大型语言模型(LLM)幻觉现象的全面分类与本质解析
• 理论必然性
- Manuel Cossio基于计算理论中的对角化技术,严谨证明了幻觉在任何可计算的LLM中是不可避免的本质属性。
- 该定理指出:对于任意一组可枚举的LLM,必存在某个真实函数使其所有模型状态均会产生幻觉,意味着幻觉非单纯可通过工程优化消除的“缺陷”,而是计算模型的根本限制。
- 实际意义上,这促使研究重心从“消除幻觉”转向“检测、管理与缓解”,并强调无外部辅助(如知识库、人工介入)时,LLM不能独立承担安全关键决策。
• 统一分类体系
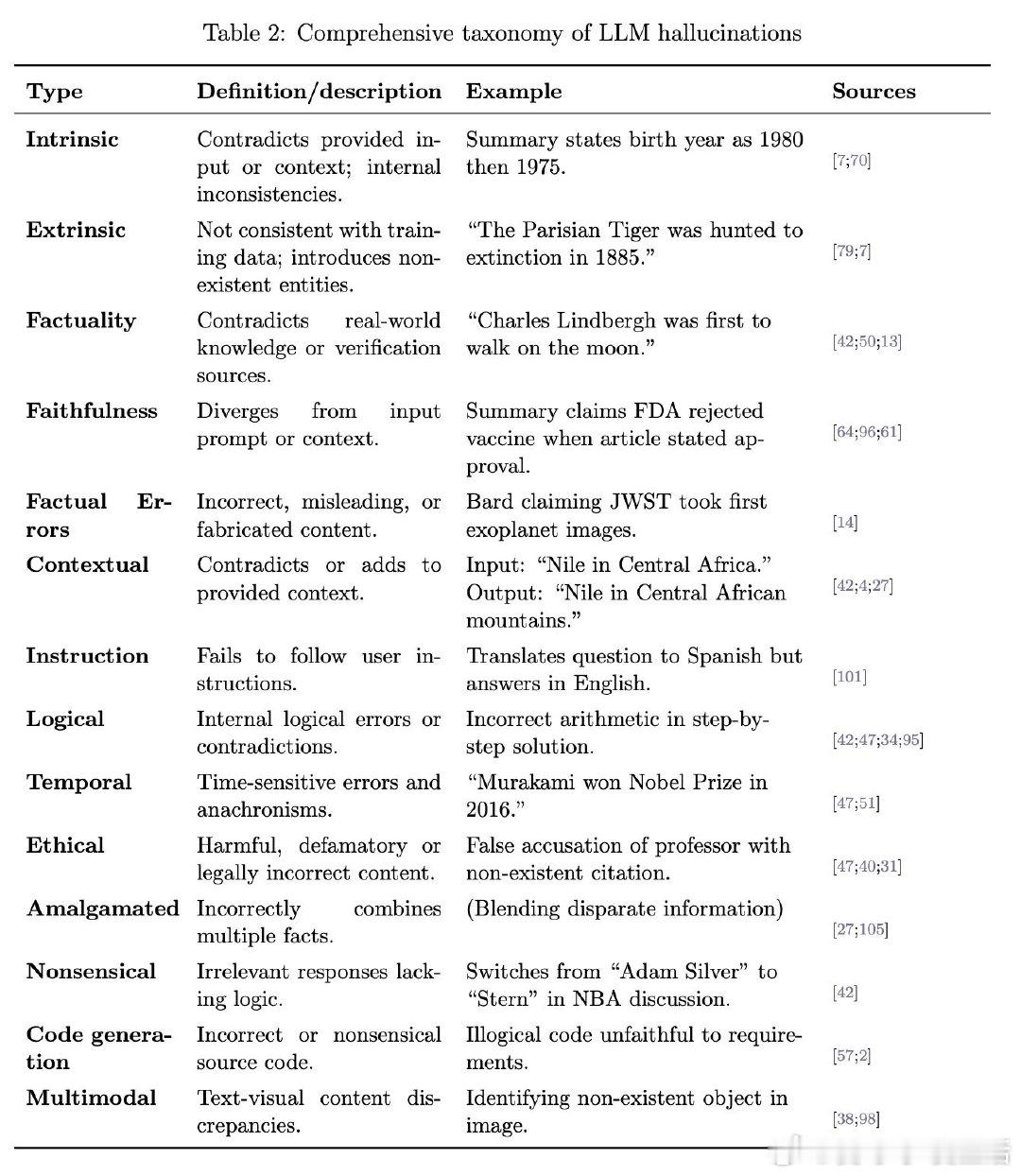
- 分类结构清晰划分为:
· 固有幻觉(Intrinsic)——与输入上下文直接矛盾,表现为内部不一致;
· 外在幻觉(Extrinsic)——生成内容与训练数据或现实事实不符,涉及虚构实体或错误信息。
- 并进一步细分为:
· 真实性幻觉(Factuality)——与现实知识或验证源抵触;
· 忠实性幻觉(Faithfulness)——内容偏离输入提示或上下文。
- 具体类型包括事实性错误、时间错位、逻辑错误、伦理违规、多模态不一致、代码生成错误等,涵盖多领域、多任务的幻觉表现,便于针对性识别和分类管理。
- 例如:总结中出生年份前后矛盾(固有幻觉);错误断言“巴黎虎1885年灭绝”(外在幻觉);翻译指令未遵守(指令幻觉);代码生成不符需求(代码幻觉)等。
• 成因多维度解析
- 数据层面:训练数据质量参差、偏见、信息过时,导致模型学习到不准确或误导性模式。
- 模型架构:自回归生成机制优先拟合概率最高的词序列而非事实准确性,训练时的暴露偏差和采样随机性加剧幻觉产生。
- 用户提示:不当或对抗性prompt可诱发幻觉,确认偏误促使用户忽视错误信息。
- 这说明幻觉是复杂系统行为的涌现特性,非单一环节可完全根治。
• 人因与认知偏差影响
- 自动化偏见:用户过度信赖AI输出,忽略潜在错误风险。
