[LG]《Generative Model Inversion Through the Lens of the Manifold Hypothesis》X Peng, B Han, F Yu, T Liu... [Hong Kong Baptist University] (2025)
生成模型反演攻击的新视角:利用流形假设揭示梯度结构与隐私风险的内在联系
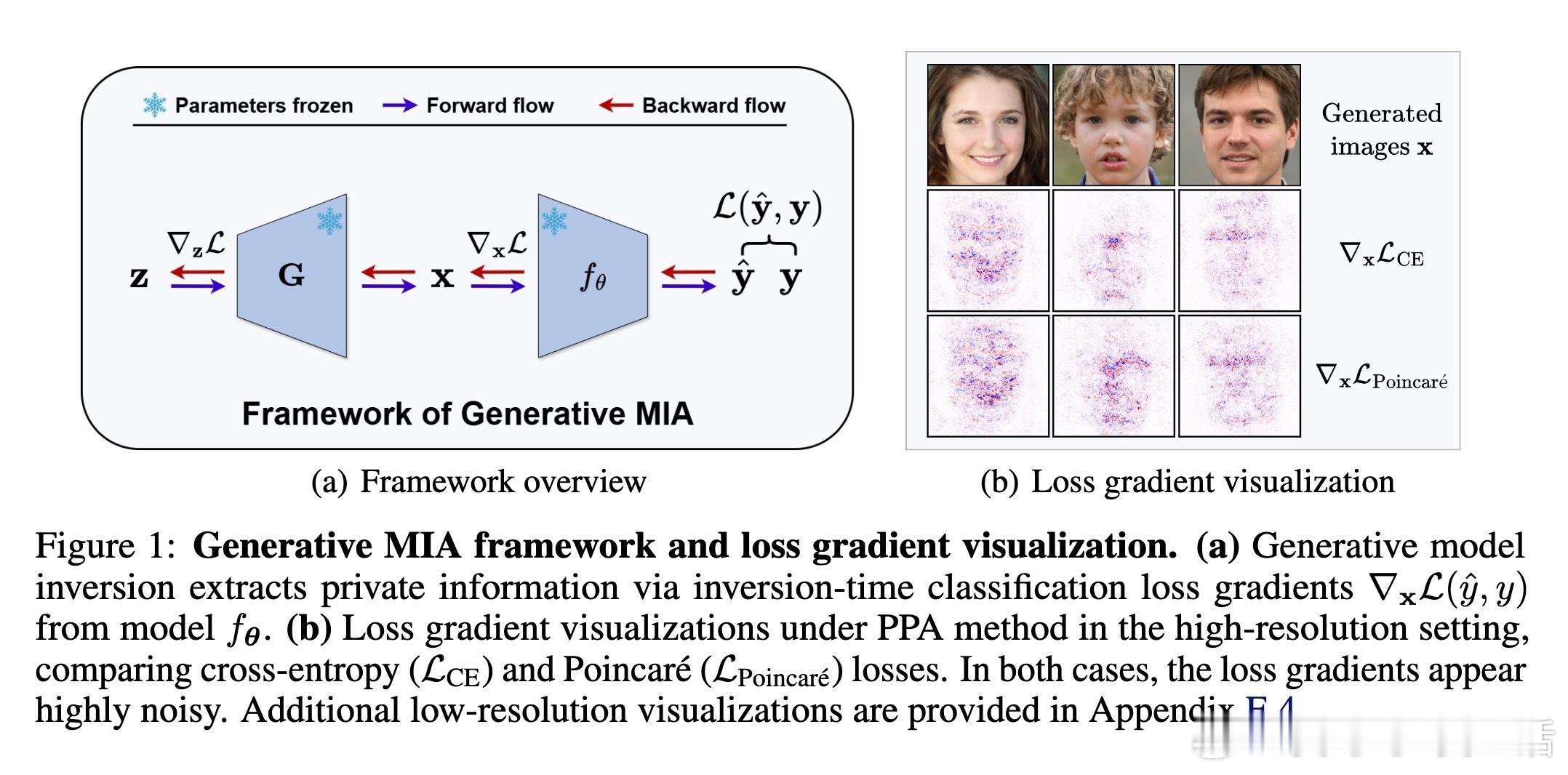
• 生成模型反演攻击(MIA)利用GAN学习图像先验,约束优化于生成器潜空间,显著提升隐私数据恢复的视觉质量和语义相关性。
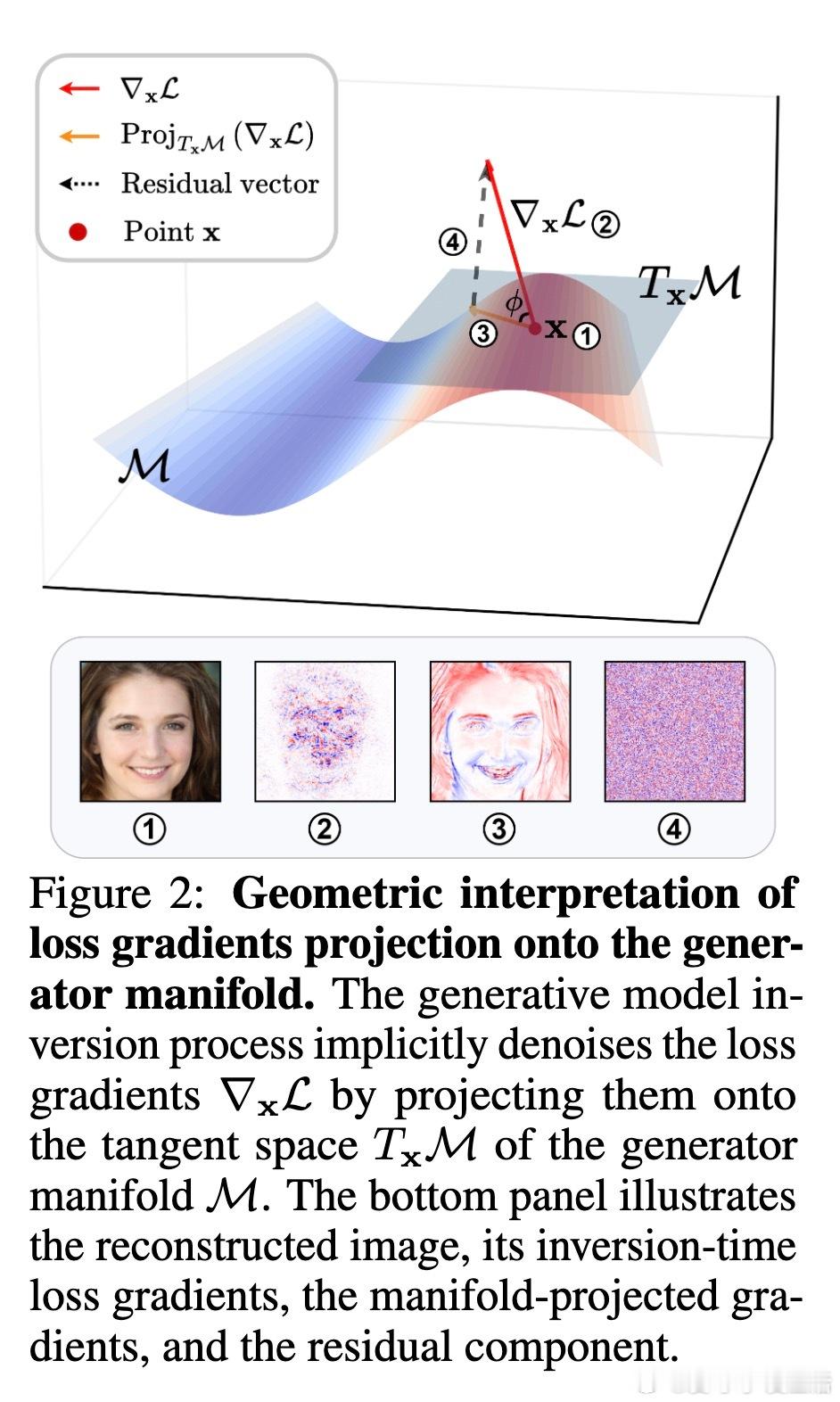
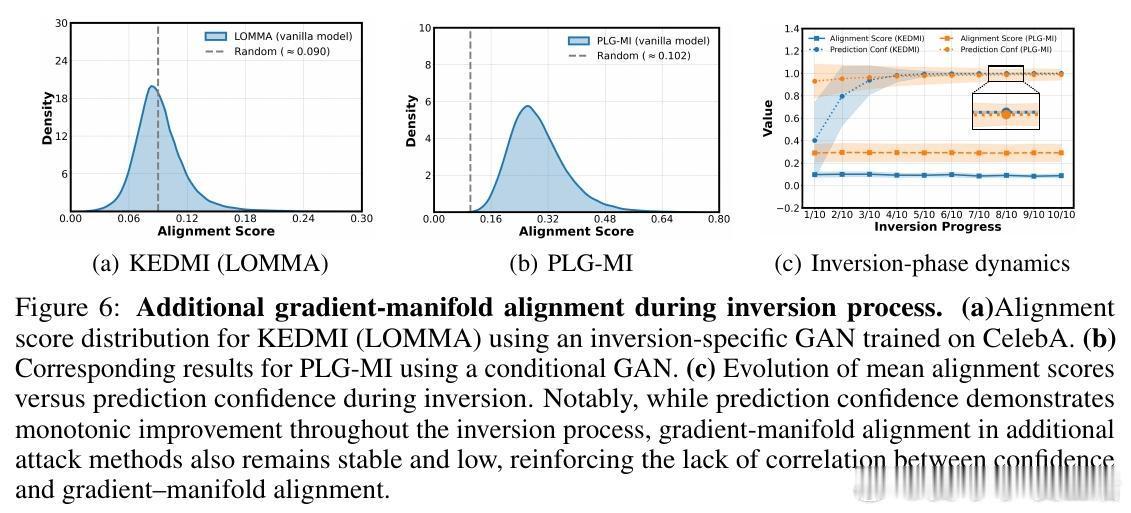
