[LG]《Transmuting prompts into weights》H Mazzawi, B Dherin, M Munn, M Wund... [Google Research] (2025)
理论揭秘!如何将文本提示“转化”为模型权重更新?
近日谷歌研究发布论文《Transmuting prompts into weights》,为控制大型语言模型行为提供了全新理论框架。👇
1️⃣ 背景:当前主流控制技术分两类:
- 激活引导(Activation Steering):通过向模型隐层加入“引导向量”调整输出,通常用对比提示激活均值作为启发式计算依据。
- 模型编辑(Model Editing):直接修改模型权重矩阵(尤其是前馈层),实现知识或行为更新,多用低秩矩阵更新。
2️⃣ 论文贡献:
- 证明了提示对模型的影响可看作一系列“令牌依赖”的权重更新(称为token patches),这些更新可在多层Transformer中递归传播。
- 创新提出“思维更新”(thought patches):将依赖具体令牌的权重更新聚合成“令牌无关”的思维向量和思维矩阵,能复用且理论上精准近似提示的全部语义信息。
- 该框架首次系统解释了激活引导向量和低秩权重编辑为何有效,统一了这两类实证方法的数学本质。
3️⃣ 理论亮点:
- 思维向量即为对比激活差异的均值,严格对应最小二乘解,理论支持了多年来用激活均值做引导向量的经验做法。
- 思维矩阵由多组秩一矩阵外积累加构成,完美诠释了低秩权重编辑为何能够精准编码复杂任务和指令。
4️⃣ 实验验证:
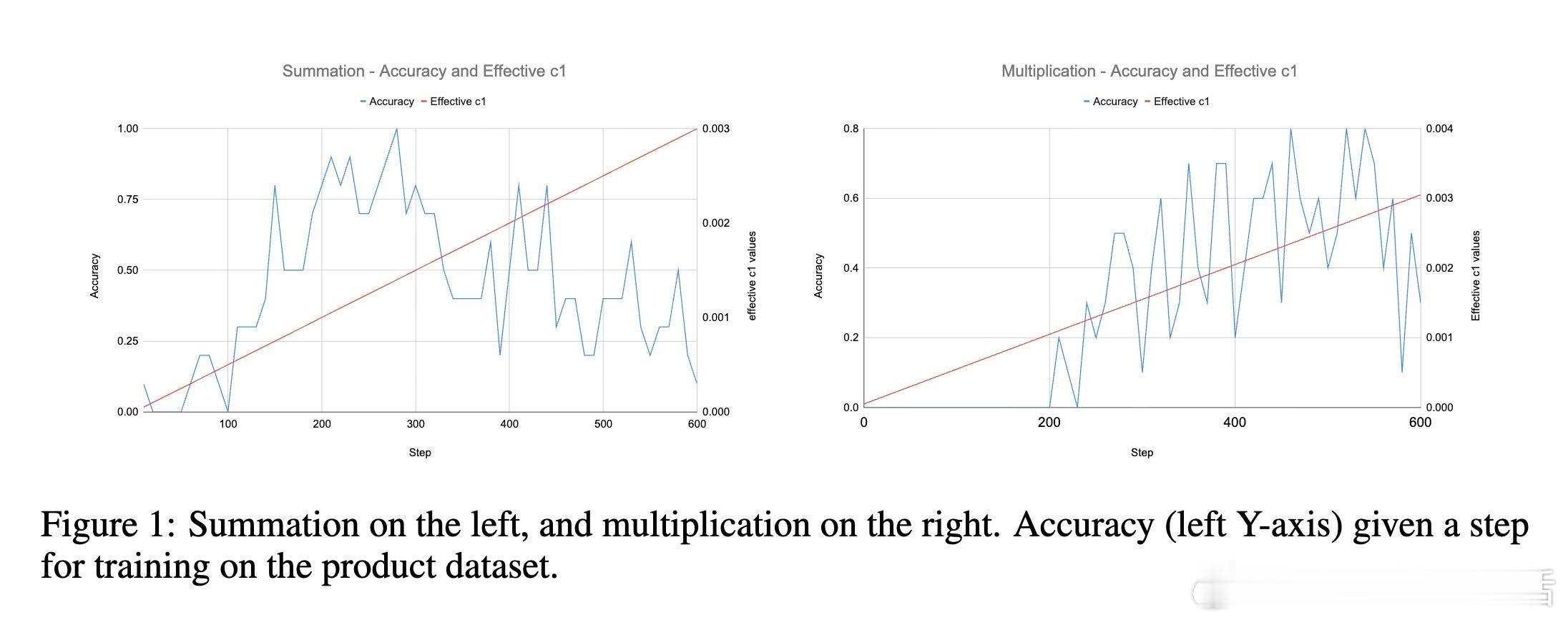
- 在1B参数Gemma 3.0模型上,直接用思维更新权重,实现无提示的三位数加法和乘法,最高准确率达80-100%。
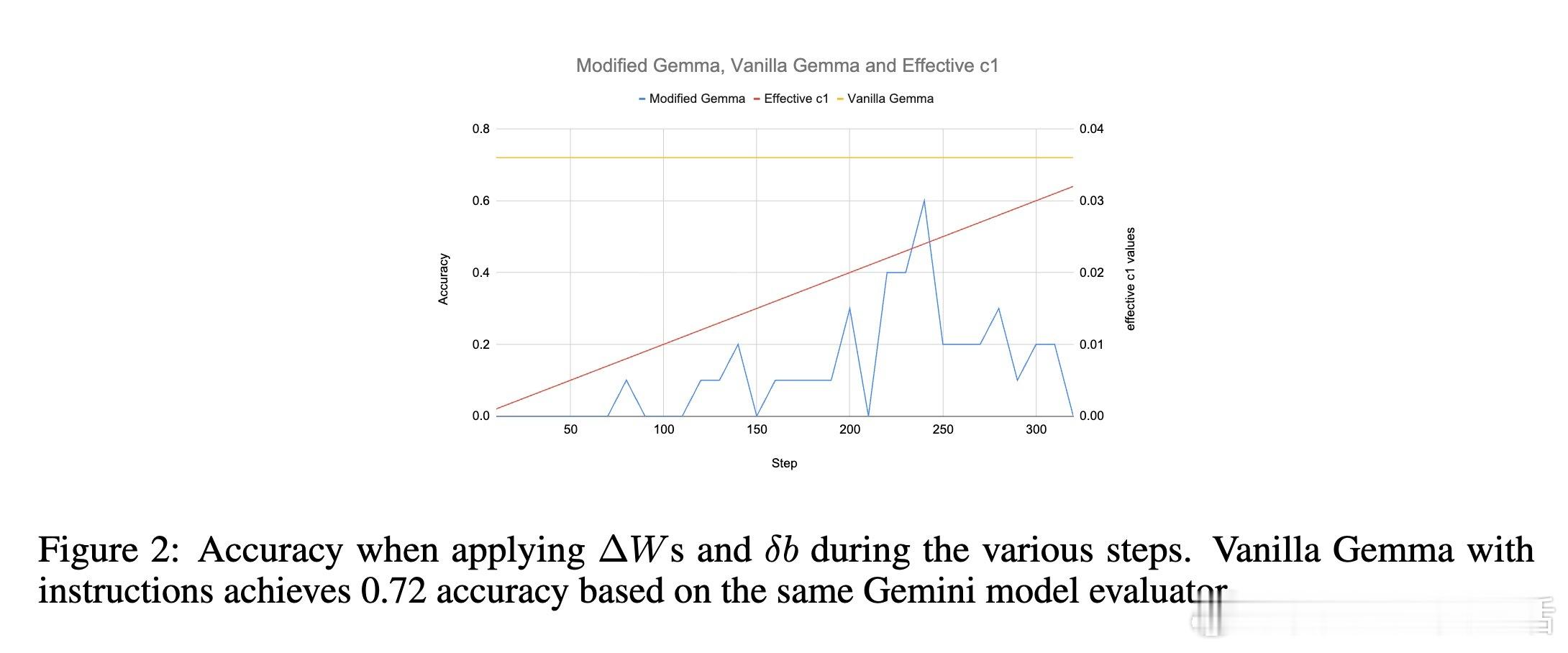
- 在机器翻译任务中,思维权重更新使模型无需提示即可实现最高60%准确率(提示条件下72%)。
- 实验揭示该方法虽较直接提示略逊,但为无需反向传播即可专门化模型提供了新路径。
5️⃣ 未来展望:
- 思维更新为深入理解大模型的内在计算机制和上下文学习提供了强大工具。
- 有望推动更稳定、可复用的模型控制技术,减少对提示设计和重复输入的依赖。
🔗详读论文:
总结:该研究突破了以往经验主义范式,首次从Transformer计算原理出发,构建了文本提示到权重更新的理论桥梁,开启了语言模型控制的全新科学时代。欢迎转发分享,让更多人了解这项开创性工作!大模型 模型控制 Transformer 机器学习 AI研究