[CL]《rStar2-Agent: Agentic Reasoning Technical Report》N Shang, Y Liu, Y Zhu, L L Zhang... [Microsoft Research] (2025)
rStar2-Agent:引领前沿数学推理的仅14B规模智能体式强化学习模型
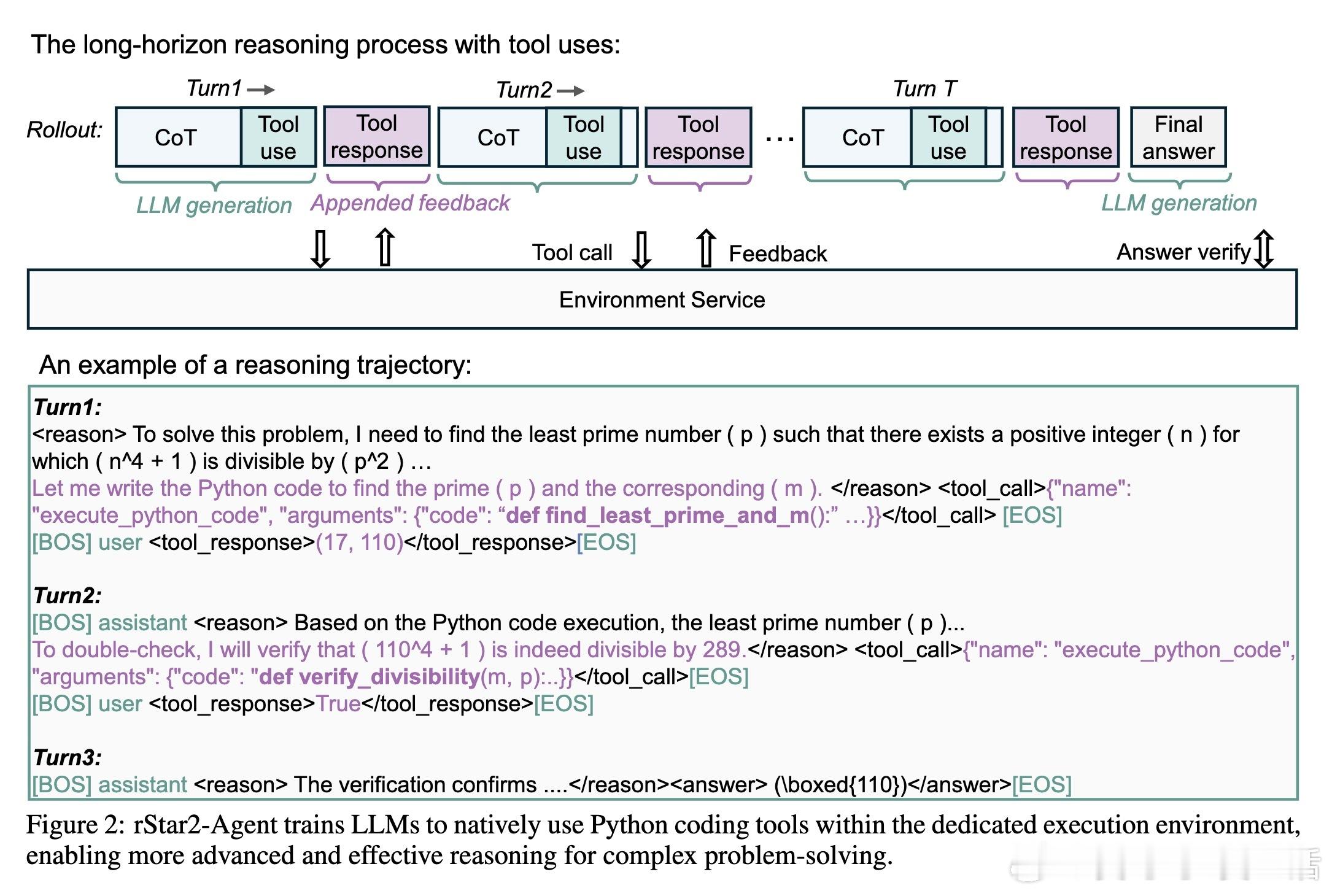
