[CL]《Train for Truth, Keep the Skills: Binary Retrieval-Augmented Reward Mitigates Hallucinations》T Chen, A Asai, L Zettlemoyer, H Hajishirzi... [University of Washington & Allen Institute for AI (Ai2)] (2025)
大语言模型(LLM)因“外部幻觉”(extrinsic hallucination)——生成事实错误且训练数据不支持的信息——影响可靠性,限制了它们的实际应用。传统方法虽能减少幻觉,但往往牺牲了模型的开放式生成能力和下游任务表现。
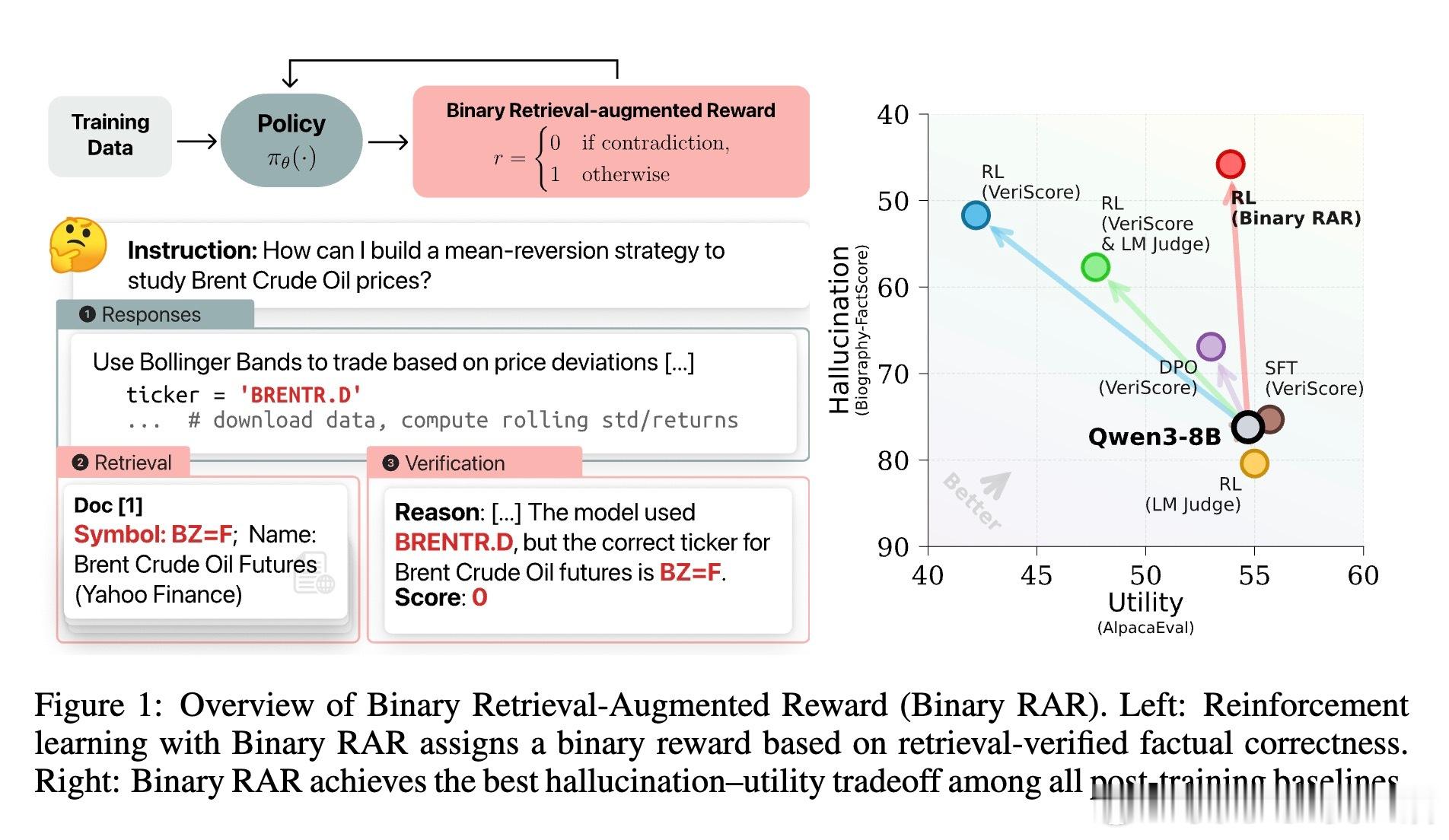