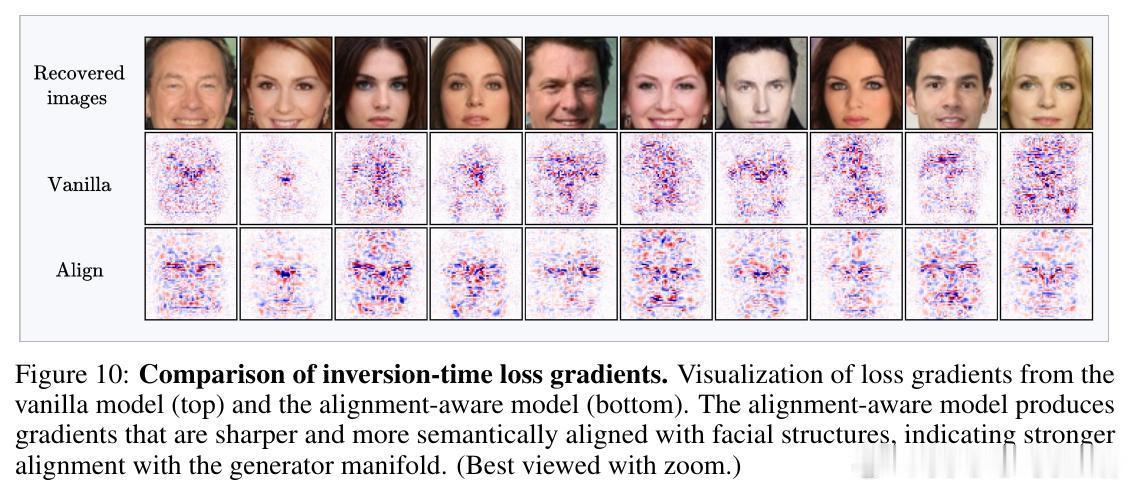
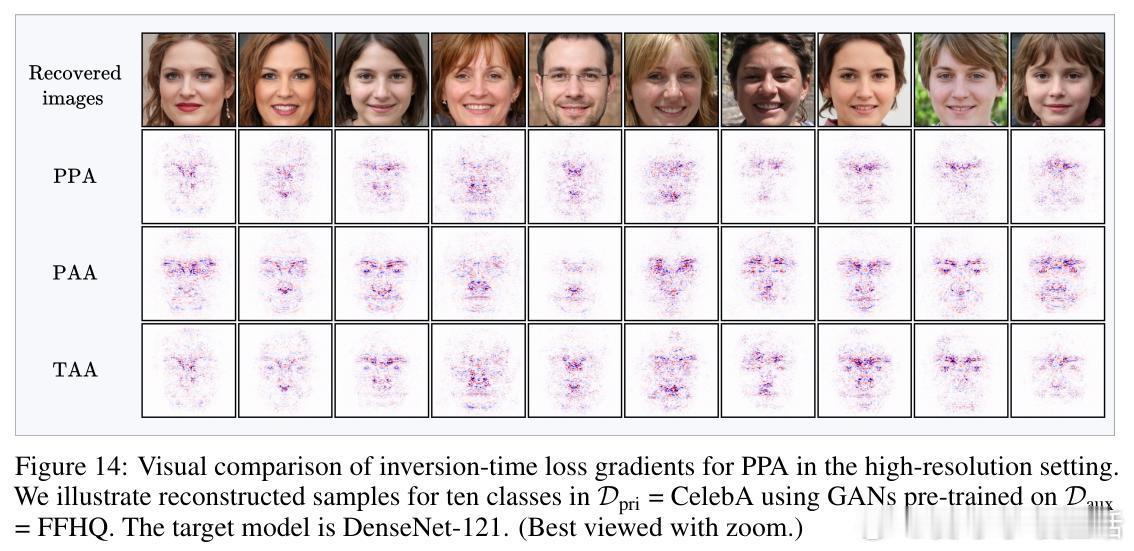
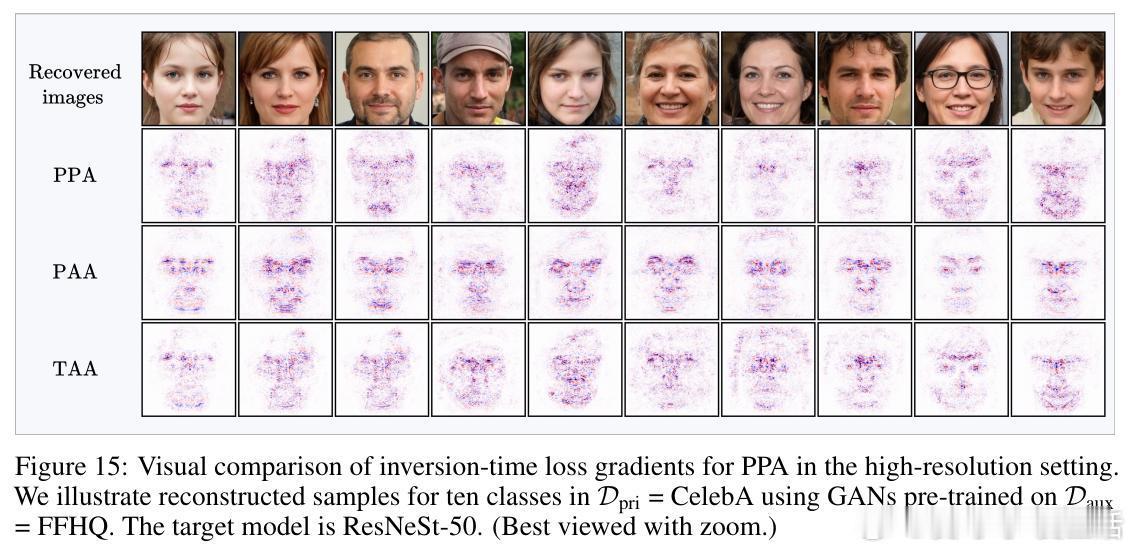
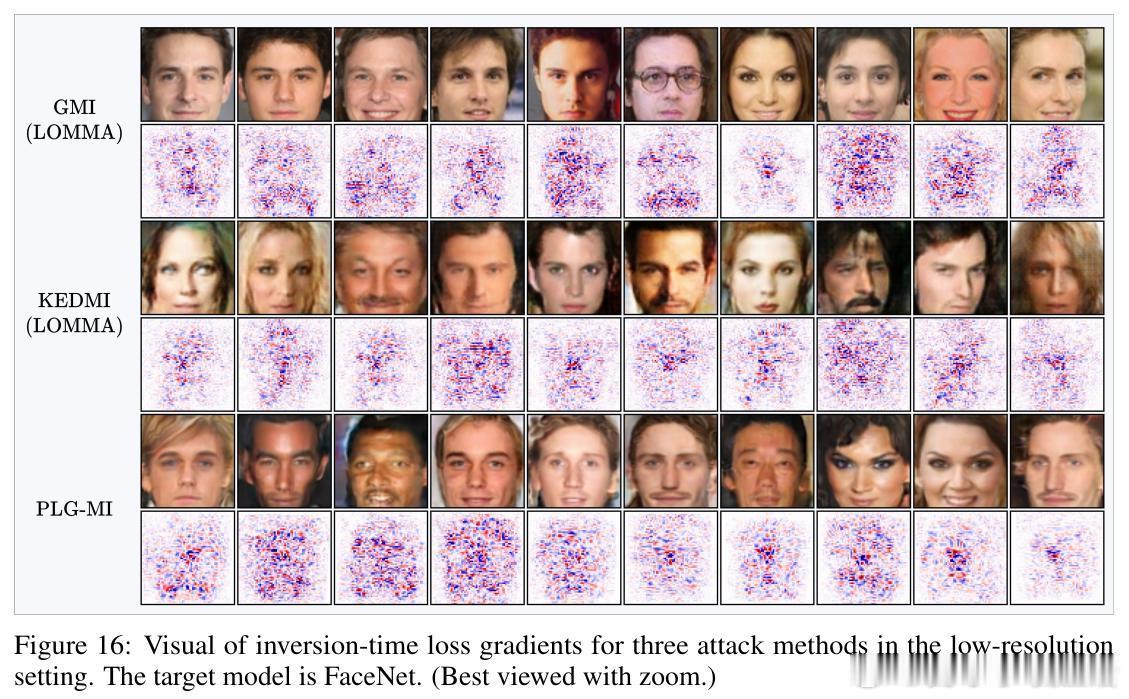
