2025年被称为人工智能元年,在今年1月于拉斯维加斯举行的CES(国际消费电子展)上,“物理人工智能”引起了广泛关注。这项技术与以往的人工智能截然不同。我们之前所说的“人工智能”,例如ChatGPT和Gemini,大多是在数字空间中处理文本、图像和其他数据的“人工智能”。虽然这本身已经令人印象深刻,但最近备受瞩目的“物理人工智能”则展现出另一个令人惊叹的层面。

为了进一步加深理解,让我们来看看时间的概念。我们所处的真实世界是一个四维世界,其中存在着“时间”的概念。然而,运行在计算机中的生成式人工智能可以轻松编辑文本和生成图像,甚至可以重做它们。但是,机器人和汽车都在运动,因此它们的运动无法重来。当你转动一辆以60公里/小时速度行驶的汽车的电动方向盘时,你无法“收回控制权”,如果你刹车太晚,也无法重新来过。物理人工智能通过学习海量数据来模拟经验丰富的驾驶员的行为。

半导体巨头英伟达在2026年国际消费电子展(CES)上发布了一个用于物理人工智能的集成平台。该平台突破了半导体的局限,将传感器和人工智能集成在一起,从而降低成本并加快自动驾驶技术的开发。传统的自动驾驶汽车和机器人由软件控制,人类在其中编写诸如“如果……则执行此操作”之类的规则,但物理人工智能则不同。它可以即时分析来自摄像头和其他传感器的大量数据,自主学习并判断当前情况。

正是这种“从经验中学习”的过程,使得车辆即使在不可预测的环境中,例如陌生的地点或不断变化的建筑工地,也能安全控制。换句话说,“物理人工智能”指的是超越简单感知和生成能力的人工智能,它不仅能够理解和推理周围环境,还能在现实世界中安全、恰当地行事。英伟达首席执行官黄仁勋在2026年国际消费电子展(CES)上强调了这一点。
在社会中应用物理人工智能的最大障碍在于缺乏透明度,即“人工智能为何选择以某种方式行动”。VLA(视觉-语言-动作)模型克服了这一挑战。英伟达发布了名为“Alpamayo”的开放平台,这是一个用于构建集成式自动驾驶模型的平台。“Alpamayo”超越了传统的自动驾驶模式——“人工智能仅观察并做出反应”,旨在创建一个能够逻辑地解释“为何执行特定操作”的集成式人工智能。这是一个能够理解并推断物理世界情境的先进模型,有望成为自动驾驶技术发展的基础。
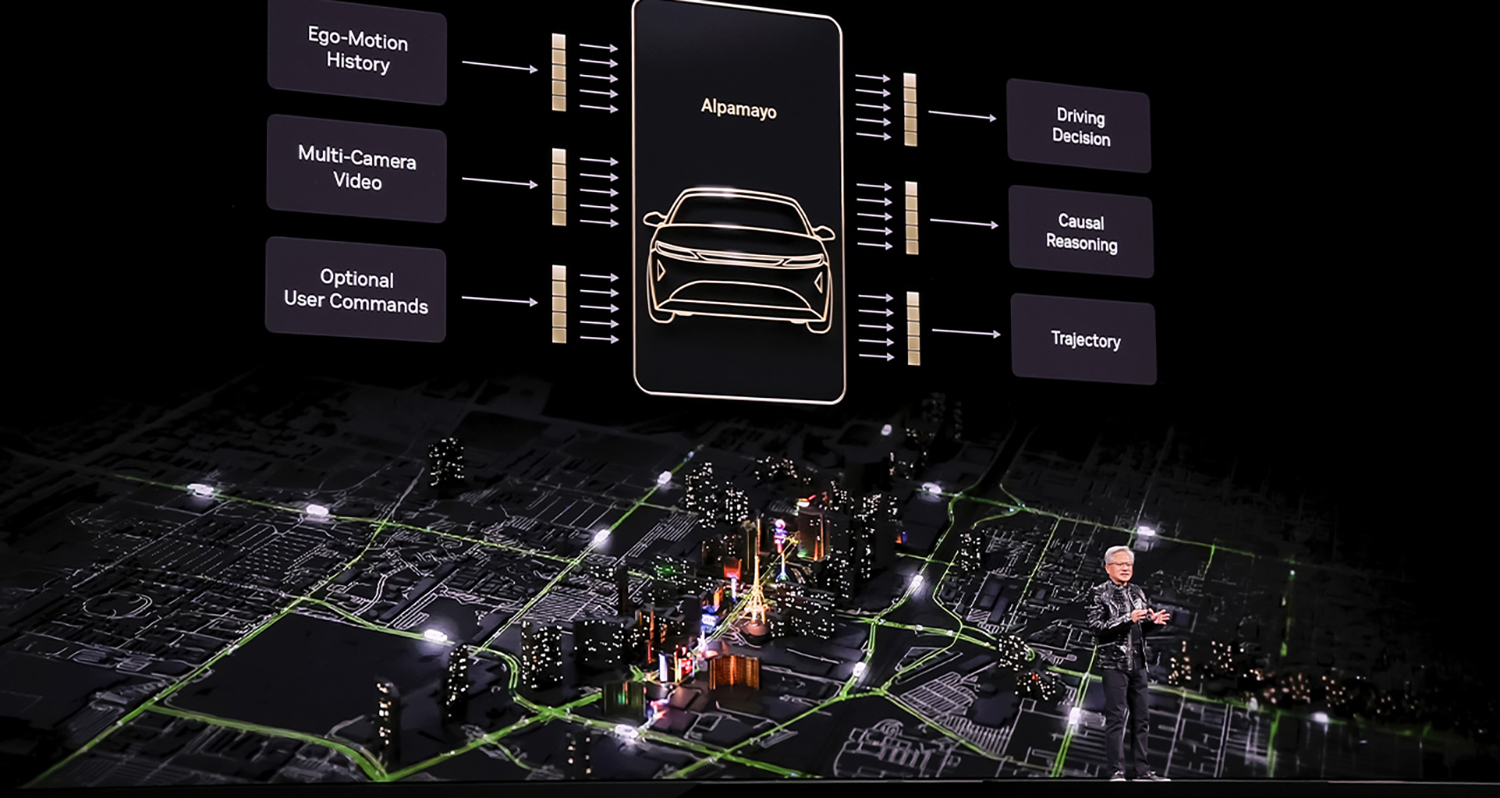
究竟是如何运作的?该模型的关键在于,它不仅发出运动指令,还能将人工智能的行为用语言表达出来并记录下来。例如,它可能识别出“一个孩子从右侧跑出来”(视觉),并决定紧急制动以避免碰撞(动作)。然后,它会用语言表达这样做的原因,例如“我踩了刹车以避免碰撞”(语言)。即使出现此类问题,确保可追溯性也是将生命托付给人工智能所带来的“安全感”的基础。
尤其是在移动领域,汽车就像“在物理世界中移动的巨型机器人”,能够集成各种传感器、执行器(移动物体)和能量,因此物理人工智能被定位为汽车人工智能的核心。