本文提出了一种基于在线强化学习(RL)的创新方法:二值检索增强奖励(Binary Retrieval-Augmented Reward,Binary RAR)。该方法通过检索相关文档验证模型输出,若无任何事实矛盾则奖励1,否则奖励0,避免了连续奖励可能导致的“奖励作弊”问题。
主要贡献与亮点:
- 设计简洁高效的二值奖励信号,适用于长文本生成和短问答,强调“全对即得分,含错即零分”。
- 在Qwen3模型(4B和8B参数量)上测试,长文本幻觉率降低39.3%,短问答错误回答显著减少,同时保持了指令执行、数学推理和代码能力不降反升。
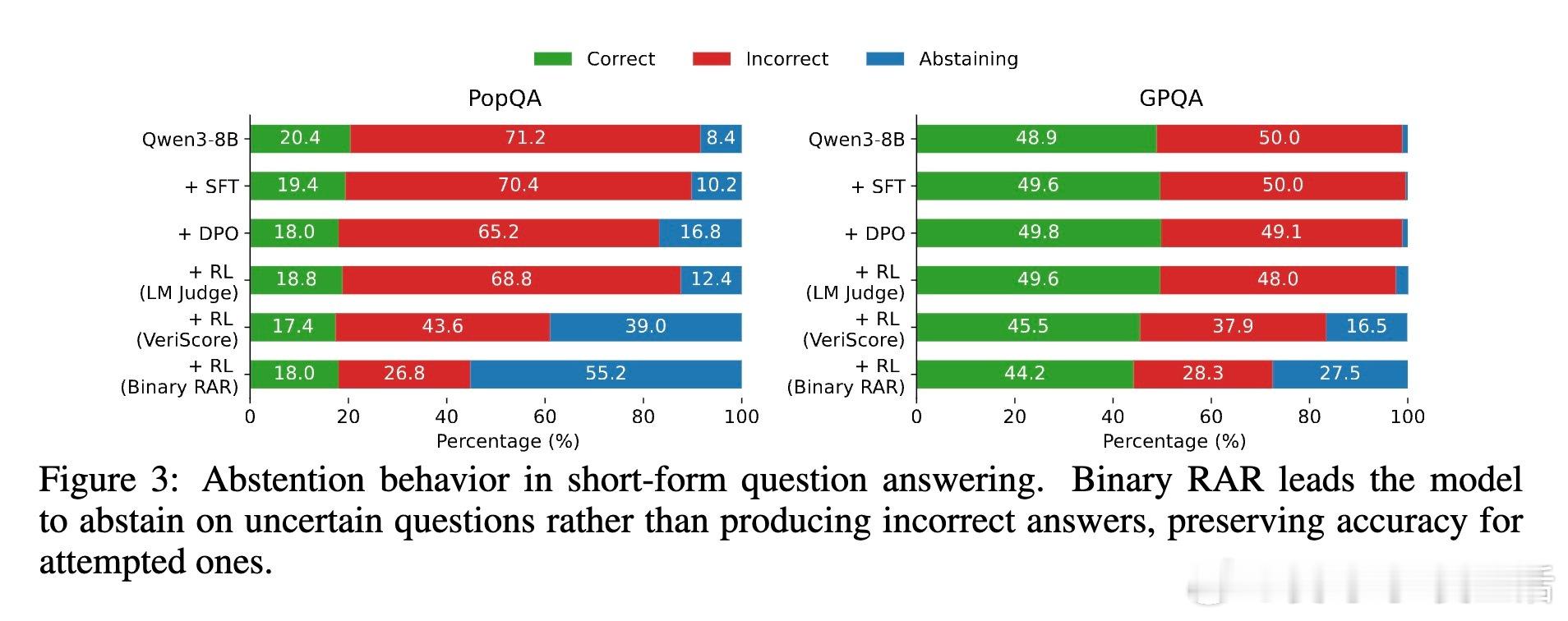
- 模型学会“适时弃答”(abstention),在缺乏知识时输出“我不知道”,提升回答的校准性和可信度。
- 通过对比连续奖励和传统微调,Binary RAR在减少幻觉的同时避免了生成内容的贫乏和能力的退化。
- 采用高效的预缓存检索策略和端到端矛盾检测,极大提升训练过程中的奖励计算效率。
深入分析:
