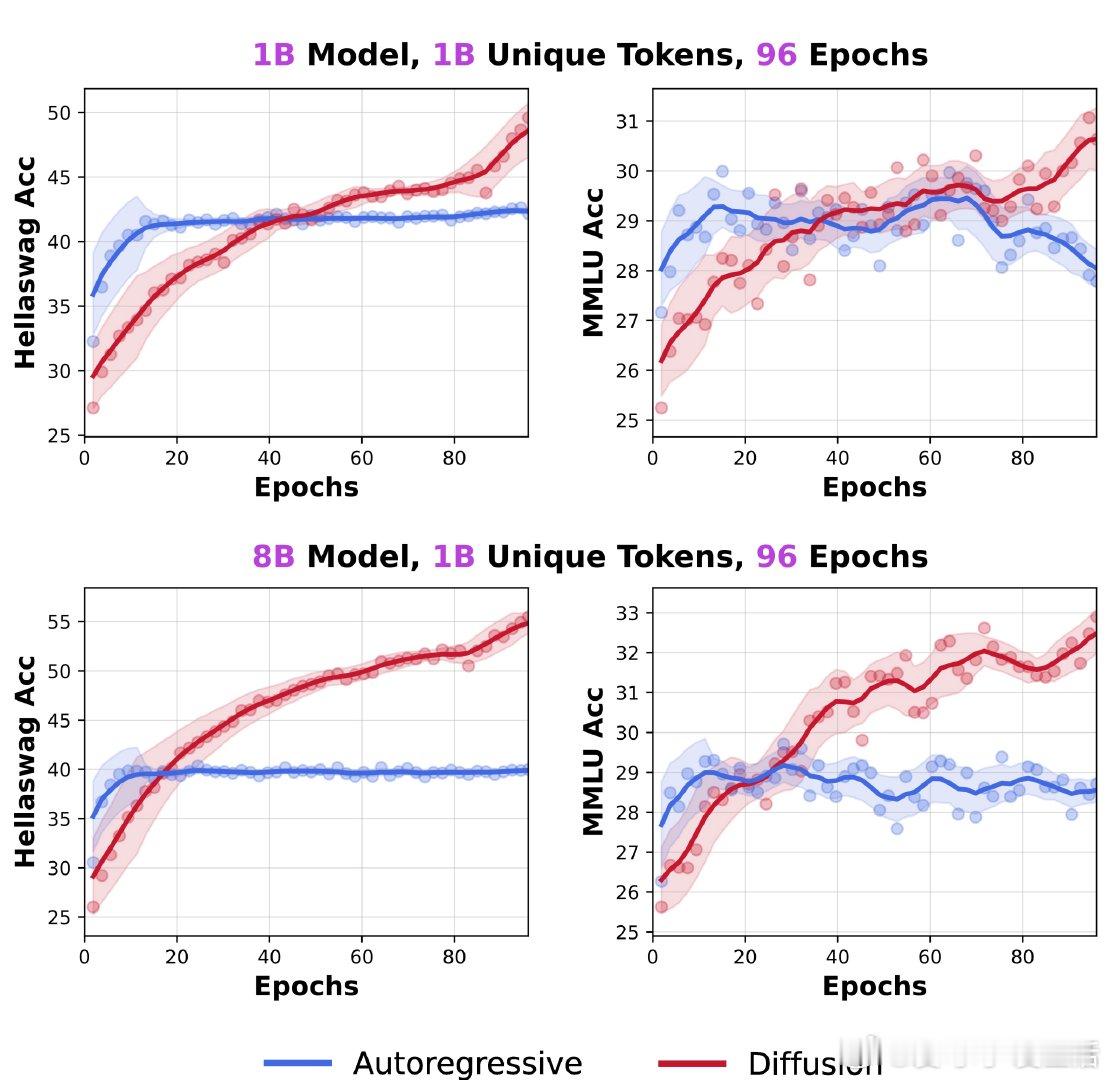
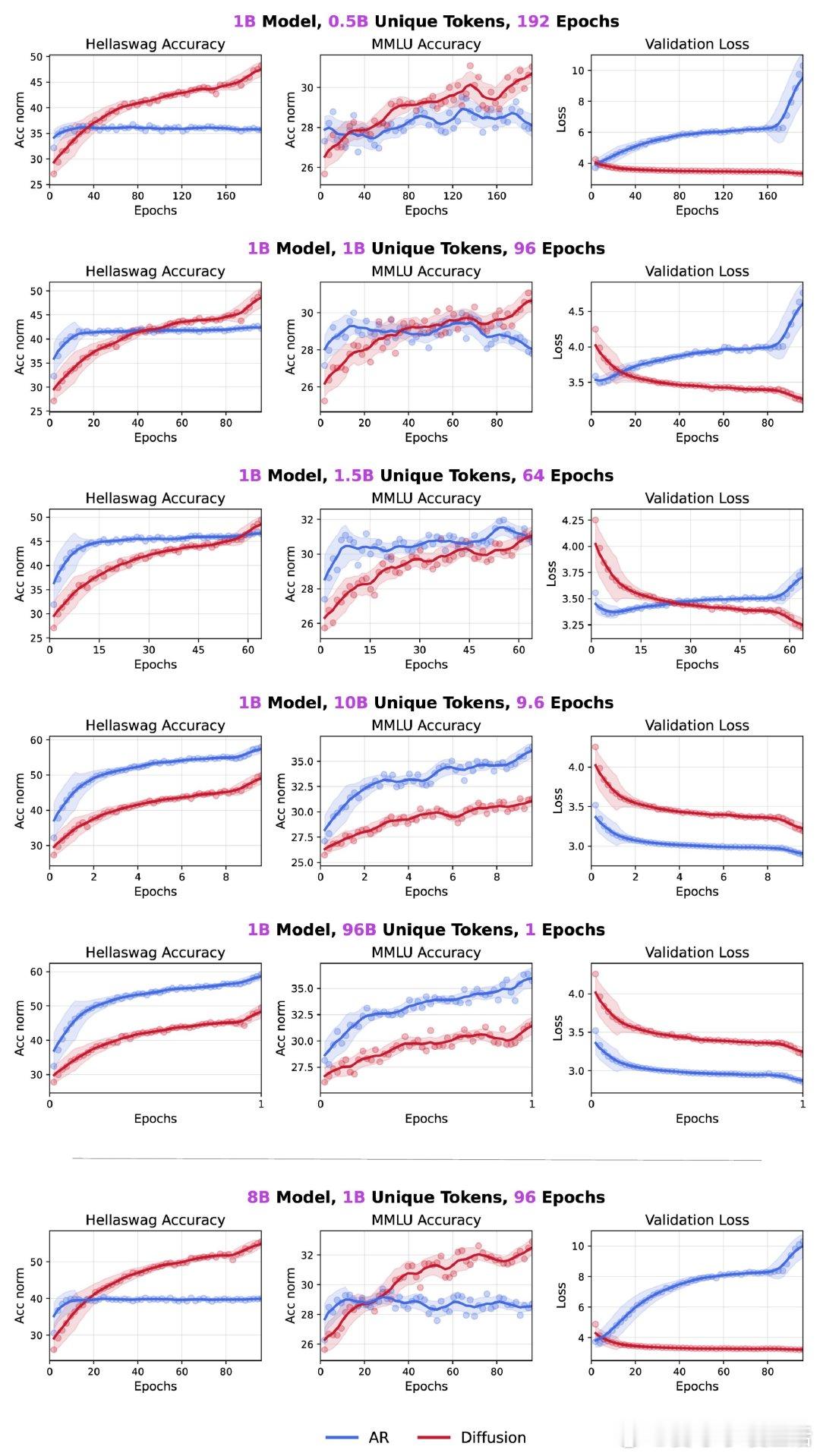
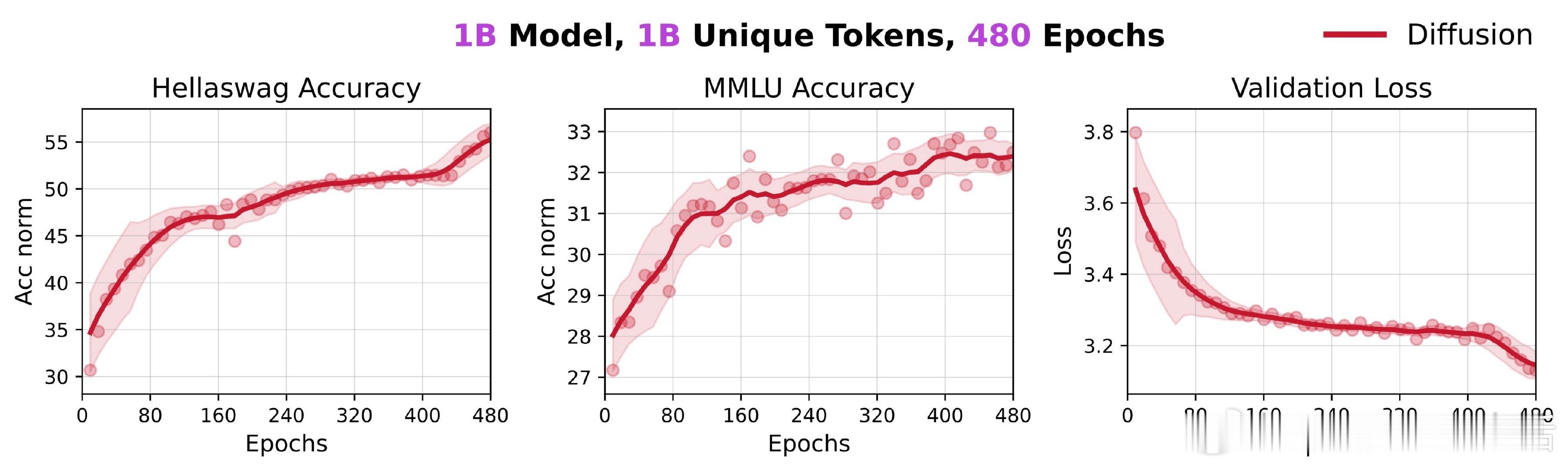
扩展训练480亿token,参数规模最高达8B,Diffusion Language Models(DLMs)在有限token预算下显著超越传统自回归(AR)模型,展现出超3倍的数据潜力:
