当前,AI浪潮席卷全球,大模型技术竞赛已进入白热化阶段。从千亿到万亿参数规模跃升,从单点突破走向全域应用,每一次能力跃迁的背后,皆是对底层算力需求呈指数级增长的直观体现。
也正因如此,主流大模型玩家纷纷布局超大规模算力集群,如马斯克xAI项目已建成超10万卡的超级计算集群、OpenAI单集群GPU数量50000+、谷歌单集群GPU数量25000+、Meta单集群GPU数量24500+、字节跳动单集群GPU数量12888......万卡集群已成为参与这场巅峰竞技的“标配”入场券。

然而,在全球算力版图中,中国AI产业正面临严峻挑战:国际高端AI芯片如H200等产能受限,进入国内市场还须经过审核与追踪程序;美国《远程访问安全法案》进一步限制算力远程调用。多重因素叠加下,国内头部互联网厂商与大模型企业的算力焦虑持续加剧。
面对外部封锁,政策端正加大支持力度。近期,各地“十五五”规划建议相继出炉,“加快高端算力芯片的创新研发与技术攻关”成为发展重点。同时,工业和信息化部副部长张云明近期公开强调,要加快突破训练芯片、异构算力等关键技术。政策指向与产业需求高度共振,业界普遍形成共识:2026-2027年,将成为国产GPU实现规模化替代、挺进核心训练场景的关键窗口期。
而万卡集群不仅是检验国产算力体系成熟度的试金石,更是中国AI产业实现深度自主的关键一役。
01、万卡集群,并非易事《2025中国算力发展研究报告之AI计算开放架构》指出,AI产业的发展拐点,正从“堆算力”转向“组织算力”。
而构建并高效运营万卡集群,绝非简单堆砌硬件,它是对芯片性能、软件栈、工程化能力与生态体系的全面考验。
很多外行人会认为,建设万卡集群的核心障碍是“显卡贵、买不到”,但事实远非如此。即便手握上万张高性能显卡,要将其整合成一台协同运转的“超级计算机”,依然要面对一系列足以让多数团队望而却步的系统性挑战。
建设之难,首先在“协同”二字。大模型训练要求所有算力单元同步并行计算,海量数据交互实时发生,哪怕0.1微秒的网络延迟都可能演变成系统级灾难,进而陷入“卡越多效率越低”的悖论。
协同难题的背后,是能耗、散热与存储构成的基础保障困境。万卡集群需7×24小时不间断运行,十万卡级集群仅关键IT设备的电力需求就达150MW,远超单个数据中心的承载能力,电压波动、分布式供电分配等问题都需逐一破解。

