[IR]《On the Theoretical Limitations of Embedding-Based Retrieval》O Weller, M Boratko, I Naim, J Lee [Google DeepMind] (2025)
向量嵌入检索的理论极限已被系统揭示。新兴任务要求嵌入模型对任意查询及相关性定义均能准确响应,然而现有单向量嵌入范式存在无法突破的维度限制。
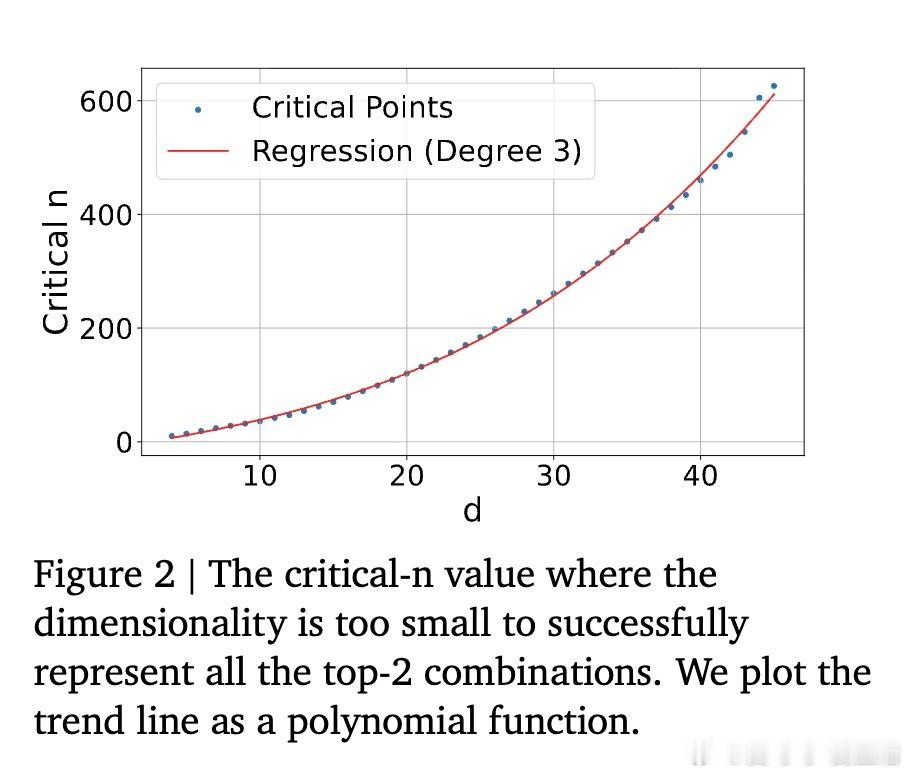