• 智能体强化学习突破“长思维链”瓶颈,具备自主探索、验证及反思的高级认知能力,能在Python代码环境中精准调用工具完成复杂数学推理。
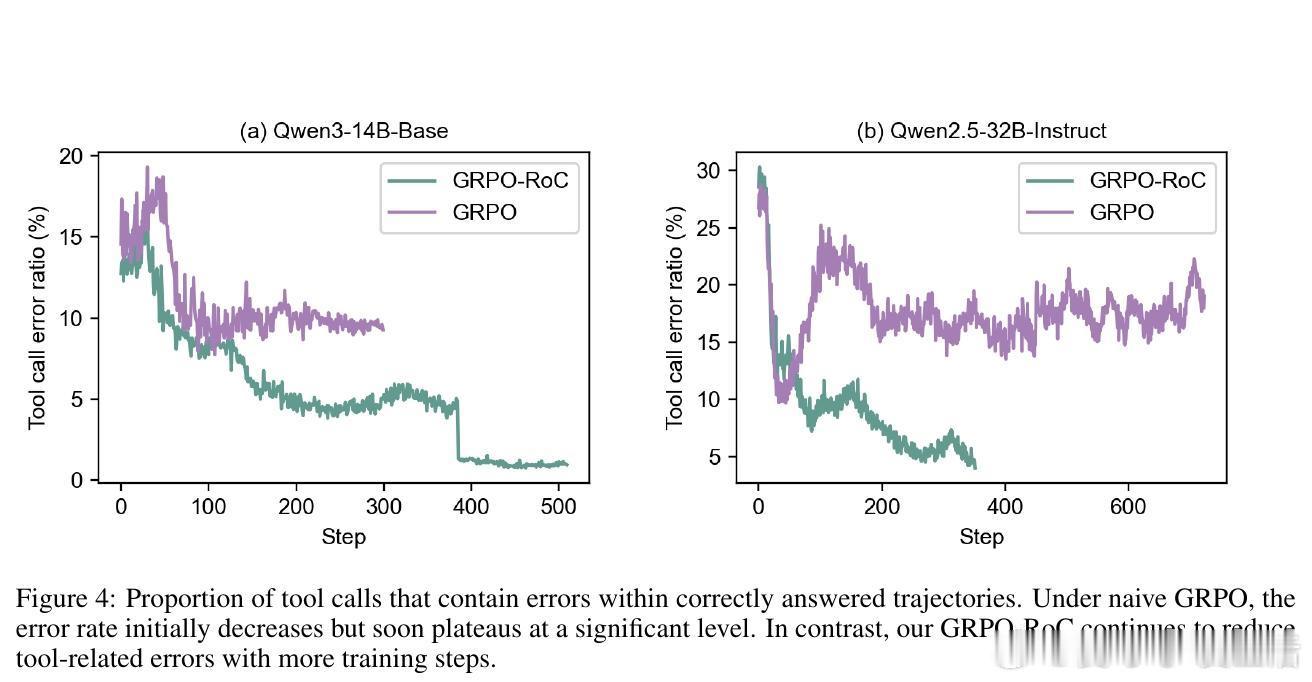
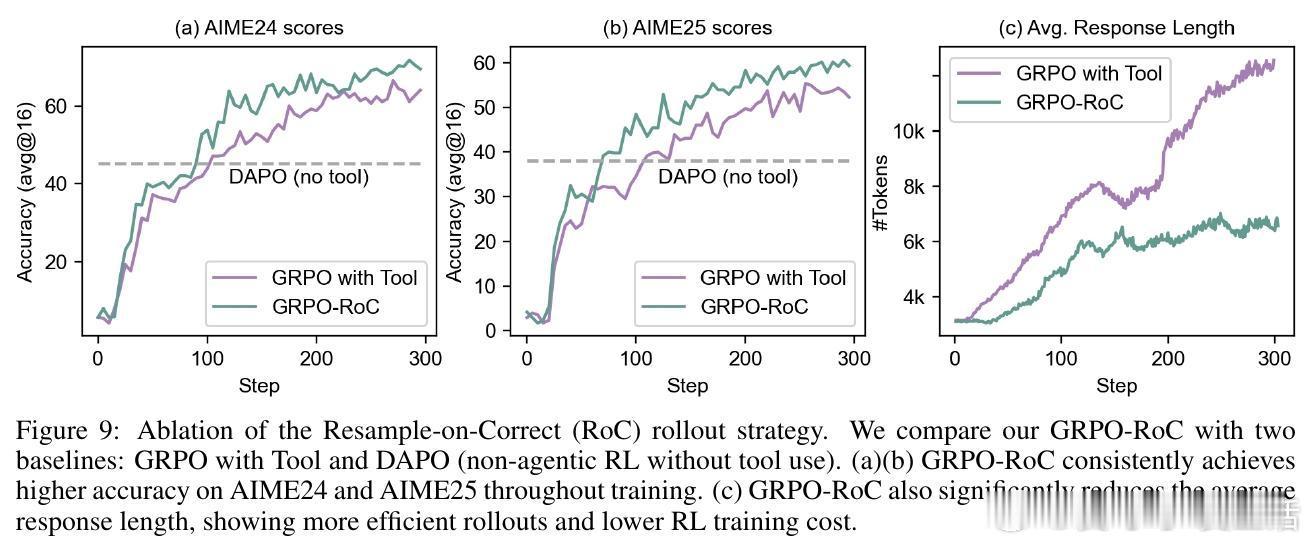
