今天打开科技新闻的朋友,恐怕都会看到那张图。
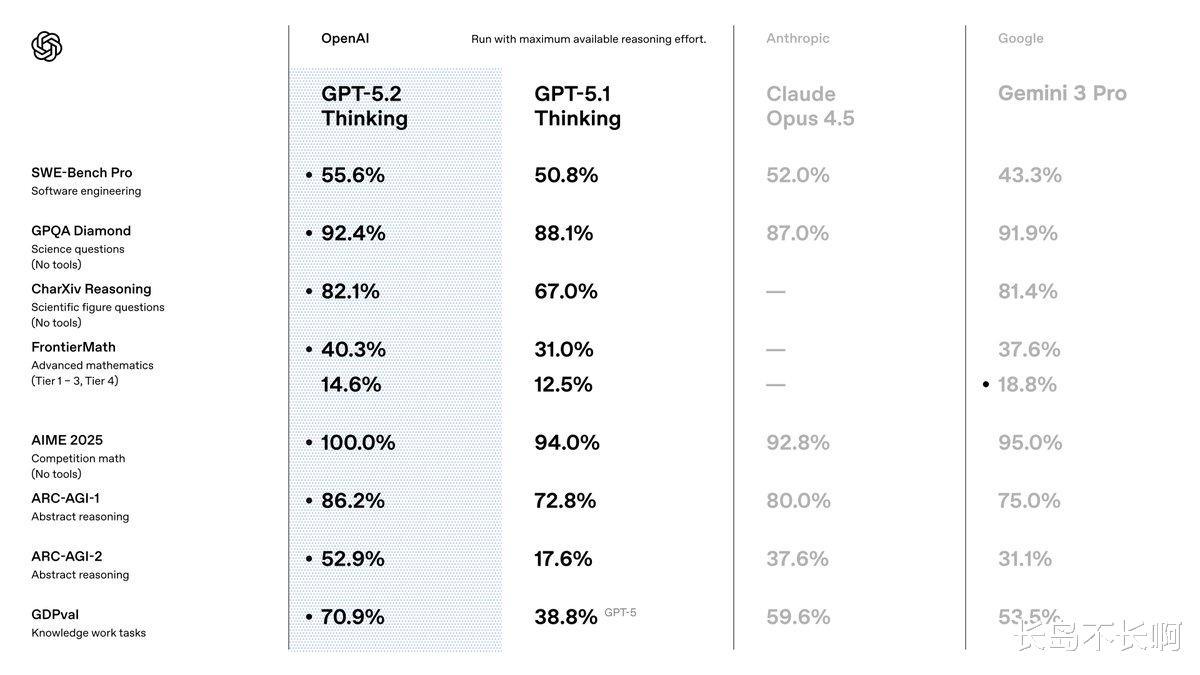
最让我感到头皮发麻的,是这一行数据: AIME 2025 (Competition math): 100.0%
你没看错,100%。 美国数学邀请赛(AIME),这是全球顶尖高中生角逐的战场。以前的模型(包括 GPT-5.1)能做到 94% 已经很逆天了,但 100% 意味着什么? 意味着 GPT-5.2 在数学逻辑上,已经不存在“幻觉”和“失误”了。它彻底攻克了 LLM(大语言模型)最不擅长的逻辑严密性领域。
作为对比,隔壁的 Claude Opus 4.5 是 92.8%,Google 的 Gemini 3 Pro 是 95.0%。 看着只有几个百分点的差距,但在数学领域,从 95 分到 100 分的难度,比从 0 到 90 分还要大。
细心的朋友可能发现了,这次的模型代号变了。 它不叫 GPT-5.2,它叫 GPT-5.2 Thinking。
这不仅仅是一个名字的后缀。这标志着 OpenAI 彻底将 System 2(慢思考/推理能力) 融合进了主模型。它不再是像鹦鹉学舌一样预测下一个字,而是在输出答案之前,已经在内部构建了完整的逻辑链条。
数据证明了一切:
GPQA Diamond (博士级科学问答): GPT-5.2 拿下了 92.4% 的高分,吊打 GPT-5.1 的 88.1% 和 Claude Opus 4.5 的 87.0%。
FrontierMath (高等数学): 在这个堪称“AI 坟场”的测试中,GPT-5.2 飙升到了 40.3%,而 Google 的 Gemini 3 Pro 只有 37.6%。
GPT-5.2 已经具备了“独立科研”的雏形。它不再只是帮你写邮件的助手,它是能帮你推导公式、验证猜想的“硅基科学家”。

对于靠写代码为生的人来说,另一个数据更加扎心。
在 SWE-Bench Pro (软件工程) 测试中,GPT-5.2 达到了 55.6% 的解决率。 相比之下,Google 的 Gemini 3 Pro 只有 43.3%。
超过 50% 的 SWE-Bench 解决率,意味着对于一半以上的 GitHub 真实工程问题(Issue),你只需要把需求扔给 GPT-5.2,它就能自己改代码、跑测试、提 PR,而且一次通过。
以前我们说 AI 是 Copilot(副驾驶),现在看来,它正准备把驾驶员踹下去,自己握方向盘了。
04. 通往 AGI 的最后一块拼图:抽象推理如果说知识储备是 AI 的强项,那么“抽象推理”(举一反三的能力)一直是 AI 的短板。 但在 ARC-AGI-1 测试中,GPT-5.2 轰出了 86.2% 的恐怖高分。
这个测试专门用来评估 AI 处理“未见过的新任务”的能力。 86.2% 的得分,意味着它面对完全陌生的问题时,具备了极强的自适应学习能力。这正是通往 AGI(通用人工智能)最关键的一步。
05. 结语:诸神黄昏,OpenAI 独舞看着这张图表,我仿佛听到了硅谷其他大厂心碎的声音。
Claude Opus 4.5 刚发布时,大家以为它追上了 GPT-5;Gemini 3 Pro 发布时,Google 以为自己扳回一城。 但 OpenAI 用 GPT-5.2 告诉所有人:你们追上的,只是我的背影;而我,已经站在了下一个维度的入口。
【🗣️ 互动话题】GPT-5.2 的数学拿了满分,你慌吗?
学霸的绝望: 如果 AI 做奥数题都满分了,我们还要让孩子死磕数学吗?教育的意义在哪?
程序员的自救: SWE-Bench 突破 55%,你觉得初级程序员还能活几年?
AGI 倒计时: 你觉得这算不算真正的 AGI?