• 理论证明:嵌入维度d限制了模型能区分的top-k文档组合数量,存在维度阈值以下无法表示所有可能的相关文档集合。
• 实证验证:通过“自由嵌入”优化(直接调整嵌入向量以满足查询-文档相关矩阵)确认理论极限,发现即使k=2,维度不足时组合表现受限。
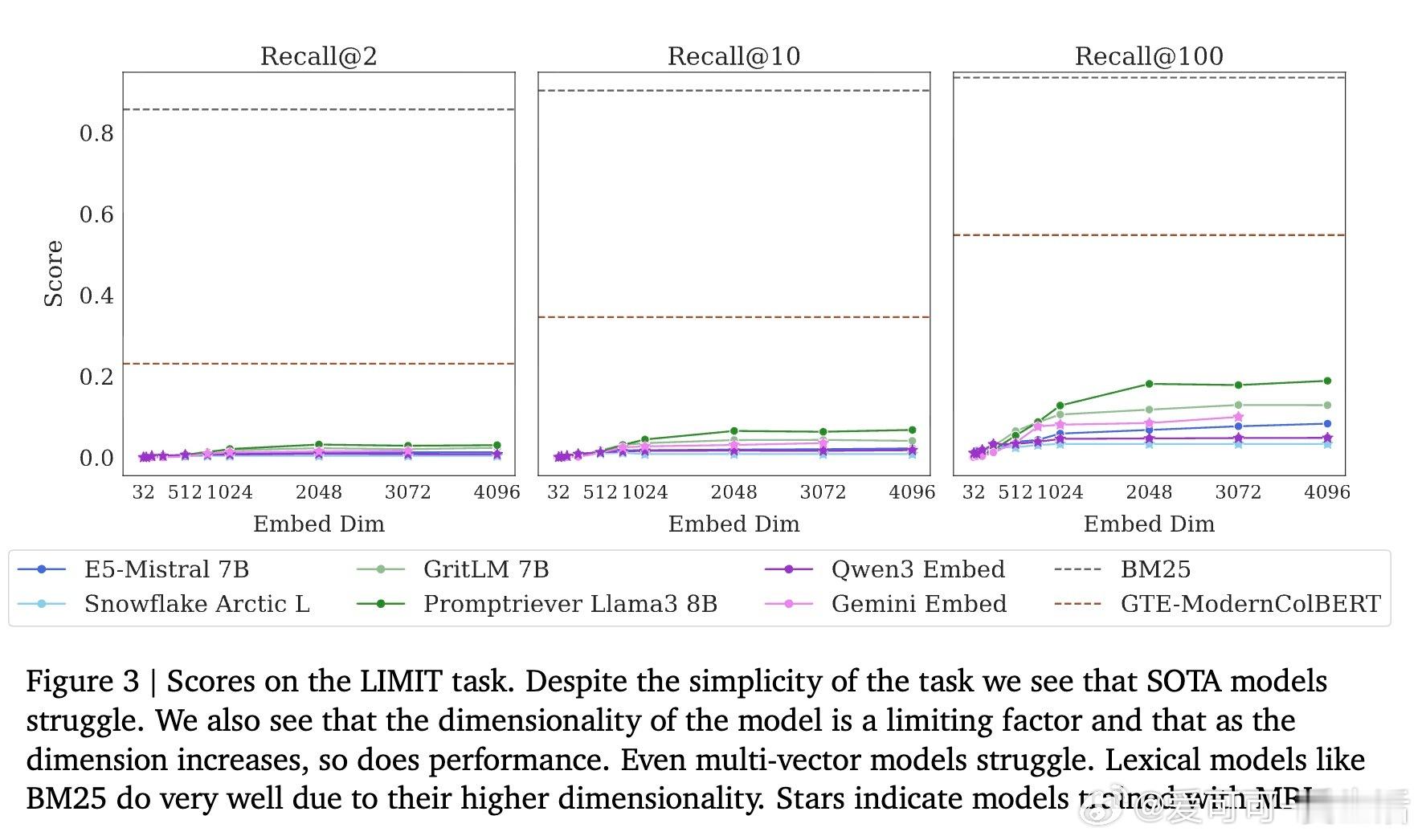
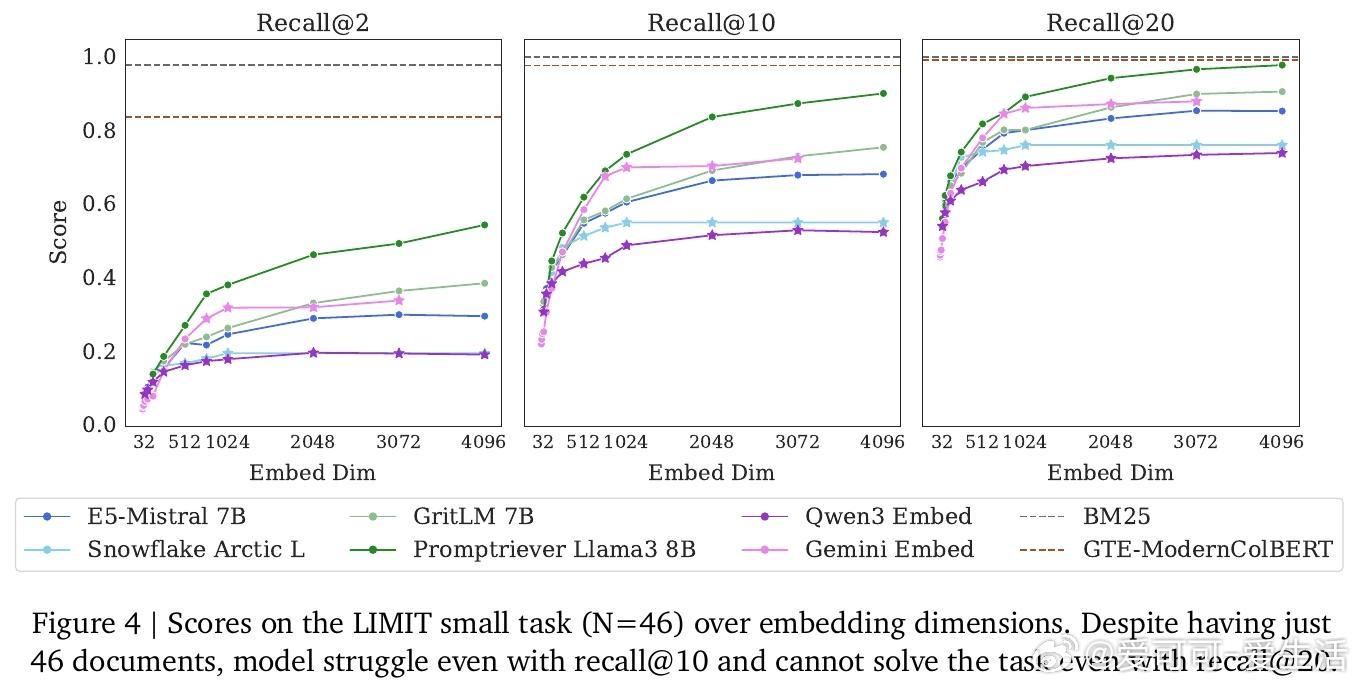
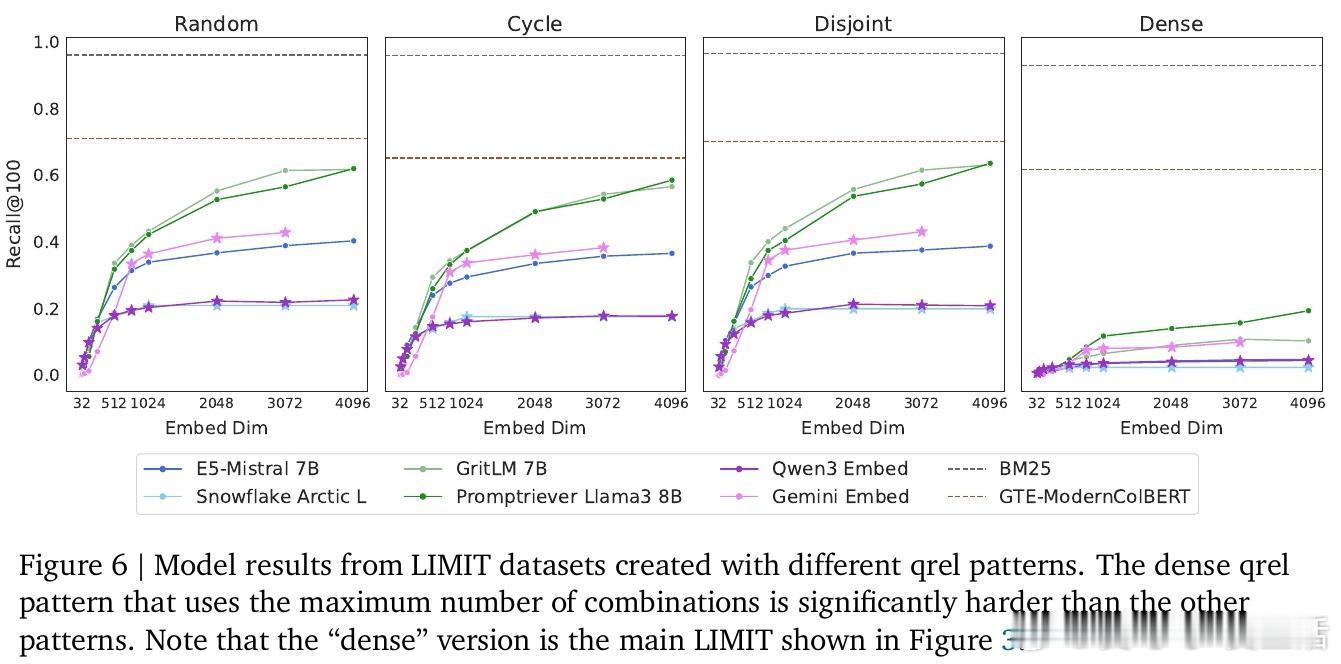