• 研究发现,反演过程中的损失梯度对合成输入极为嘈杂,但隐式地通过投影到生成器流形的切空间完成梯度去噪,保留与流形一致的有效信号,剔除离流形的噪声分量。
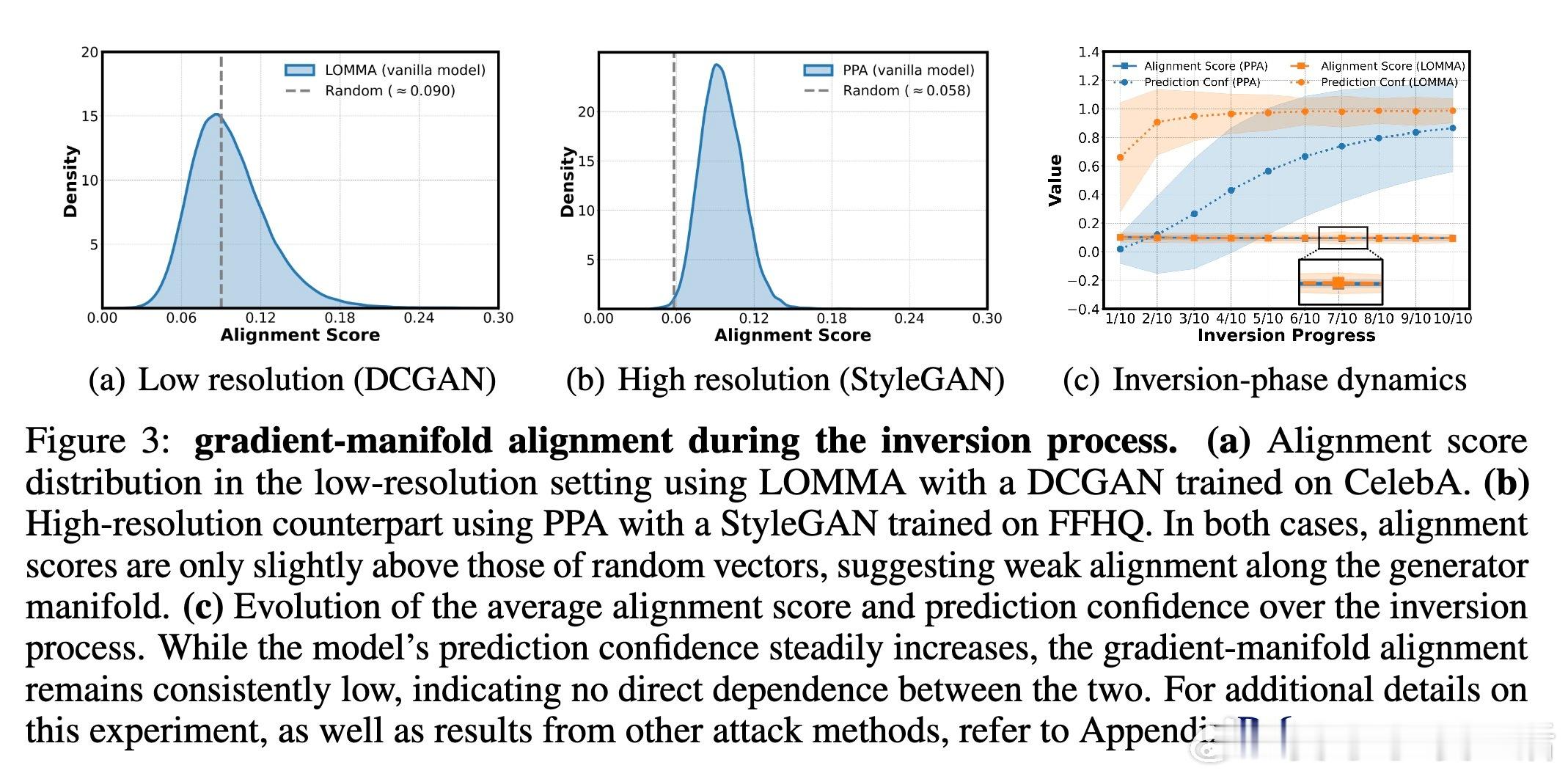
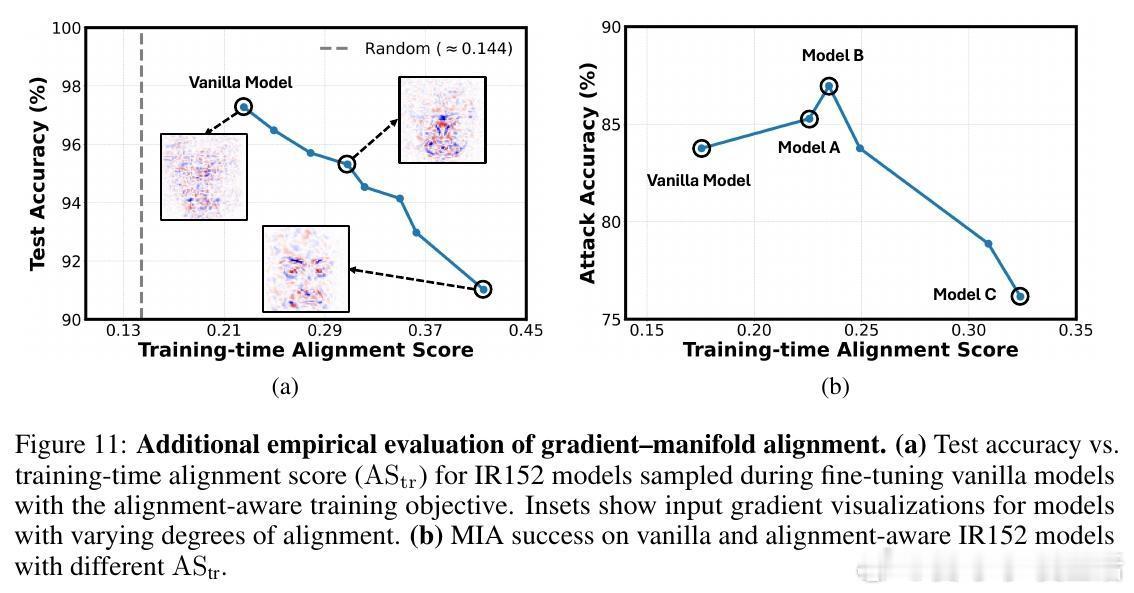
• 通过计算梯度与流形切空间的夹角余弦(alignment score),发现传统训练模型的梯度与流形对齐度低,意味着梯度携带的类别相关信息有限。
