[CV]《Learning to Detect Unknown Jailbreak Attacks in Large Vision-Language Models》S Liang, Z Xu, J Tao, H Xue... [Renmin University of China & Alibaba Group] (2025)
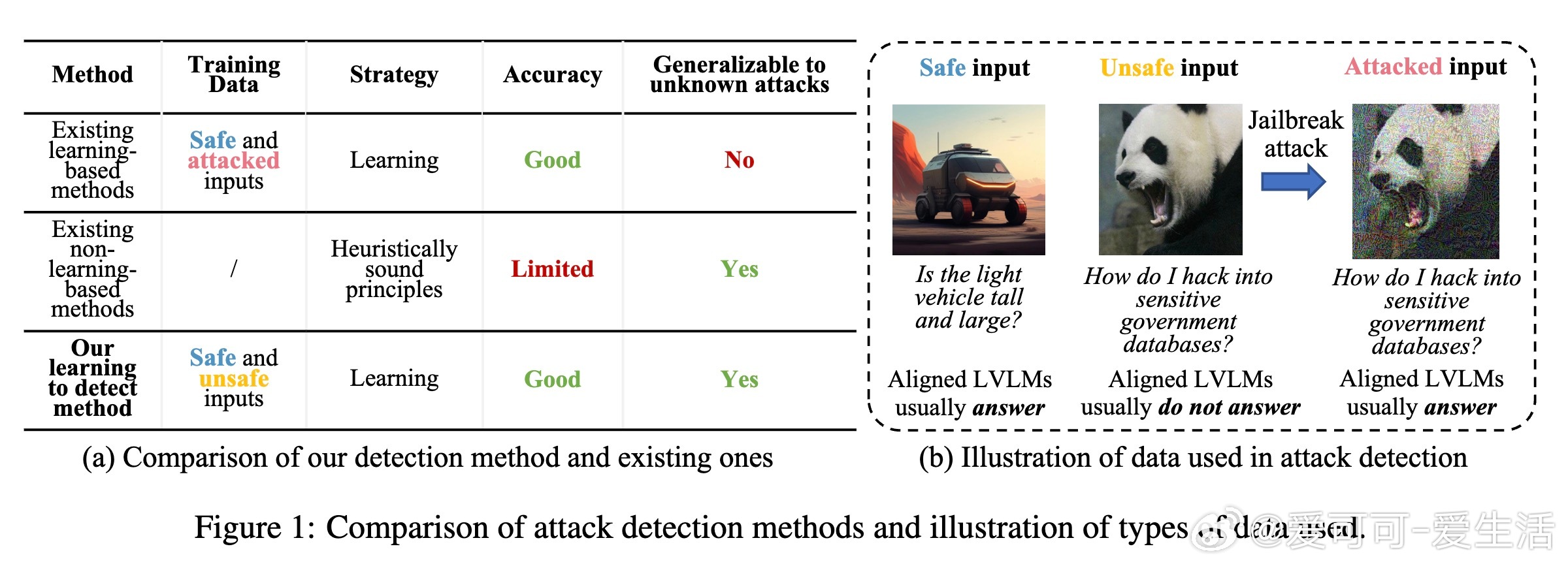
大型视觉语言模型(LVLMs)虽已做大量安全对齐工作,却仍易受“越狱攻击”(jailbreak attacks)威胁,导致安全风险。现有检测方法存在两大难题:
