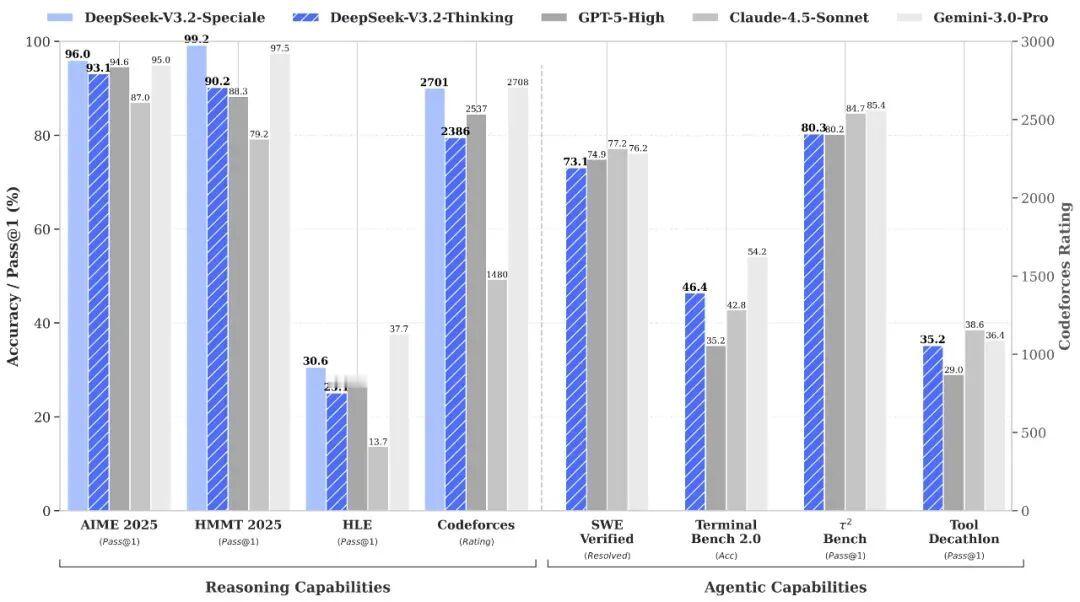
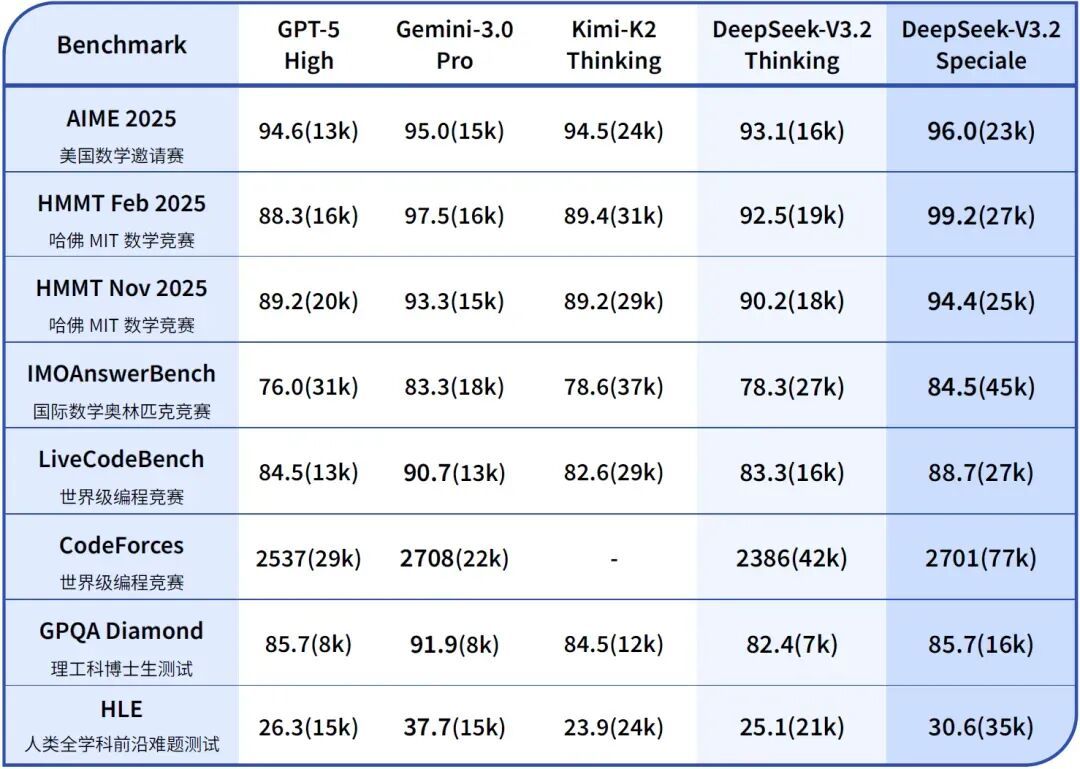
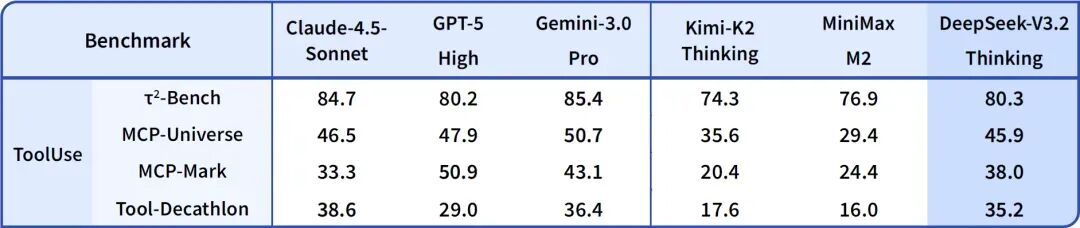
两个月前,DeepSeek只悄悄放出过一次 V3.2-Exp 实验版,理由是收集用户反馈。今天,完整版V3.2 终于来了。这次的方向很明确:推理能力 + Agent 执行能力。 标准版 V3.2 的定位是我们日常可用的推理引擎,数据结果显示推理结果更准确,输出更精简,响应更快,适合问答、代码协助、任务类 Agent 等真实使用场景。整体表现已经逼近顶级闭源模型。更高阶的 Speciale 则押注于 极限推理与数学证明能力,更像是一个长思考 & 数学怪兽的结合体。在竞赛级任务中表现亮眼,展示了开源模型在高难度推理领域的上限。尽管 V3.2 和 Speciale 展示了极强的推理实力,但 DeepSeek 团队还是坦诚了一些短板:知识覆盖面仍弱于闭源旗舰,复杂任务中的推理链偏长、偶尔还有话痨倾向。但整体来说,新版本还是用料满满,不知道大家用上了没?