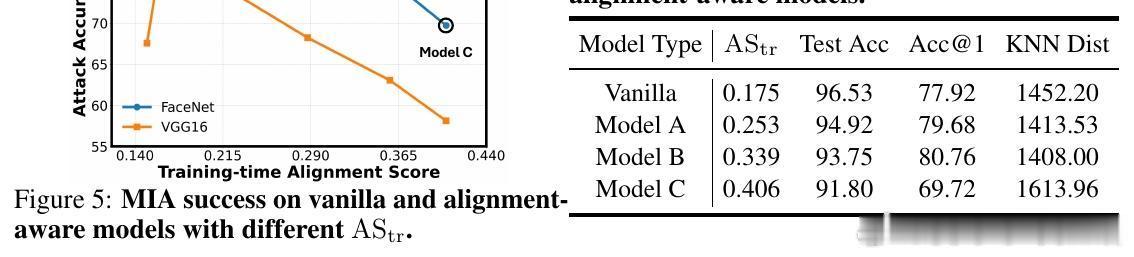
• 提出核心假设:梯度与生成器流形切空间的对齐度越高,模型越易遭受生成模型反演攻击。
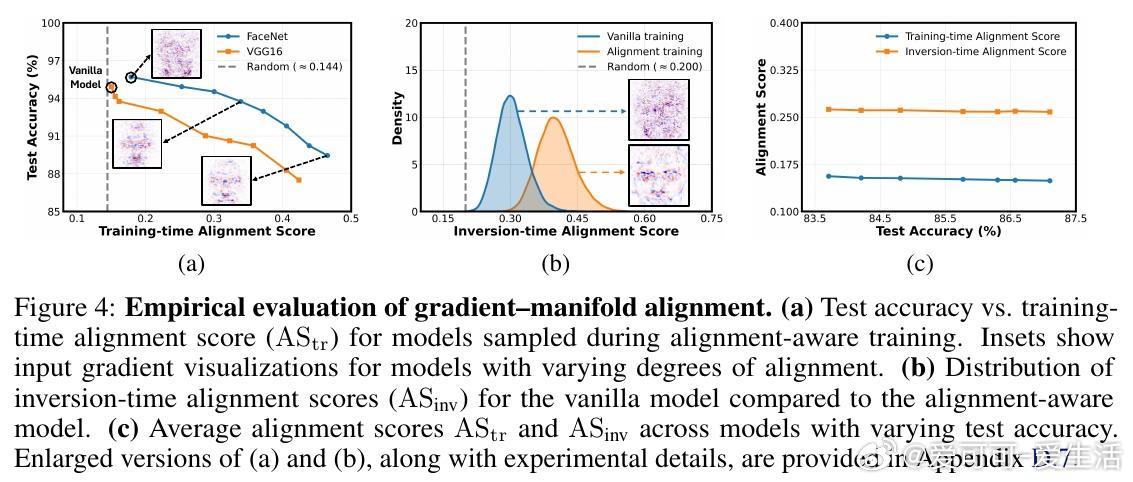
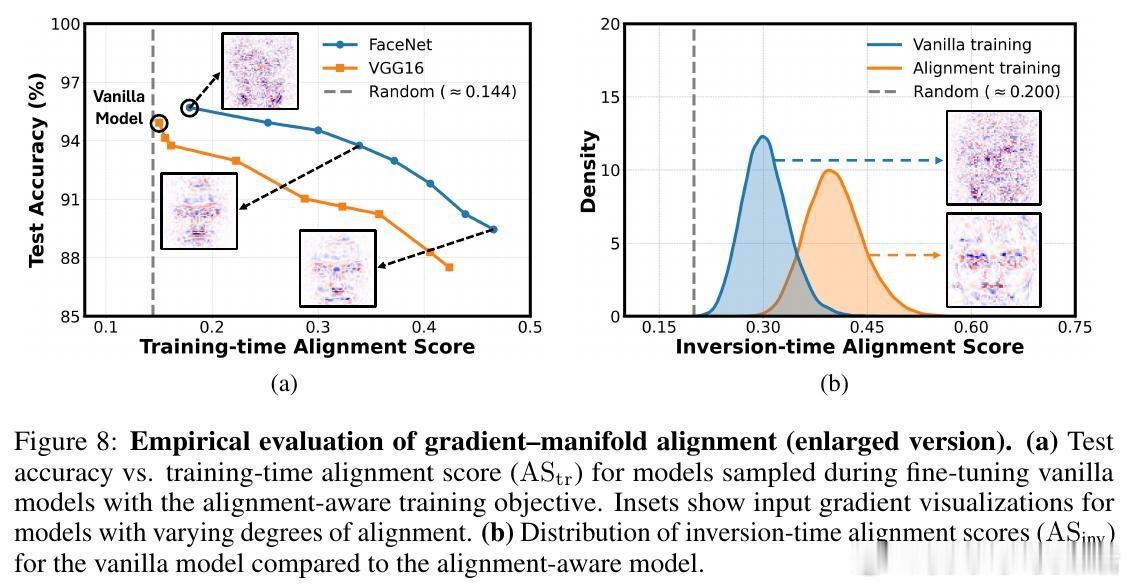
