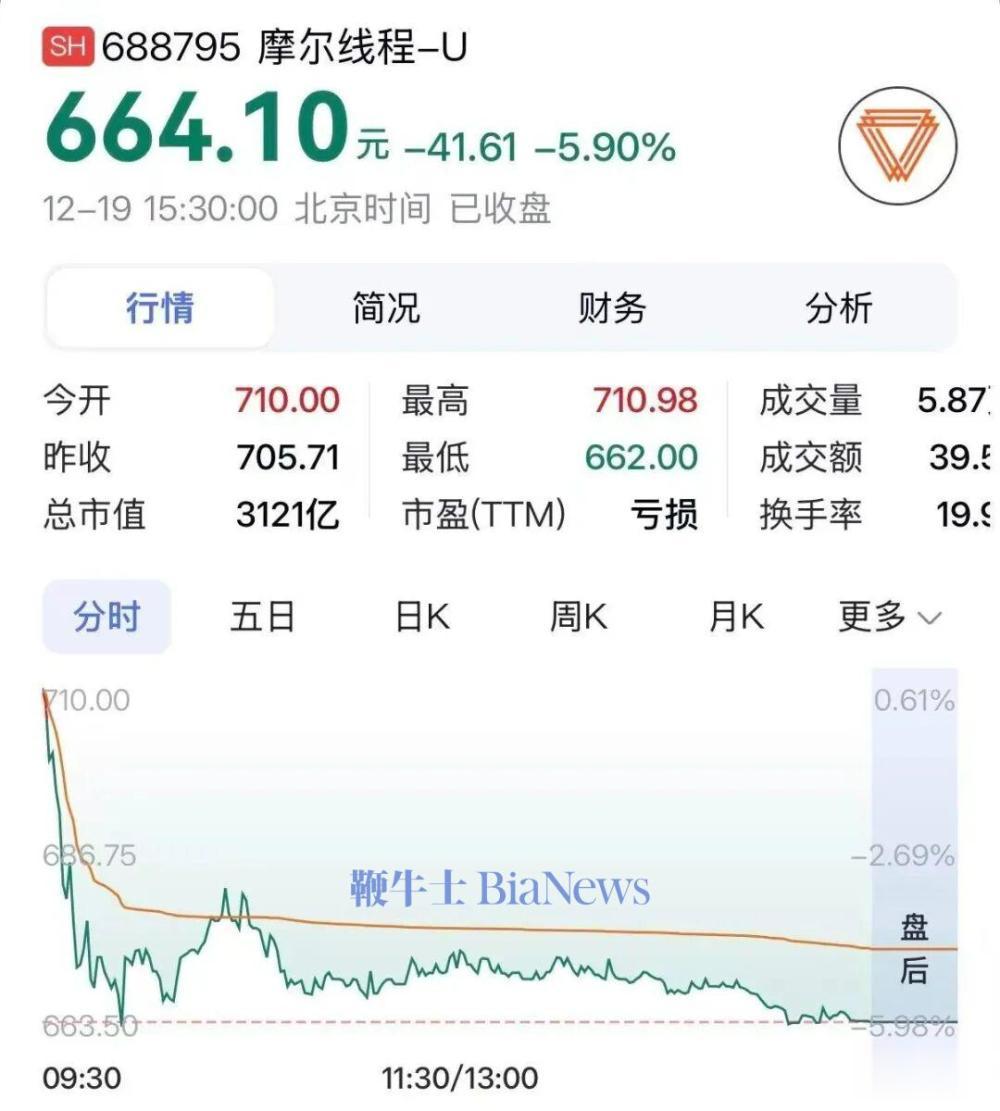
12月20日消息,摩尔线程今日举办了其上市后的首场开发者大会。12月5日,摩尔线程以114.28元/股的价格登陆科创板,截止今日收盘,股价为664.10元/股,涨幅累计481%,总市值约3121亿。
此时距离公司正式登陆科创板仅过去15天,面对外界对其3000亿市值中“情感估值”与“理性审视”的交织,创始人张建中带着第五代GPU架构“花港”走上台,试图通过自研MUSA生态的深度跨越,给出一个硬核的技术性交代。
本次大会发布的全新GPU架构“花港”,是摩尔线程自2020年成立以来迭代的第五代全功能GPU架构。在当前先进制程受限、代工工艺演进放缓的背景下,摩尔线程提出了“工艺不够,架构来补”的生存逻辑。

通过底层指令集的彻底重构和异步编程模型的引入,“花港”架构在相同工艺条件下实现了50%的算力密度提升和10倍的效能飞跃。这种不依赖极致制程而追求架构红利的思路,为国产GPU在突围战中提供了又一种现实路径,从底层解决大模型训练中计算资源闲置的顽疾。
基于“花港”架构,摩尔线程推出了面向AI智算的“华山”芯片。在核心技术对标中,“华山”在浮点算力、访存带宽等关键指标上处于英伟达上一代Hopper(H100/H200)与最新Blackwell架构之间。而在访存容量这一影响超大规模MoE模型推理性能的指标上,摩尔线程宣称优于上述两个架构。
配合自研的MTLink高速互联技术,摩尔线程正试图将算力集群从“万卡”推向“十万卡”规模。现场披露的推理实测显示,在DeepSeekR1671B全量模型上,其单卡Prefill吞吐超过4000tokens/s,证明了其在大规模参数模型商业化应用中的实战能力。

长期以来,英伟达CUDA能够统治市场,很大程度上依靠其PTX中间语言实现了跨代硬件的向下兼容,确保开发者多年前写的代码仍能运行在最新的Blackwell芯片上。摩尔线程此次在软件栈MUSA5.0中推出了中间语言MTX,官方称其能够解决国产GPU代际更电器频率高、适配成本难的痛点。尽管在成熟度上尚难与深耕近20年的CUDA平起平坐,但敢于在编译器底层挑战这种“向前兼容”的技术,意味着摩尔线程已不再满足于单纯的硬件替代,而是要在生态底层与英伟达展开实质性的“中门对狙”。
在云端重型算力之外,摩尔线程此次还将触角伸向了具身智能与端侧AI赛道。搭载自研“长江”SoC芯片的AIBOOK笔记本电脑,以及旨在缩小机器人虚拟训练与现实差异的MTLambda仿真平台,构成了其“端云一体”的业务闭环。

站在科创板的新起点上,摩尔线程正在经历从“追赶者”到“生态建设者”的角色转变。
面对全球算力竞赛的日益白热化,国产GPU的突围不仅仅在于单颗芯片的跑分高低,更在于大规模集群的稳定性以及开发者生态的粘性。
“花港”能否真正支撑起其3000亿的估值底盘,不仅取决于实验室里的测试数据,更取决于未来在数以十万计的智算节点中,国产GPU能够多大程度上替代国际主流产品,真正成为算力自主的坚实底座。(转载自AI普瑞斯)
评论列表