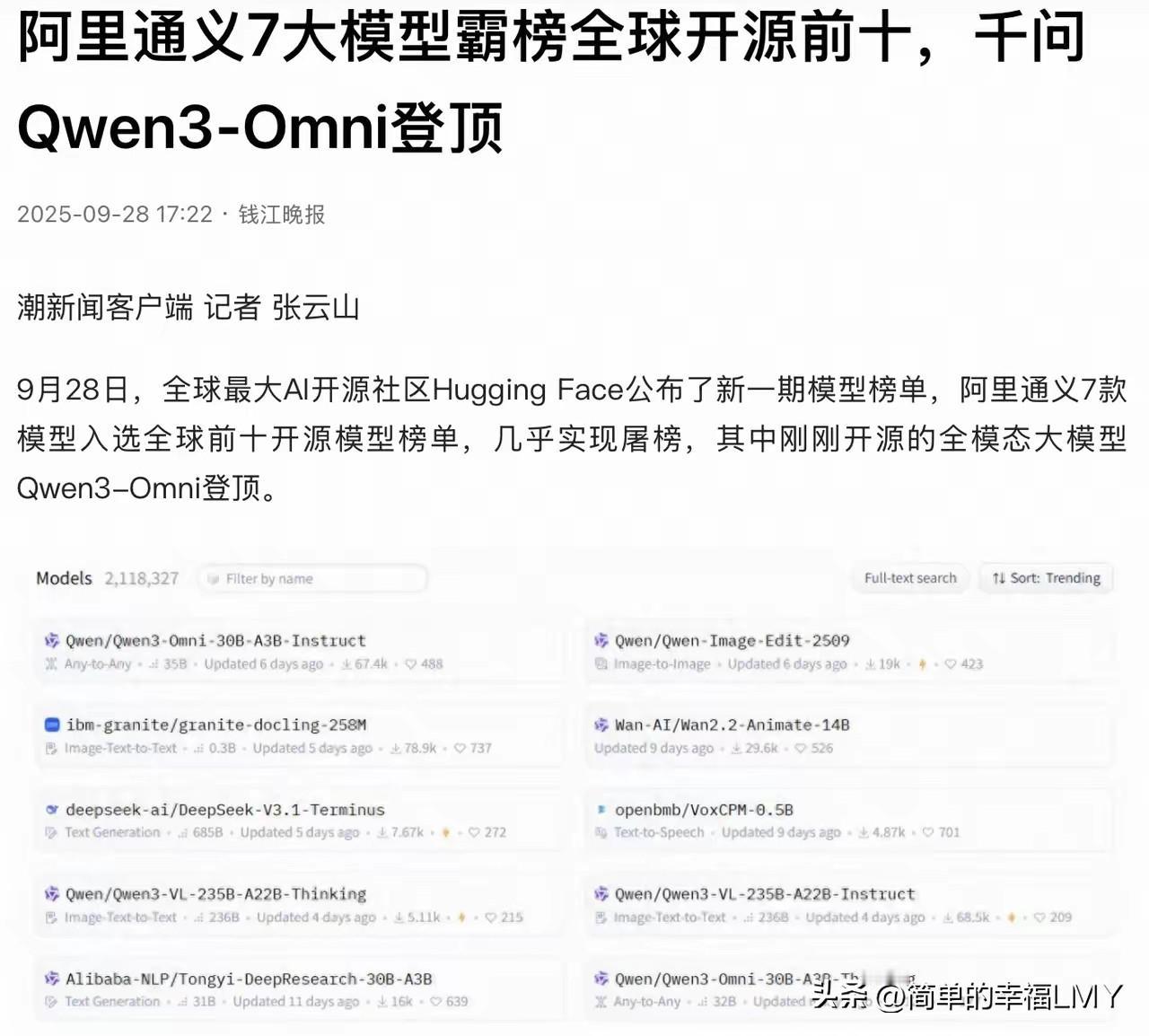
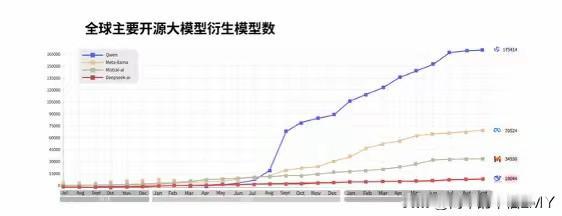
国内还没传开,但在国外已经已经杀疯了,世界正在重新评估中国的真正实力! 9月28日,全球最大AI开源社区Hugging Face的新榜单炸了锅。阿里通义7款模型齐刷刷挤进全球开源前十,刚开源的全模态大模型Qwen3-Omni直接登顶榜首,近乎完成“屠榜”壮举。 这事儿在国外科技圈早已议论纷纷,国内却鲜有人知,而它真正的分量,藏着世界重新评估中国科技实力的密码。不少人看到榜单的第一反应是错愕:怎么是阿里? 在太多人的固有印象里,阿里似乎只和电商、支付绑定,提起AI巨头,总先想到别家。曾几何时,“阿里只有电商基因”的调侃不绝于耳,谁能想到,这家企业早已在AI赛道默默磨剑,一出手就搅动了全球格局。 这份成绩单哪里是偶然爆发?分明是厚积薄发的必然结果。 那些质疑“中国AI只会模仿”的声音,此刻被榜单狠狠抽了耳光。李飞飞领衔的斯坦福HAI研究所发布的《2025年人工智能指数报告》里藏着更硬核的证据。 2024年全球重要大模型中,阿里独占6席,按模型贡献度排名稳居全球第三,妥妥的国产AI领头羊。要知道,斯坦福的这份报告向来被视作AI领域的“风向标”,能在其中占据如此分量,绝非“模仿”二字能轻易概括。 登顶的Qwen3-Omni到底有多强?作为全模态大模型,它能像人类一样“听、说、读、写”,在音频和音视频处理领域实现了业内首次突破,文本、图像、声音、视频等多种数据类型都能轻松驾驭。 再看同系列的Qwen3-235B-A22B,总参数量高达2350亿,实际激活仅需220亿,靠着混合专家架构实现了“快思考”与“慢思考”的融合,算力消耗大幅降低。 更惊人的是部署成本,仅需4张H20显卡就能运行满血版,显存占用只有同类模型的三分之一,这在行业内简直是降维打击。性能硬不硬,数据说了算。 Qwen3在36万亿tokens的海量数据上完成预训练,覆盖119种语言和方言,是上一代模型数据量的两倍。在编程、数学、知识问答等核心评测中,它不仅达到同规模业界最佳水平,甚至在非思考模式下,仅凭30亿激活参数就能比肩GPT-4o、Gemini 2.5-Flash等闭源巨头。 256K的长文本理解能力,更是让处理超长上下文如同探囊取物,这些实力哪项是靠“模仿”能得来的?