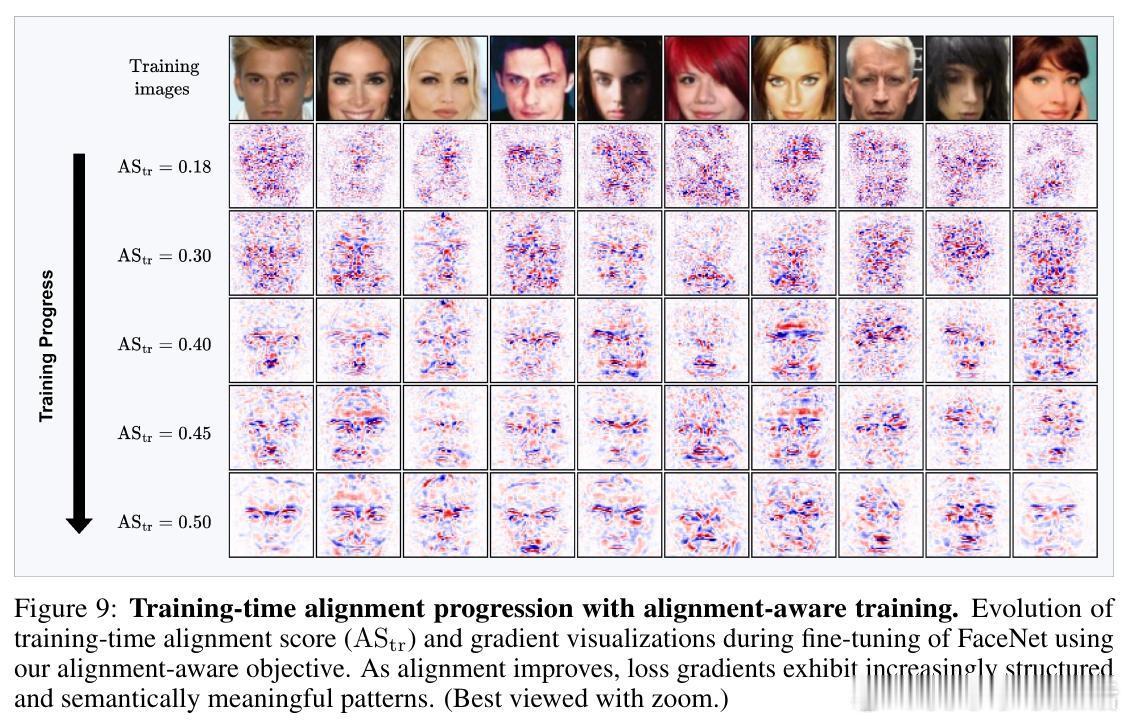
• 设计了一种结合预训练变分自编码器(VAE)估计数据流形切空间的训练目标,显式促进输入梯度与流形对齐,提升模型反演攻击的成功率,验证了假设的正确性。
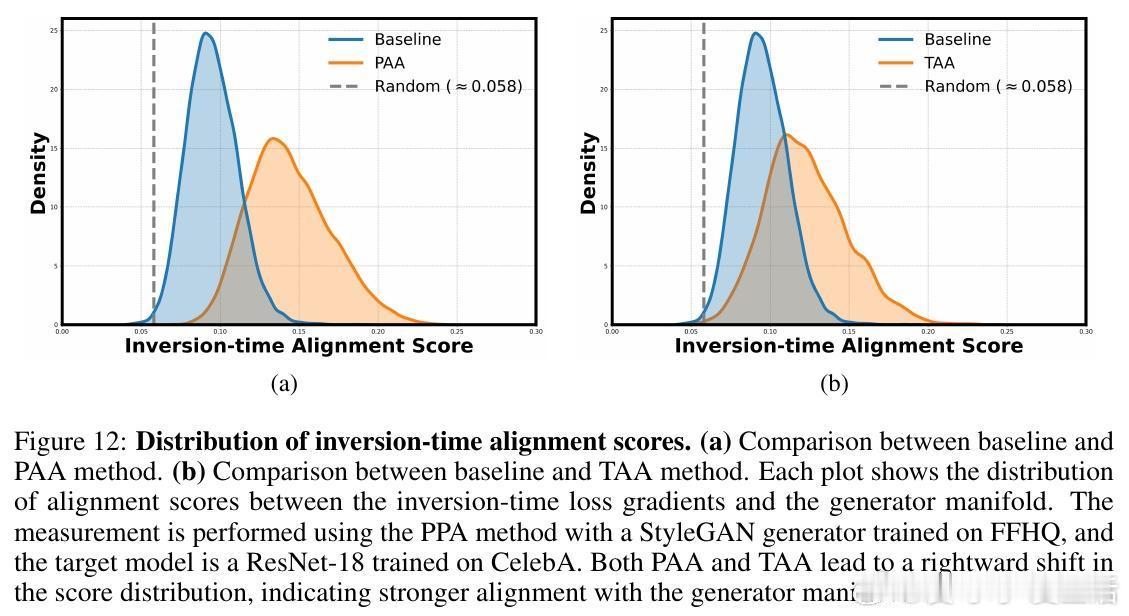
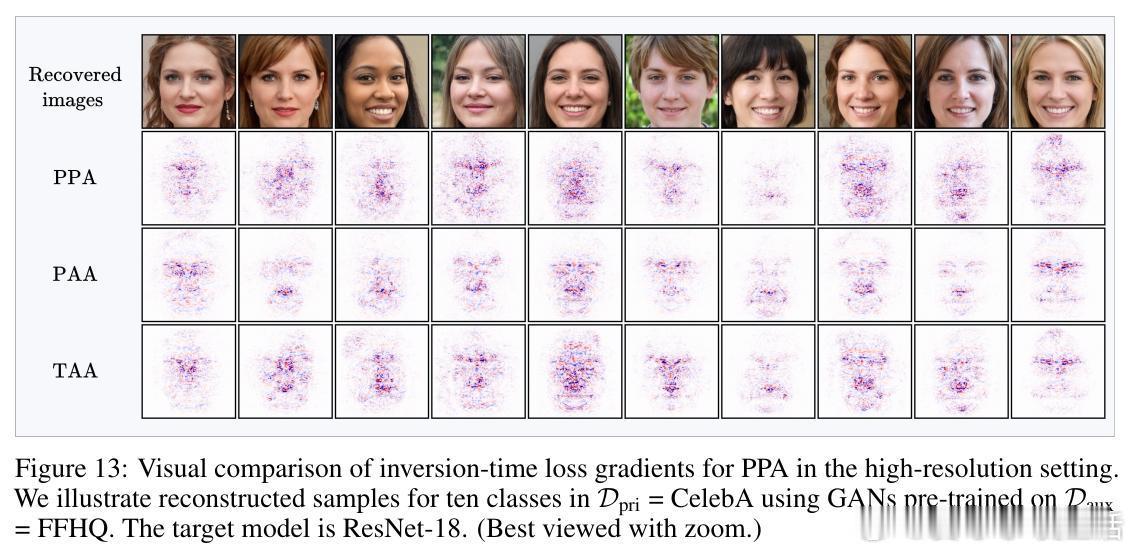
• 创新提出AlignMI训练无关方法,通过在合成输入局部邻域采样多样本并平均其损失梯度(PAA和TAA两种策略),进一步增强梯度与流形的对齐度,稳定提升多种先进反演攻击的效果。
• 大量实验证明,该几何视角不仅揭示了模型隐私泄露的新机制,还为设计更有效的攻击与防御策略提供了理论支撑和实践路径。
心得:
1. 反演攻击的成功关键在于梯度信息的几何结构,非单纯预测性能决定隐私风险。
2. 利用生成模型流形及其切空间的几何特性,可以在梯度层面做有效的噪声过滤与信息强化。
3. 训练与推理阶段均可通过提升梯度流形对齐度来调控攻击风险,提示未来防御应关注梯度的几何表现而非仅依赖传统正则化。
详细内容👉 arxiv.org/abs/2509.20177
生成模型模型反演攻击隐私安全流形假设深度学习安全对抗攻击