此外,建设万卡集群还需重点应对集群规模放大后的常态化故障。摩尔线程副总裁王华早就指出,“节点故障、性能抖动、通信与存储瓶颈,在集群规模被放大之后都会成为常态,很多在千卡规模下可以容忍的风险,在万卡场景中都会被大幅放大”。
最后不得不提的是,国内万卡集群建设还面临一层异构生态的羁绊。由于国内无法完全采用英伟达单一方案,所以需要打破不同芯片的协同壁垒,实现“不同芯片,同一平台”的统一调度与优化,这也要求厂商进行软硬件解耦的技术创新,并具备成熟的生态支撑能力。
综合来看,万卡集群建设的难度堪比攀登无径之峰,每一步都需跨越技术与工程的多重天堑。
但正如摩尔线程创始人兼CEO张建中在2024年断言的那样,AI主战场,万卡是最低标配。在AI向AGI演进的浪潮中,从大模型研发到应用,以及训练到推理,算力正被疯狂消耗,作为支撑千亿、万亿参数大模型训练的核心底座,万卡集群其建设与应用已成为一条必然坚持且难而正确的道路。
02、国产力量,啃下硬骨头挑战虽巨,国产GPU厂商已在务实前行。
作为国产GPU领军企业,摩尔线程率先跨越了从集群“可运行”到“可持续稳定运行”的深水区,完成了在万卡智算集群建设上的深水区自证。
早在2024年,摩尔线程便已布局万卡智算集群,对其“夸娥(KUAE)智算集群”解决方案进行重大升级,将规模从千卡级别大幅扩展至万卡级。
2025年12月底,摩尔线程正式发布夸娥(KUAE 2.0)万卡智算集群,纯算力规模达10 Exa-Flops(百亿亿次),实现在万卡规模下高效稳定的AI训练与推理。该集群基于“平湖”架构的MTT S5000搭建,是以全功能GPU为底座,软硬一体化、完整的系统级算力解决方案,具备全精度、全功能通用计算能力。在Dense大模型训练中,其算力利用率(MFU)达60%,MOE大模型上达40%,有效训练时间占比超90%。根据工信部数据统计,目前我国已建成的万卡智算集群仅42个,夸娥(KUAE 2.0)万卡智算集群的成功落地,则充分证明证明了国产GPU及全栈技术在万卡规模下的强大能力,国产算力基础设施建设正在迈入新发展阶段。
万卡集群的系统能力离不开核心硬件的突破。MTT S5000作为面向生成式AI时代的全功能GPU,专为大模型训练与推理及高性能计算设计。凭借先进的"平湖”架构,MTT S5000产品提供从FP8到FPG4的全精度算力支持,属于国内率先原生支持FP8精度的训练GPU,并配置了硬件级FP8 Tensor Core加速单元,在推理性能上树立了国产单卡新标杆。
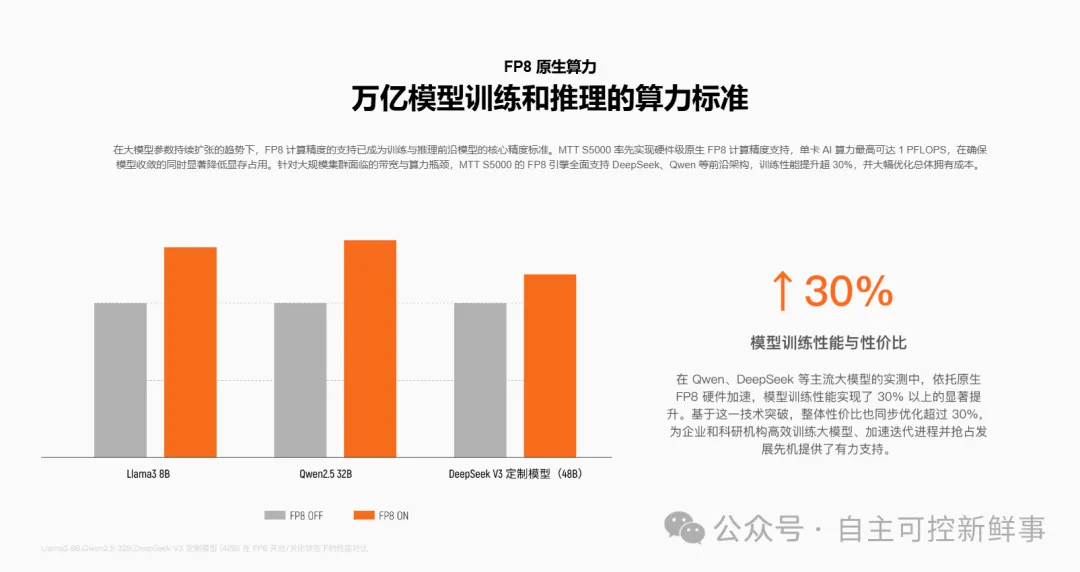
据官方披露,在与硅基流动的合作中,基于FP8低精度推理技术对DeepSeek V3 671B 满血版大模型深度适配后,MTT S5000单卡单卡Prefill(预填充)吞吐超4000 tokens/s,Decode(解码)吞吐超1000 tokens/s。在多模态领域,MTT S5000针对文生视频模型进行深度优化,推理速度可达到H100的70-80%水平,且在WAN 2.1-T2V-14B 视频生成任务中,单机性能达到国际旗舰产品的64%,在保证画质无损的同时实现了高性价比输出。

