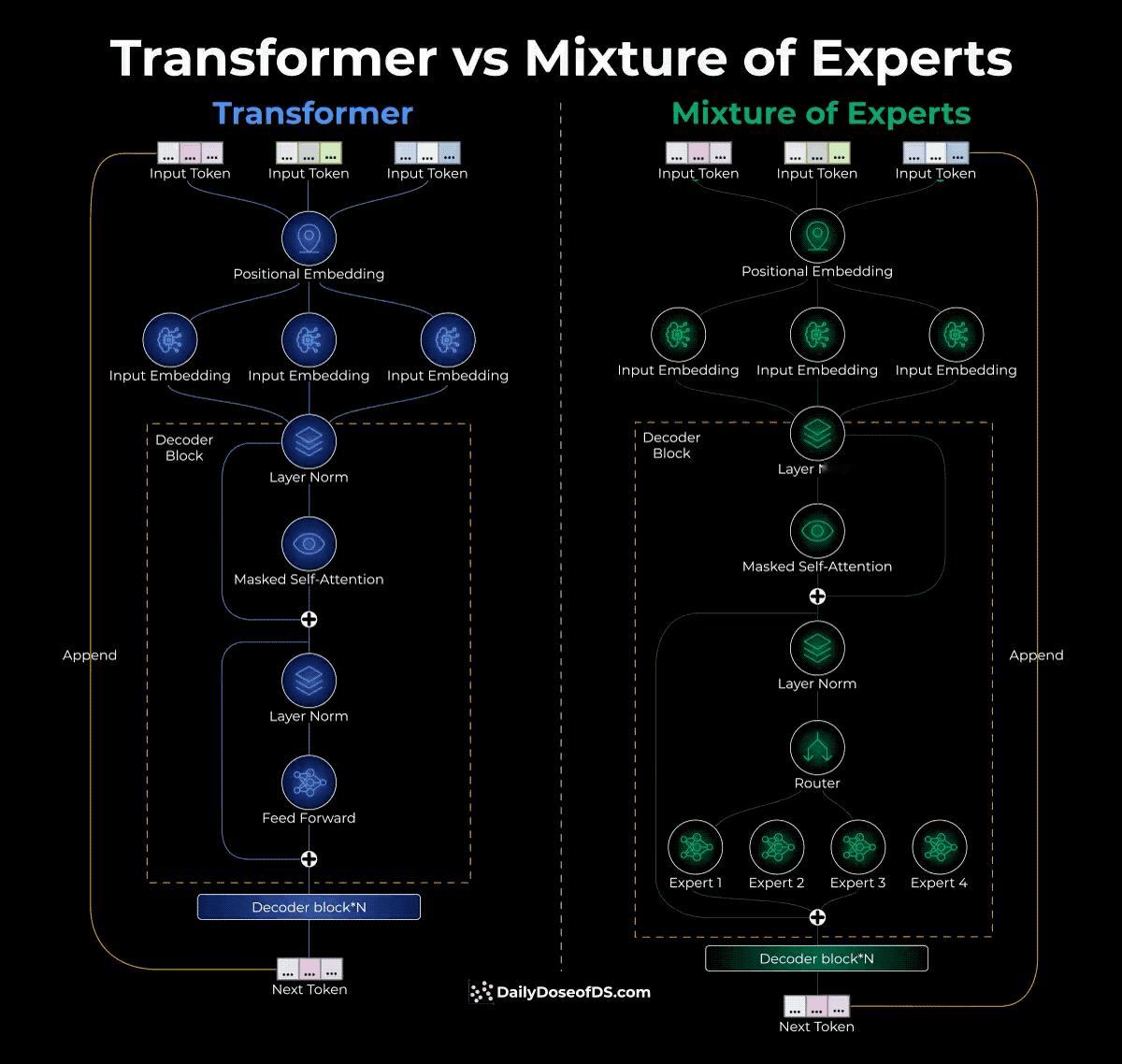
Transformer和MoE乍一看差不多,但解码器块里有本质区别。传统Transformer的解码器块长这样:输入经过层归一化,再进self-attention,输出后又是层归一化,最后接一个前馈网络(Feed Forward)。这个前馈网络是固定的,每个token都要过这么一遍。MoE的解码器块改了。前馈网络的位置被替换成了一个路由器加多个专家。路由器看到token过来,立刻给它分配到几个最合适的专家去处理,而不是所有token都走同一条路。这样带来的好处是什么?参数多但激活的少。MoE总参数量很大(比如Mixtral 8x7B,8个7B的专家加起来),但推理时每个token只经过其中几个专家,所以实际计算量反而更小,推理速度就快了。路由器怎么工作的呢?它是个多分类器,输出每个专家的softmax分数,然后选分数最高的K个。问题是这样训练会有问题。开始时假设路由器选中了专家2,专家2因为被选中就能学习,学得好了就更容易被再次选中,结果其他专家永远得不到训练机会,沦为"僵尸专家"。解决办法是两步走。第一步给路由器输出加噪声,让其他专家也有竞争机会。第二步把非top K的分数硬设成负无穷,softmax之后就是0,强制路由器不能老是选同一批专家。还有个细节是token流量控制。有的专家处理的token特别多,有的很少,这样培训进度就不均匀。所以MoE给每个专家设了上限,超过了就把多余的token分配给次优选择。总结来说,MoE通过让不同专家分工合作来提升效率,而路由器就像个智能调度员,需要学会动态选择哪些专家最合适,同时还要防止某些专家被过度依赖。Mixtral 8x7B和Llama 4这类模型就是这个思路的实现。