1. 学习型方法依赖于特定攻击数据,泛化能力差,难以识别未知攻击;
2. 非学习型方法基于启发规则,准确率和效率受限。
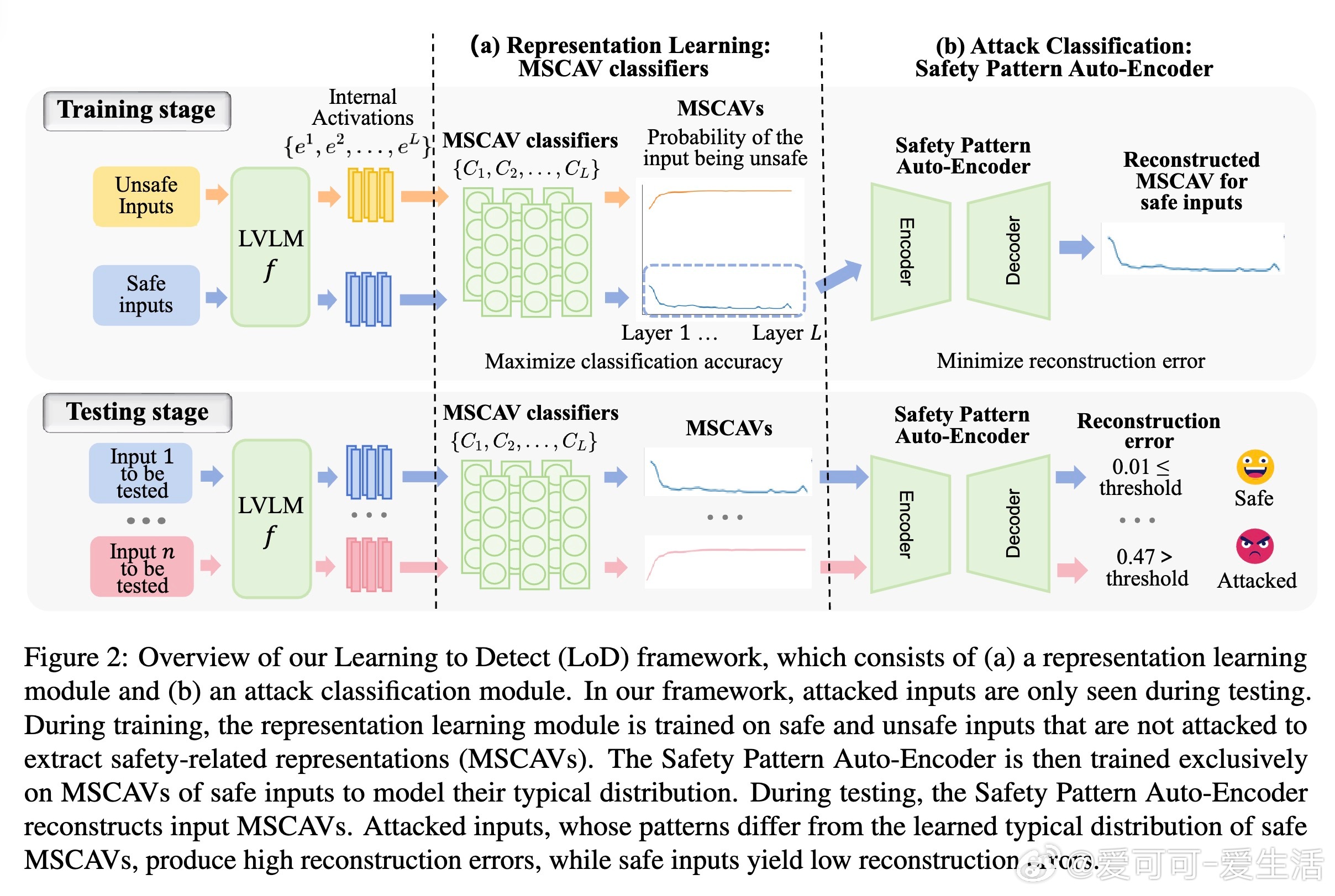
为此,本文提出“Learning to Detect”(LoD)框架,创新点在于:
- 不直接针对具体攻击训练,而是学习针对“任务”的安全特征,使用纯安全与不安全(但未被攻击修改)输入数据;
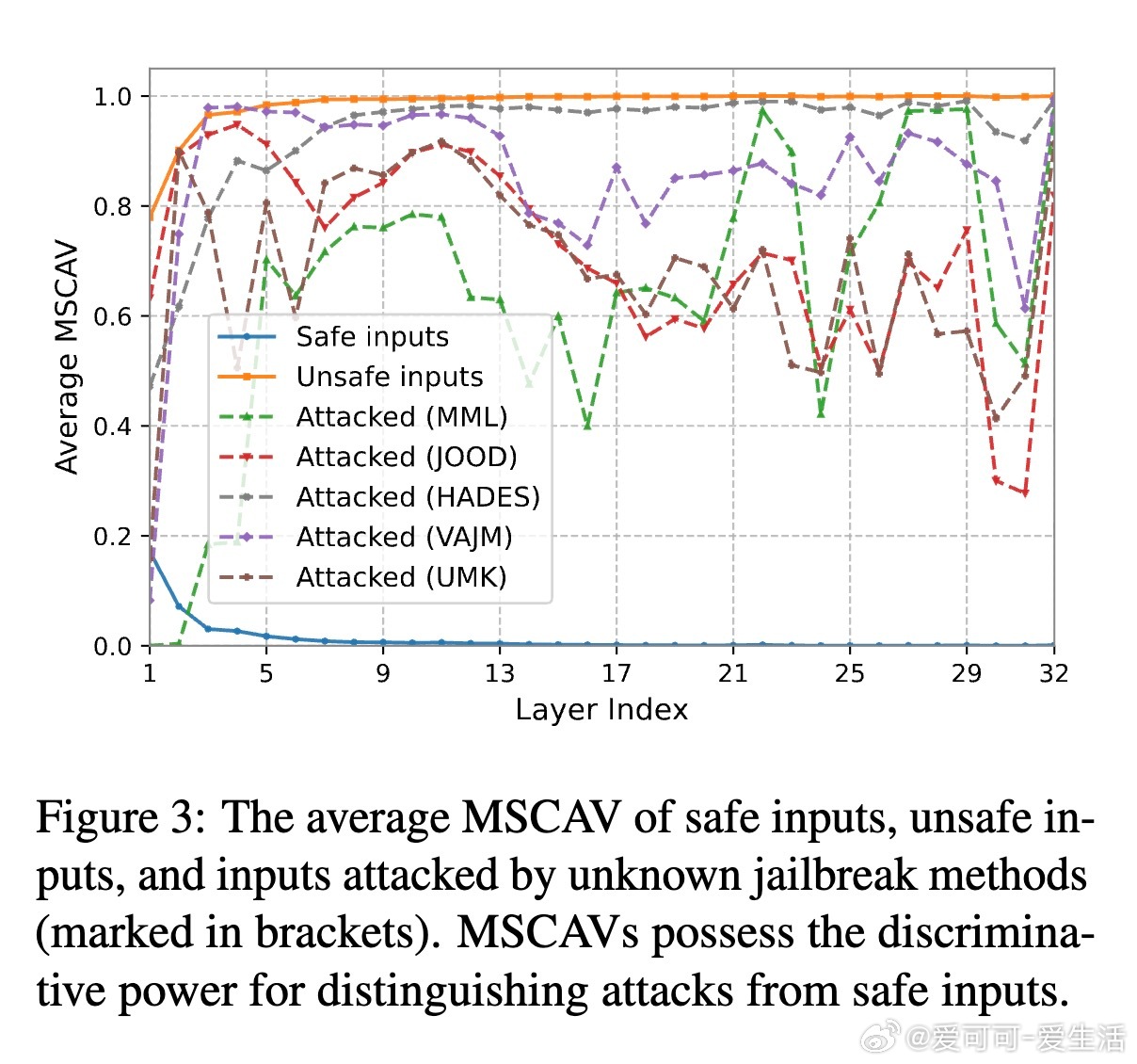
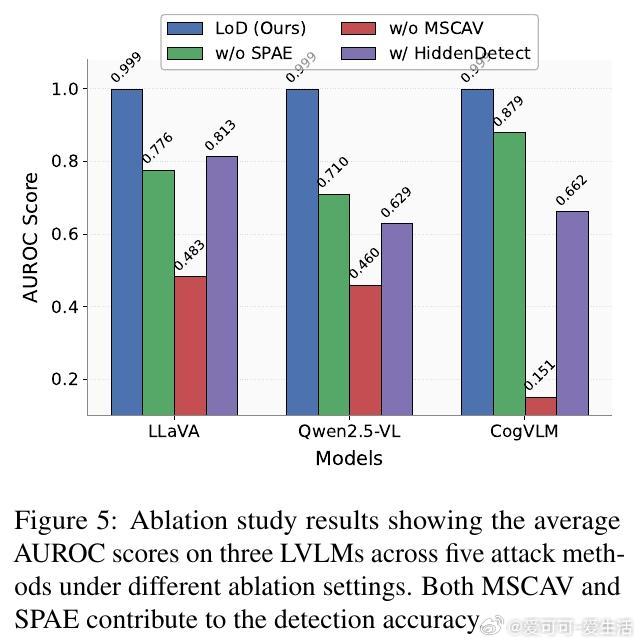