- 确认偏误:倾向接受符合已有观点的信息,加剧错误信息传播。
- 解释深度错觉:用户高估自身鉴别AI内容真伪的能力。
- 这些认知偏差使得即使明确警示用户,误用风险依然存在,故需设计具备不确定度显示、来源标注和理由提示的交互界面,辅助用户科学判断。
• 评估现状与挑战
- 现有基准如TruthfulQA、HalluLens及领域专用工具(如MedHallu)虽丰富,但缺乏统一标准,评测结果受任务依赖强,且对细微幻觉识别能力有限。
- 自动检测指标多停留在表层相似度,难以解释为何输出被判定为幻觉,限制了技术诊断和优化的深入。
- 未来评估需结合语义理解、逻辑推理与知识验证,构建多维度、可解释的综合评测体系。
• 缓解策略与应用场景适配
- 混合防控体系:结合架构增强(如Toolformer的工具调用、基于检索的增强生成RAG)、系统护栏(规则约束、符号计算)及人工监督。
- 场景区分:
· 高风险领域(医疗、法律等)强调严格事实准确性与人工审核,优先保证安全性;
· 创意生成领域可容忍一定开放性,同时需明确不确定性提示以免误导用户。
- 适应性策略提升了系统应对多样化需求的能力,兼顾安全与灵活性。
• 现实监控工具与后续发展
- 介绍了Artificial Analysis、Vectara幻觉排行榜、LM Arena等监测平台,为实际部署的LLM提供动态幻觉率监控和模型性能追踪。
- 这些工具助力开发者及时发现问题,优化模型表现,保障应用可靠性。
总结:
Cossio的工作从理论到实践,系统重塑了我们对LLM幻觉的理解——它不再是单纯的“错误”或“缺陷”,而是计算模型的根本属性,必须通过科学的分类、因果分析及多元策略加以管理。该研究为LLM安全应用提供了坚实的理论支撑与操作指南,推动AI技术向负责任、可控的方向发展。
详见👉 x.com/IntuitMachine/status/1953514197893165138
大型语言模型 AI幻觉 模型安全 认知偏差 AI评估 混合智能 技术伦理