• 1B参数的DLM仅用10亿token训练,即无任何技巧加持,已达56% HellaSwag准确率和33% MMLU,且重复训练并未出现性能饱和,更多重复带来持续收益。
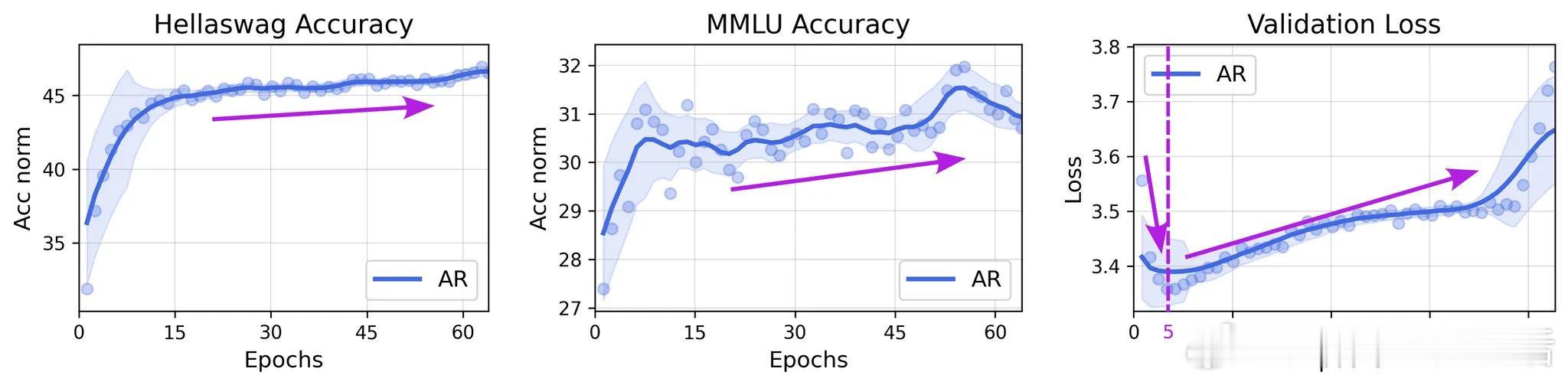
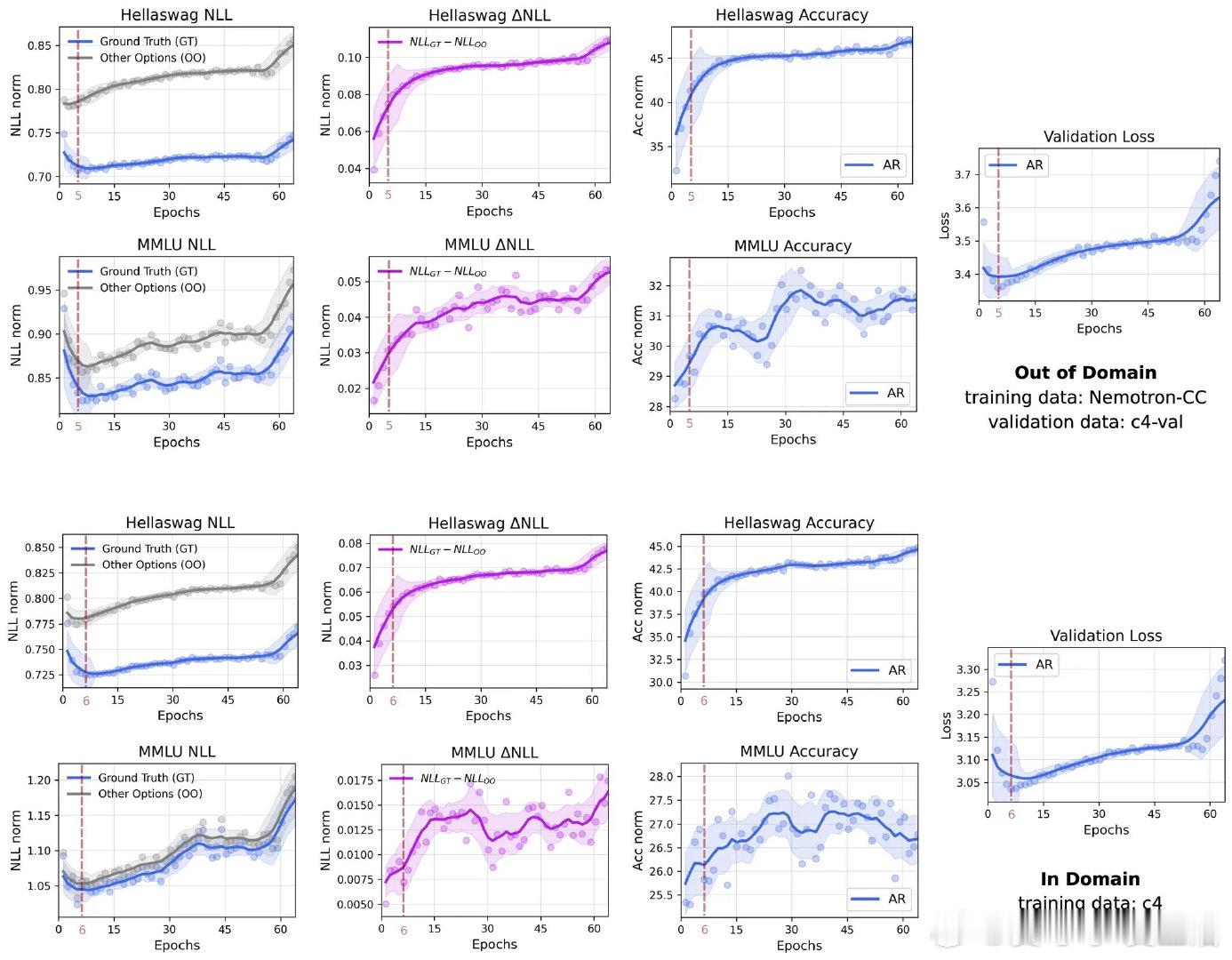
• DLMs对验证集“过拟合”时,负对数似然(NLL)虽升高,但模型对正确答案与备选项的区分能力(△NLL)持续增强,说明其判别能力依然提高,验证了“良性过拟合”。
• DLM能利用双向注意力机制,突破语言数据的单向因果限制,更充分挖掘信息价值,且“掩码扩散”目标要求对数据进行多样化随机遮蔽,促进模型学习更丰富的条件概率。
• 与AR模型追求计算效率最大化不同,DLMs以更高的FLOPs密度换取更强的数据学习能力,适应当前计算资源增长快于数据资源的现实,凸显其在数据受限环境下的独特优势。
• 针对同期研究“Diffusion Beats Autoregressive in Data-Constrained Settings”,团队指出其扩散损失设计、评测指标、AR对比设置及规模定律假设等存在严重方法论问题,可能导致误导性结论,呼吁社区提升开放评审标准。
更详细解读及代码开源见🔗 jin jieni.notion.site/Diffusion-Language-Models-are-Super-Data-Learners-239d8f03a866800ab196e49928c019ac
仓库地址🔗 github.com/JinjieNi/dlms-are-super-data-learners
DiffusionLanguageModels 机器学习 自然语言处理 大模型 数据效率 语言模型