• 创新算法GRPO-RoC(Group Relative Policy Optimization with Resampling on Correct),采用“正确重采样”策略,有效过滤代码执行噪声,提升训练稳定性和推理质量。
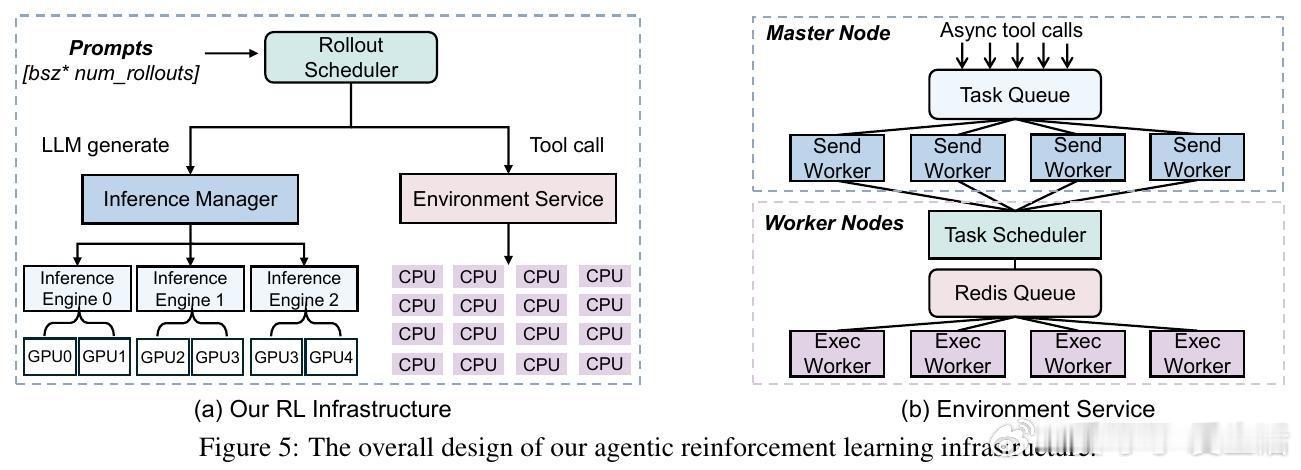
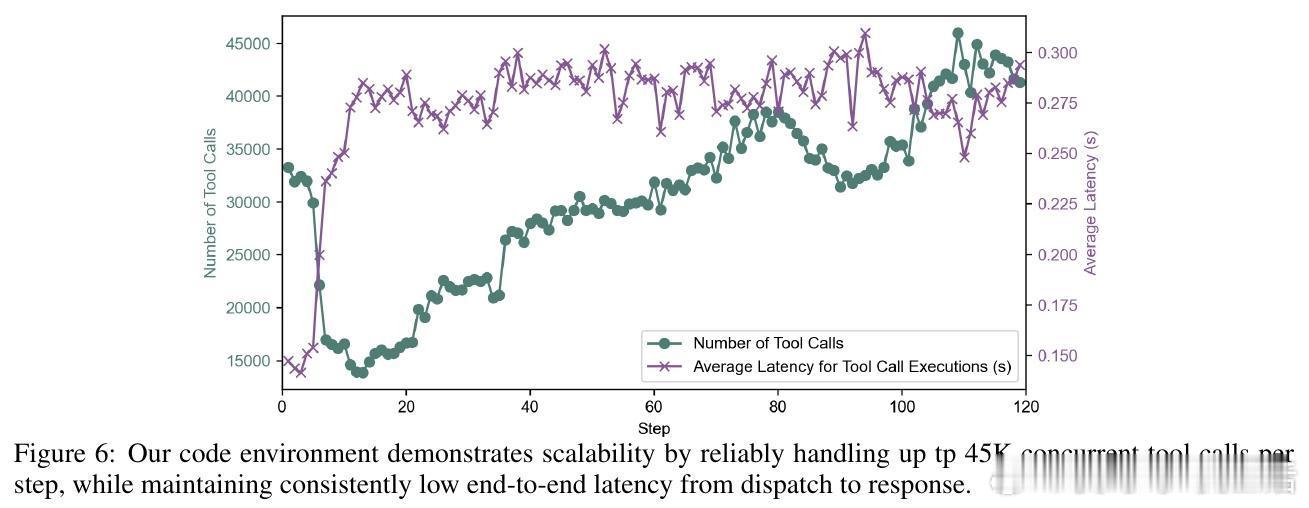