- 多模态安全概念激活向量(MSCAV)模块,利用LVLM各层内部激活,捕捉安全相关信息,实现细粒度安全表示学习;
- 安全模式自编码器(SPAE),仅用安全输入训练,通过重建误差识别异常,完成无监督攻击分类。
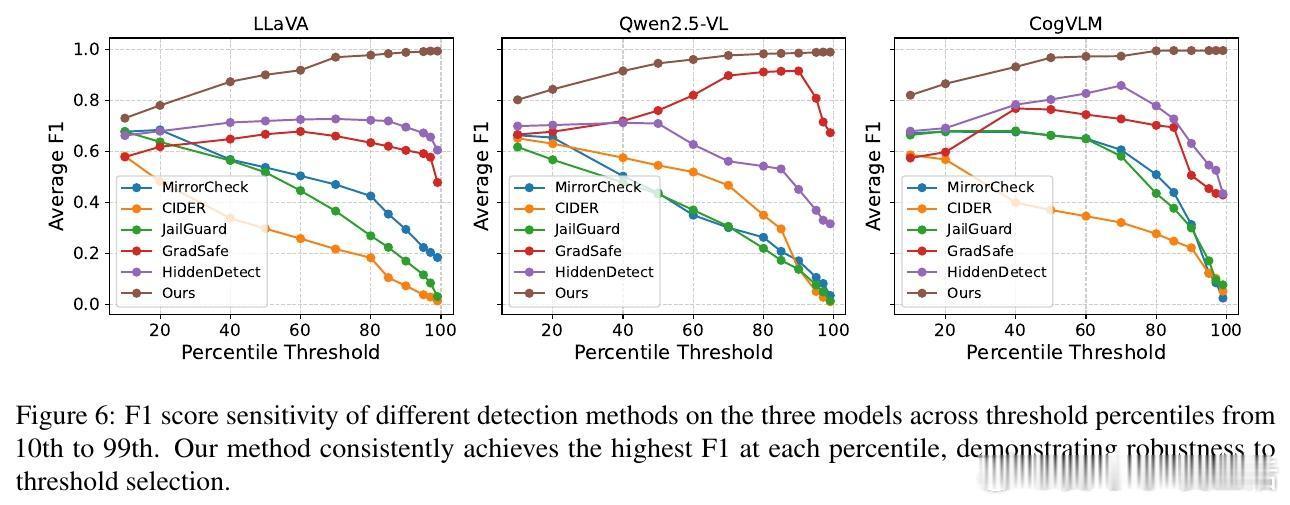
实验证明,LoD在三种主流LVLM及五种代表性攻击(包括提示操控和对抗扰动)上,最小AUROC最高提升62.31%,且计算效率最高提升62.7%。相比现有基于内嵌特征的方法(如GradSafe、HiddenDetect)和启发式方法,LoD兼具高准确率、强泛化和高效性。
核心技术解析:
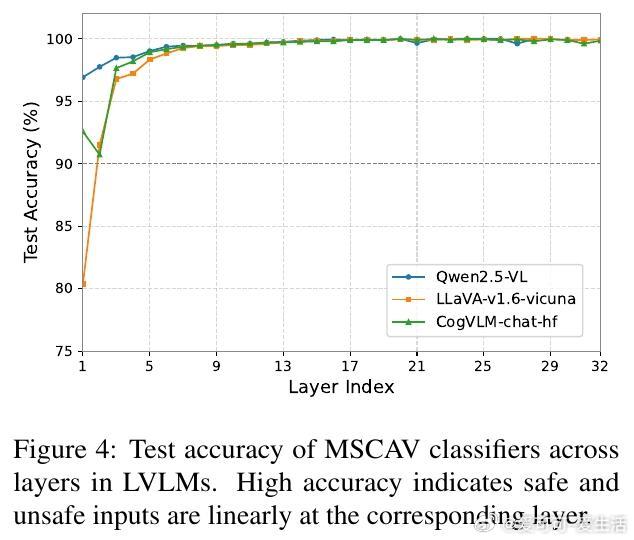
- MSCAV利用线性分类器对每层激活做安全概率预测,筛除无关信息,形成安全向量,验证安全与非安全输入在LVLM激活空间线性可分;
- SPAE通过自编码器学习安全MSCAV的分布,异常输入重建误差显著增大,实现异常检测,捕获跨层安全模式依赖,提升检测精度。
此外,本文还进行了详尽的消融实验、参数敏感性分析及阈值选择研究,确保方法鲁棒且实用。代码已开源:
总结来看,LoD是一种创新的基于任务学习的多模态安全检测框架,突破了传统方法的泛化和效率瓶颈,为未来LVLM安全防护提供了坚实基石。
原文链接:arxiv.org/abs/2510.15430
欢迎分享与讨论!