目前,MTT S5000已在摩尔线程官网上线,进一步公开技术细节。
图片来源于:摩尔线程官网
MTT S5000官网介绍:https://www.mthreads.com/product/S5000
工程化落地里,加速大模型只是第一步。长期以来,国内自主算力集群普遍存在“强推理、弱训练”的不平衡现象,高端训练任务仍依赖国外GPU。近期,工信部等八部门联合发布《“人工智能+制造”专项行动实施意见》,首次明确要求“加快突破训练芯片”。这一精准指向,也反映了国内AI算力产业一个关键的现状:虽然已有众多自主算力集群能有效支撑推理任务,而真正能用于高强度“训练”的集群极为稀少。
好在,摩尔线程在训练侧同样取得突破性成果:其联合智源研究院,基于MTT S5000千卡智算集群完成具身大脑模型RoboBrain 2.5的全流程训练。这是首次完全使用国产GPU集群为机器人训练“大脑”,使其具备感知、思考与决策能力。

技术数据显示,摩尔线程千卡集群训练损失值(Loss)与国际主流GPU曲线高度重合,误差小于0.62%。更重要的是,从64卡扩展至1024卡时,系统实现了90%以上的线性扩展效率,印证了其在大规模并行计算与通信调度方面的成熟度。也就是说在训练芯片这一尖端领域,摩尔线程已成为国内极少数率先实现万卡集群高效训练、并拥有完整交付能力的企业,其多项关键指标已达到国际主流先进水平,在AI算力最核心领域实现了实质性突破。
整体来看,摩尔线程MTT S5000在推理与训练两侧的实绩,标志着国产全功能GPU已跨越“训推一体”的技术门槛,这不仅是单一产品的突破,更是从芯片、架构、集群到软件栈的全链条能力提升。
毫无疑问,国产算力正从“可用”走向“好用”,逐步实现高效、稳定、可扩展的系统级赋能。
03、破局,为什么是摩尔线程?行稳致远,是摩尔线程的答案。
诚然,万卡集群赛道强手如林,但敢于入局者,必有其实力与底气。
摩尔线程之所以能跻身其中,正是源于其前瞻的视野与扎实的布局。自2020年创立之初,团队便确立了设定了建集群的大方向和策略,提前组建云计算专业团队、规划技术路线。2023年大模型浪潮席卷而来,更坚定了其深耕大规模智算集群的决心。选择以万卡集群为长远目标。这一选择不仅体现了摩尔线程对GPU产业趋势的深刻洞察,更彰显了一种强调长期主义的发展哲学。
有战略,更需有落地。摩尔线程的核心竞争力,建立在自主创新的MUSA(元计算统一系统架构)之上。这是国内首个在单芯片上同时支持AI计算、图形渲染、科学计算、物理仿真及超高清编解码的全功能GPU架构,覆盖从芯片设计、指令集、编程模型到软件栈与驱动框架的全栈技术体系。与传统GPU相比,全功能GPU在计算效率、生态完整性与场景适应力上表现更为突出,更能满足未来多样化、融合化的高性能计算需求。

图片来源于:摩尔线程官网
尤为值得一提的是,该架构支持软硬一体化的“一键跨平台部署”,开发者仅需极少的代码改动即可实现迁移,大幅降低开发与适配成本。与此同时,摩尔线程积极推动产业协同,与国产CPU、操作系统厂商深度合作,发起成立“PES完美体验系统联盟”。在创始人张建中看来,这种深度的国产化兼容与优化,是国际GPU厂商难以复制的优势。
由此可见,摩尔线程的破局之路,并非偶然。它既来自于对技术路线的清醒判断与提前卡位,也依托于全栈自研的架构能力与开放合作的生态布局。在算力成为核心生产力的今天,这样一种兼具前瞻性、先进性及协同性的发展路径,或许正是其在激烈竞争中稳步向前的重要依凭。
04、结语摩尔线程S5000的万卡集群,证明了国产GPU已经跨过了从0到1的生存阶段,正在向从1到10的生态繁荣阶段迈进。展望未来,摩尔线程已宣布下一代全功能GPU架构“花港”及AI计算芯片“华山”。新架构将支持FP4到FP64全精度,算力密度提升50%,效能提升10倍,并支持10万卡规模以上的超大规模集群能力。
在AI与物理世界深度融合的浪潮下,国产算力正迎来最好的时代。对于正在寻求算力安全与供应链稳定的中国算力基础设施而言,以摩尔线程S5000为代表的国产万卡集群方案,不再是备选,而是在实践中检验后的重要选项。