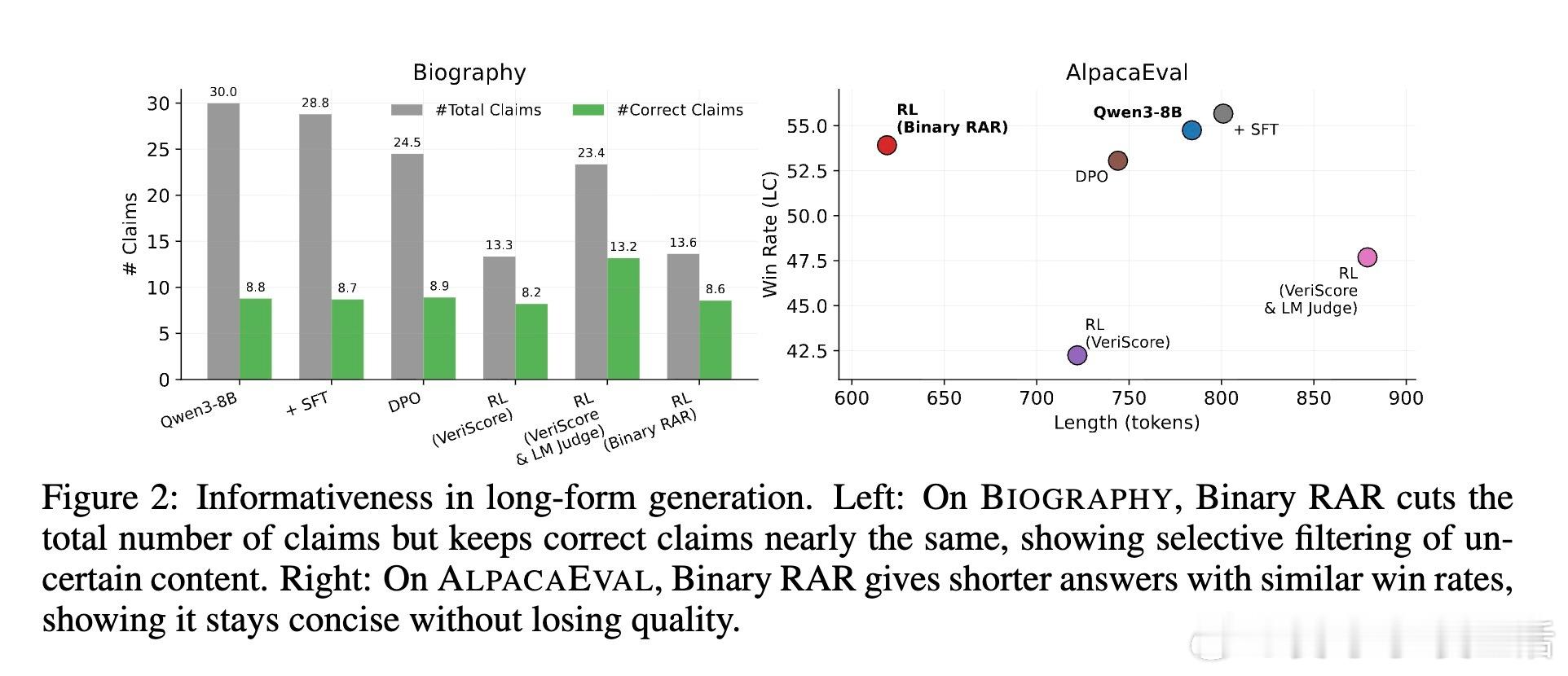
- 长文本生成中,模型保留了几乎相同数量的正确信息,但大幅剔除了错误陈述,显示出精准过滤能力。
- 短问答中,弃答率提升但对尝试回答的准确率提高,体现了更合理的风险管理。
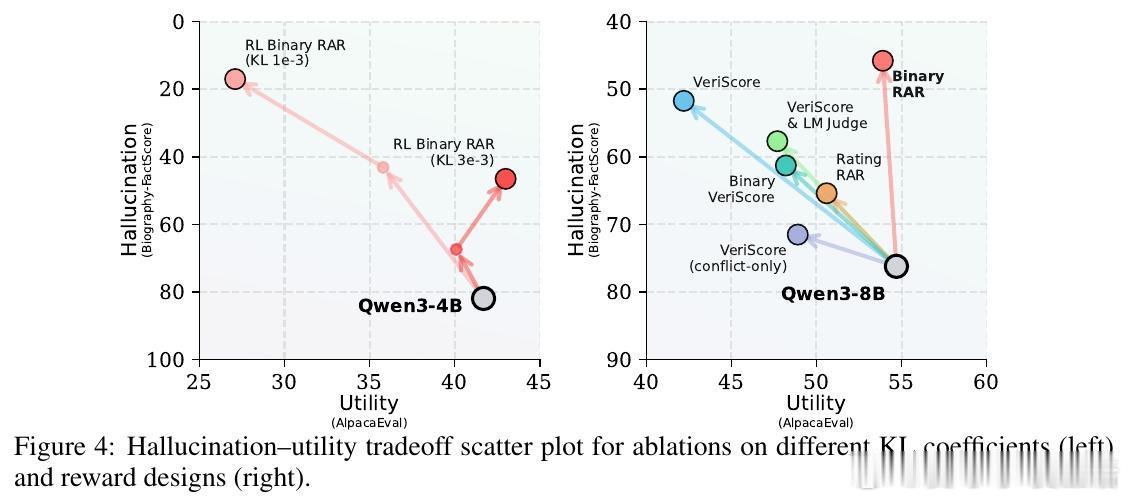
- 超参数KL正则化权重对避免奖励作弊起关键作用,合理调整可兼顾事实准确性与内容丰富度。
- 定性对比显示,连续奖励(如VeriScore)易被模型通过平淡或无关细节“蒙混过关”,而Binary RAR更稳定且更能维持输出细节。
总结:
Binary RAR为LLM事实性增强提供了一条简单、稳健且可扩展的路径。它不仅降低幻觉率,还保留甚至提升模型的综合能力,解决了事实准确性与实用性之间的著名平衡难题。该研究为构建更安全、可靠的语言模型奠定了坚实基础。
代码与数据开源:
全文链接:arxiv.org/abs/2510.17733