阿里的聪明之处,更在于用开源策略走出了一条“中国式创新路径”。没有把技术攥在手里敝帚自珍,反而敞开大门吸引全球开发者。 这种开放不是无私奉献,而是最高级的布局——通过共享技术聚拢生态,再将生态优势转化为标准定义权。如今通义系列已服务超100万企业用户,从人工智能审核到游戏代码生成,从汽车座舱智能交互到能源装备的故障预判,AI大模型已然成了实体经济的“新底座”。 很难想象,汽车工厂里,通义模型能通过分析设备振动数据提前预警故障,让生产线停机时间减少三成;能源行业中,它能精准测算风电功率,让清洁能源利用率提升近两成。 连游戏公司都在用它快速生成场景代码,开发效率翻了一倍。这些渗透在产业肌理中的应用,比榜单排名更能说明问题:中国AI早已跳出“实验室阶段”,实实在在地赋能百业。 这场突围的意义,远不止一家企业的胜利。它标志着中国科技企业正从“技术应用者”向“底层架构贡献者”蜕变。过去提起AI底层技术,总绕不开国外的框架和模型,如今阿里用7款前十模型证明,我们不仅能跟上节奏,更能制定规则。 全球开发者在Hugging Face上疯狂下载Qwen3系列,用它搭建应用、改进算法,这种技术辐射力,正是中国科技话语权提升的最好证明。为什么是阿里?答案藏在时间里。 早在多年前,阿里就投入重金组建AI团队,从底层算法到硬件适配,每一步都走得扎实。没有捷径可走,没有弯道可超,36万亿tokens的数据积累,无数个日夜的模型调优,才有了今天的厚积薄发。 这也给所有中国科技企业提了个醒:核心技术从不是天上掉下来的,唯有长期主义的坚守,才能在关键赛道占据主动。如今再看“中国AI只会模仿”的论调,更像个笑话。 从Qwen3系列的技术突破,到百万企业的落地应用,再到全球开发者生态的构建,中国AI已经完成了从跟跑到并跑,甚至在部分领域领跑的跨越。Hugging Face的榜单只是一个开始,未来还会有更多中国模型、中国技术在全球舞台上崭露头角。 世界确实该重新认识中国科技了。不再是“廉价制造”的标签,不再是“模仿跟风”的偏见,而是有能力在底层架构领域亮剑,有实力用技术赋能全球的创新力量。阿里的屠榜不是终点,而是中国科技突围的新起点。 当更多企业像阿里一样沉下心做研发,当更多技术像Qwen3一样实现突破,中国科技必将在全球竞争中占据更重要的位置。这一天,已经不远了。