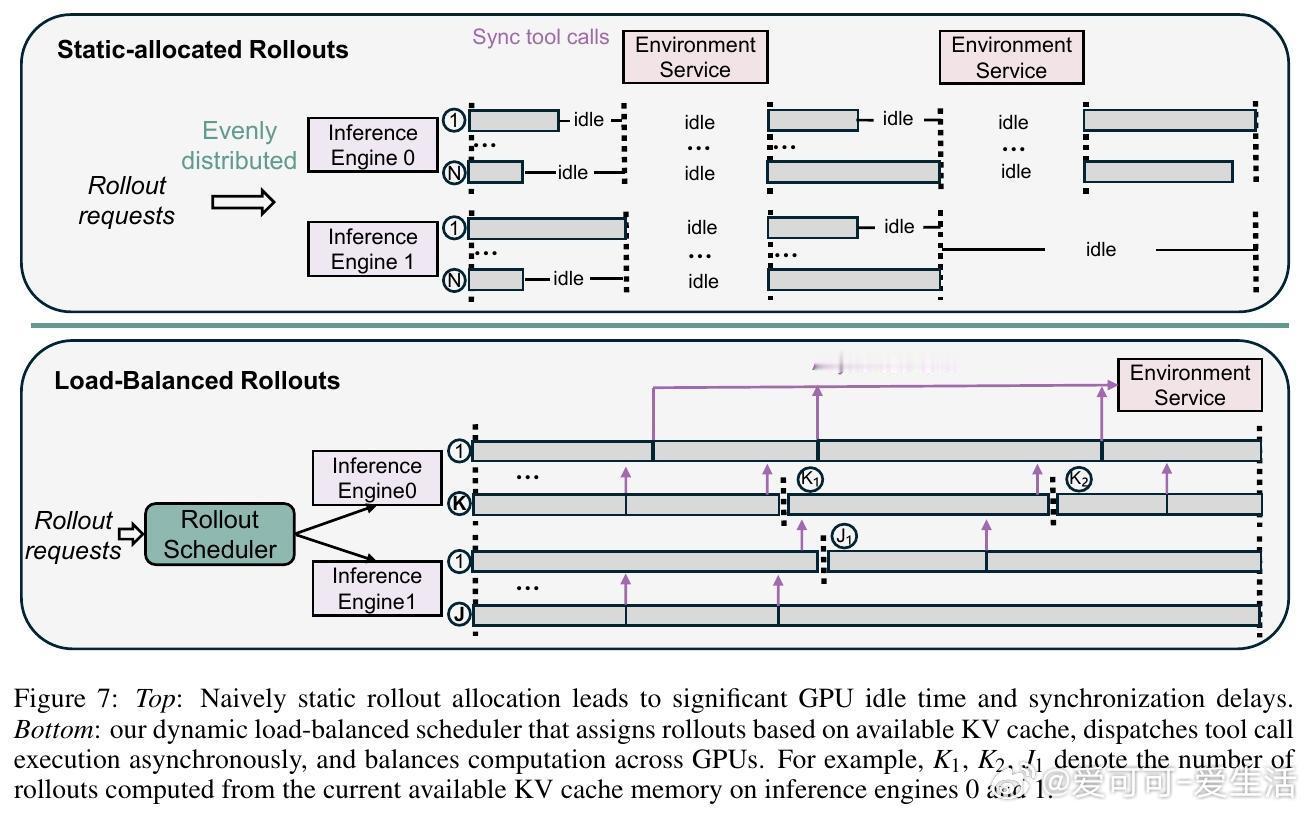
• 构建高吞吐隔离代码执行环境,支持4.5万并发工具调用,平均响应延迟仅0.3秒,结合动态负载均衡调度,极大提升训练效率,64颗MI300X GPU一周内完成训练。
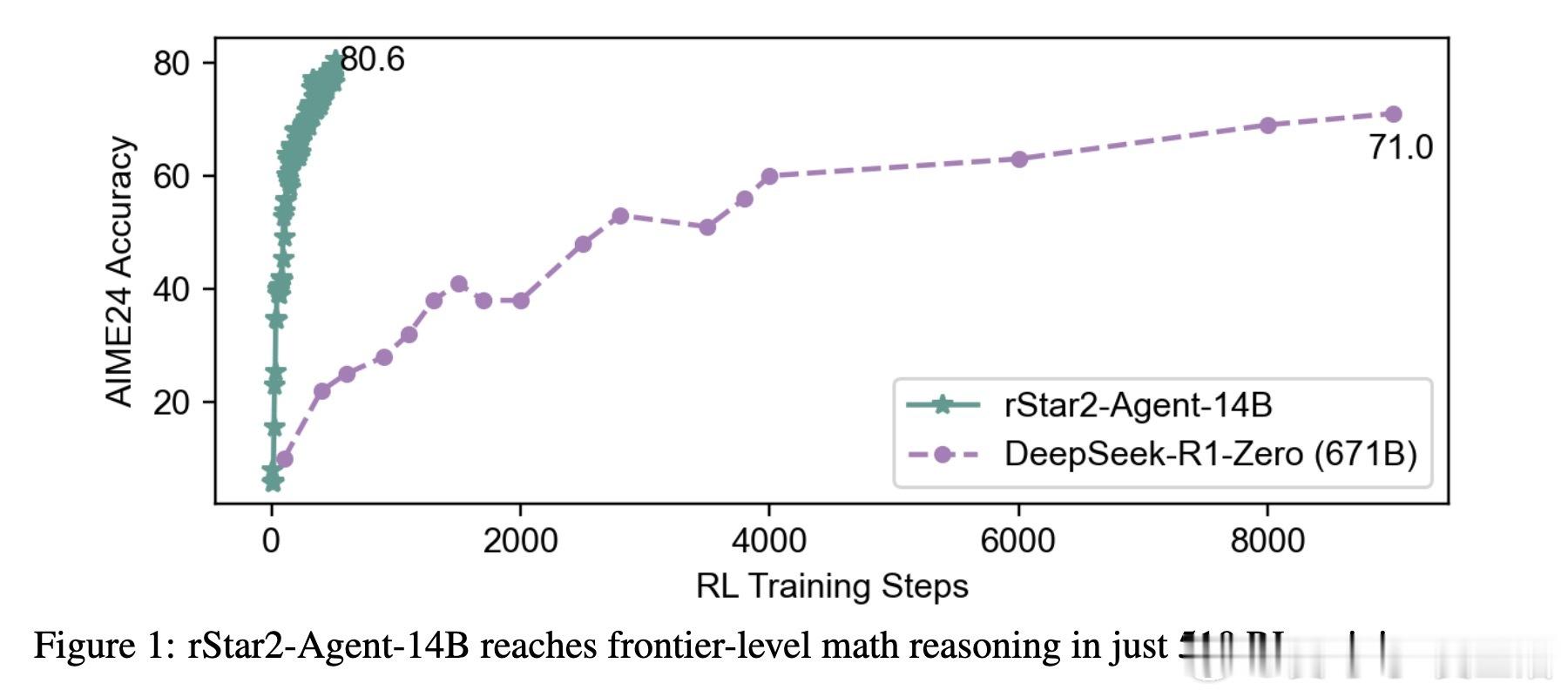
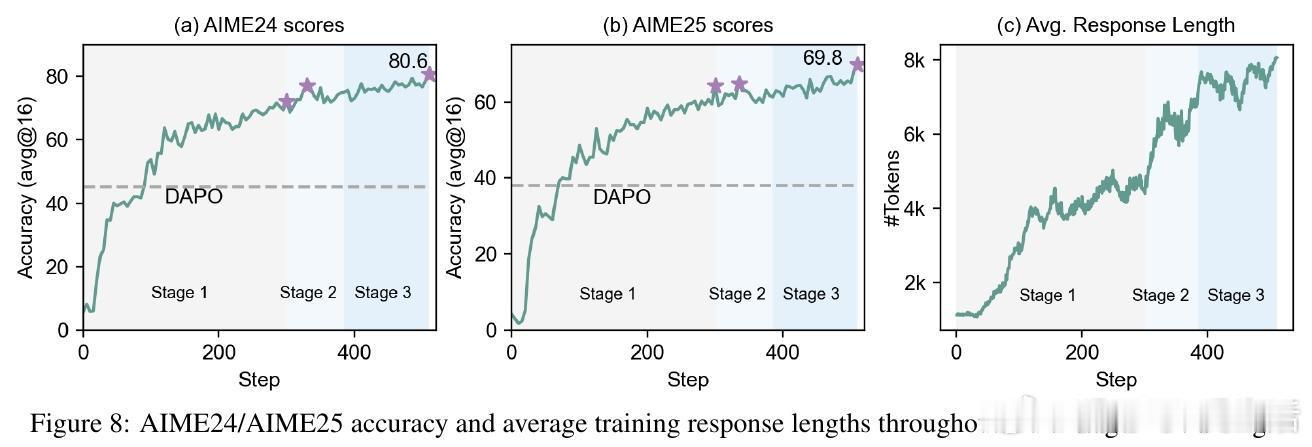
• 训练流程采用非推理冷启动SFT强化指令遵循和工具调用,再经多阶段强化学习逐步提升难度和响应长度,510步RL训练即达80.6% AIME24正确率,超越671B规模DeepSeek-R1且响应更短。
• 模型虽以数学专属强化学习训练,仍展现强泛化能力,科学推理、工具使用和通用对齐任务均表现优异。
心得:
1. 仅靠“思考更长”难解决复杂任务中隐蔽错误,自主利用外部工具反馈促进反思和自我修正是迈向更智能推理的关键。
2. 简洁的答案导向奖励配合重采样筛选机制,避免了复杂中间步骤奖励设计带来的偏差和探索受限。
3. 动态资源调度和隔离执行环境设计显著缓解了大规模agentic RL训练中的计算瓶颈与风险,实现成本效益极高的训练。
详见🔗arxiv.org/abs/2508.20722
强化学习智能体数学推理大规模模型代码执行认知AI