• LIMIT数据集:构建基于理论限制的简单自然语言任务,SOTA单向量模型在此数据集上的召回率低于20%,多向量及稀疏模型表现优于单向量但仍有限。
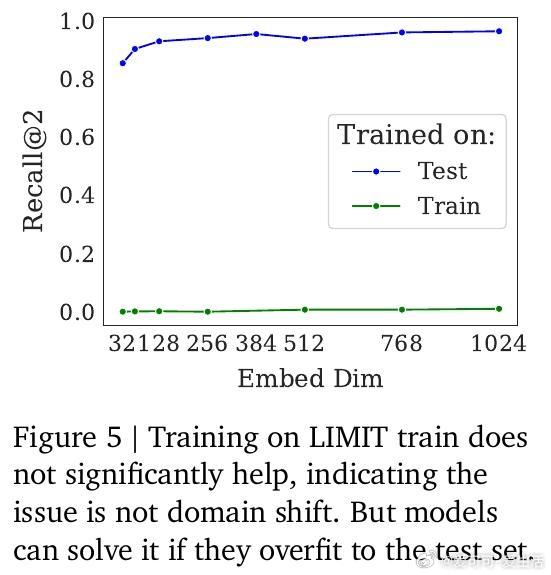
• 域迁移排除:训练集微调无明显提升,表明表现瓶颈非因域偏移。
• 替代方案:跨编码器(cross-encoders)与多向量模型显示出更强表达能力,尤其跨编码器可完美解决LIMIT小规模版本,但计算开销限制了大规模应用。
• 维度和组合数呈多项式关系,推断在实际网页规模(百万级文档)下,所需嵌入维度将极为庞大,难以实现。
心得:
1. 嵌入空间的维度决定了检索系统的表达上限,单向量模型无法无限扩展以应对复杂组合任务。
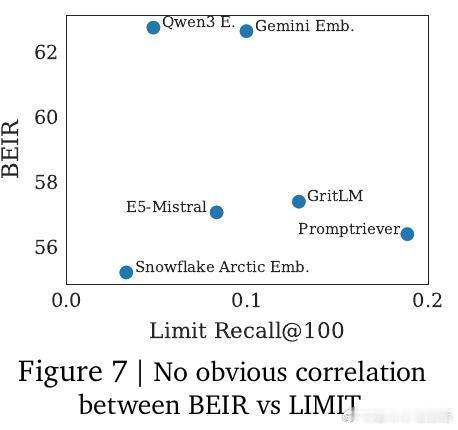
2. 现有评测多依赖有限查询样本,掩盖了嵌入模型在面对任意组合需求时的根本缺陷。
3. 探索多向量、稀疏表示及跨编码架构是绕过单向量限制的必由之路。
详见🔗arxiv.org/abs/2508.21038
信息检索向量嵌入理论计算机科学机器学习自然语言处理模型优化